使用免费工具优化无服务器应用程序
介绍
我最近在 AWS 上构建了一个无服务器应用程序,该应用程序与 Amazon QLDB 交互,后者是后端的专用数据库。在很多情况下,进行一些简单的配置更改就能显著提升性能。本文将介绍一些可用于优化您自己的无服务器应用程序的免费工具和服务。为了演示,我将重点介绍 QLDB,同时也会与 DynamoDB 进行简要比较。
使用以下工具:
- 火炮产生载荷
- 伪造者生成虚假数据
- 无服务器 Webpack捆绑模块
- Lumigo CLI提供了一系列有用的命令
- AWS Lambda Power Tuning实现最佳 Lambda 配置
- CloudWatch Log Insights查询日志组中的数据
- 用于分析服务调用的AWS X-Ray
QLDB Perf Test GitHub 存储库包含用于这些测试的代码。
建筑学
性能测试演示应用程序具有以下架构:

它使用无服务器框架进行配置,以确保所有内容都作为代码在一个 CloudFormation 堆栈中进行管理,并且可以随时部署或删除。
部署
要部署堆栈,请运行以下命令:
sls deploy
文件中的此resources部分serverless.yml包含原始 CloudFormation 模板语法。这允许您创建 DynamoDB 表以及描述表和索引的键架构以及构成主键的属性。QLDB 完全无架构,并且不支持 CloudFormation 创建表或索引。这可以使用自定义资源来完成。但是,对于此测试,我只是登录控制台并运行了以下 PartiQL 命令:
CREATE TABLE Person
CREATE INDEX ON Person (GovId)
创建测试数据
下一步是使用Faker和创建测试数据Artillery。第一步是创建一个简单的脚本,用于向 QLDB 表中添加新的 Person(并为 DynamoDB 创建单独的脚本)。脚本本身如下所示:
config:
target: "{url}"
phases:
- duration: 300
arrivalRate: 10
processor: "./createTestPerson.js"
scenarios:
- flow:
# call createTestPerson() to create variables
- function: "createTestPerson"
- post:
url: "/qldb/"
json:
GovId: "{{ govid }}"
FirstName: "{{ firstName }}"
LastName: "{{ lastName }}"
DOB: "{{ dob }}"
GovIdType: "{{ govIdType }}"
Address: "{{ address }}"
此config部分定义了目标。这是部署堆栈时返回的 URL。它config.phases允许定义更复杂的加载阶段,但我进行了一个简单的测试,每秒创建 10 个虚拟用户,总共持续 5 分钟。config.processor属性指向用于运行自定义代码的 JavaScript 文件。
该scenarios部分定义了由 创建的虚拟用户Artillery将执行的操作。在上面的例子中,它使用从createTestPerson函数中检索到的变量来生成一个 HTTP POST 请求,其 JSON 主体部分由该函数生成。这是一个在 JavaScript 文件中导出的模块,如下所示:
function createTestPerson(userContext, events, done) {
// generate data with Faker:
const firstName = `${Faker.name.firstName()}`;
...
// add variables to virtual user's context:
userContext.vars.firstName = firstName;
...
return done();
}
module.exports = {
createTestPerson
};
在git仓库中,定义了以下脚本:
- 创建-qldb-person.yml
- 创建-dynamodb-person.yml
- 获取-qldb-person.yml
- 获取 dynamodb-person.yml
还有一些node脚本可以在本地运行,以填充用于负载测试查询的 CSV 文件。可以使用以下命令运行这些脚本:
node getQLDBPerson > qldbusers.csv
node getDynamoDBPerson > dynamodbusers.csv
运行基线测试
首先,我使用以下命令运行了基线测试,在 5 分钟内创建了 3000 条新记录:
artillery run create-qldb-person.yml
输出显示记录已成功创建,但没有性能信息。幸运的是,所有 Lambda 函数都会通过 Amazon CloudWatch 报告指标。每次调用 Lambda 函数都会提供有关实际持续时间、计费持续时间和内存使用量的详细信息。您可以使用 CloudWatch Log Insights 快速创建相关报告。以下是我在 Log Insights 中运行的查询,以及生成的报告:
filter @type = "REPORT"
| stats avg(@duration), max(@duration), min(@duration), pct(@duration, 95)
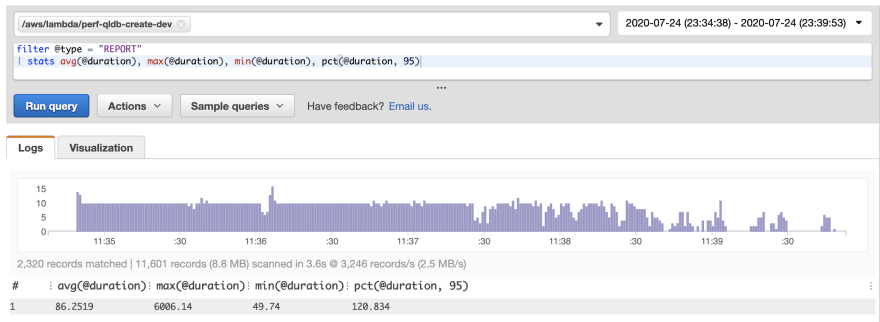
运行基线测试查询数据产生了大致相似的结果:

启用 HTTP 保持活动
使用 Nodejs 的第一个优化是显式启用 keep-alive。可以使用以下环境变量在所有函数中执行此操作:
environment:
AWS_NODEJS_CONNECTION_REUSE_ENABLED : "1"
这是由Yan Cui首次撰写的,似乎是 AWS SDK for Node 所独有的,它默认每次都会创建一个新的 TCP 连接。
再次运行测试,发现性能有了显著的提高:
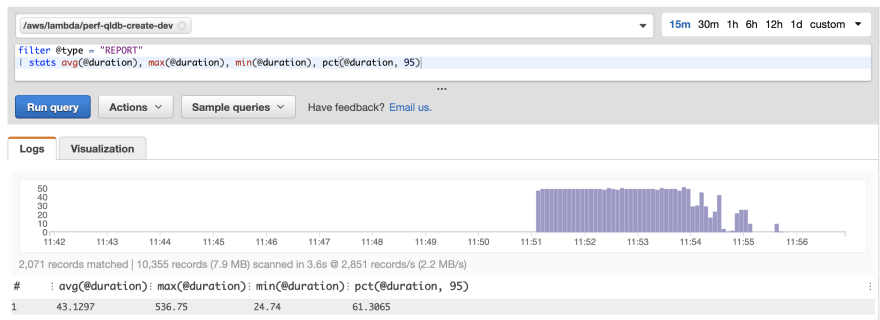

平均响应时间大约减少了一半。P95 值也同样如此。对于这些请求,Lambda 调用的成本也减少了一半。这是因为 Lambda 的定价是按 100 毫秒计算的。
使用 Webpack 构建函数
下一个优化是查看冷启动时间。当堆栈首次部署时,我们在运行时看到artefact输出的大小sls deploy:
Serverless: Uploading service qldb-perf-demo.zip file to S3 (10.18 MB)...
另一个很棒的工具是lumigo-cli。它有一个命令可以用来分析 Lambda 函数的冷启动时间。我运行了以下命令来分析过去 30 分钟内特定 Lambda 函数的所有冷启动:
lumigo-cli analyze-lambda-cold-starts -m 30 -n perf-qldb-get-dev -r eu-west-1
这产生了以下输出:

为了优化冷启动时间,我使用 Webpack 作为 JavaScript 的静态模块打包器。它的工作原理是:检查你的包并创建一个新的依赖关系图,该图会提取出所需的模块。然后,它会创建一个仅包含这些文件的新包。这种摇树优化可以显著减少包的大小。Lambda 函数的冷启动需要下载部署包并在调用前将其解压。减小的包大小可以缩短冷启动时间。
我使用了该serverless-webpack插件并将以下内容添加到serverless.yml文件中:
custom:
webpack:
webpackConfig: 'webpack.config.js'
includeModules: false
packager: 'npm'
然后我创建了webpack.config.js指定 lambda 函数入口点的文件:
module.exports = {
entry: {
'functions/perf-qldb-create': './functions/perf-qldb-create.js',
'functions/perf-qldb-get': './functions/perf-qldb-get.js',
'functions/perf-dynamodb-create': './functions/perf-dynamodb-create.js',
'functions/perf-dynamodb-get': './functions/perf-dynamodb-get.js',
},
mode: 'production',
target: 'node'
}
重新部署堆栈时可以看到使用 webpack 捆绑部署包的影响:
Serverless: Uploading service qldb-perf-demo.zip file to S3 (1.91 MB)...
我们几乎不费吹灰之力就将软件包体积缩减了 80% 以上。重新运行负载测试并使用 lumigo-cli 分析冷启动结果如下:

这使得冷启动的初始化时间减少了 200 毫秒,降幅达 40%。
优化 Lambda 配置
最后的检查使用了Alex CasalboniAWS Lambda Power Tuning开发的出色开源工具。它使用您账户中的 Step Functions 来测试不同的内存/电源配置。这需要传入事件负载。我使用以下日志语句打印出 lambda 函数中传入请求的事件消息。
console.log(`** PRINT MSG: ${JSON.stringify(event, null, 2)}`);
然后,我将事件消息复制到名为的文件中qldb-data.json,并运行以下命令:
lumigo-cli powertune-lambda -f qldb-data.json -n perf-qldb-get-dev -o qldb-output.json -r eu-west-1 -s balanced
这产生了以下可视化效果:
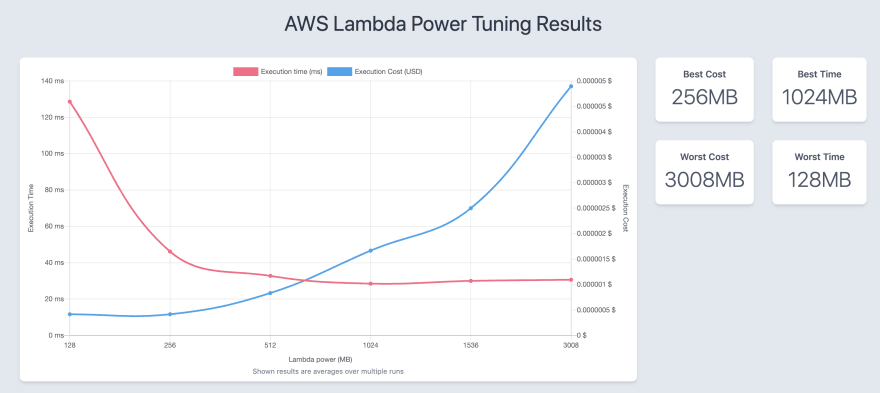
在这种情况下,从成本和性能之间的权衡来看,512MB 的内存分配效果最佳。
DynamoDB 比较
DynamoDB 也使用了相同的工具来优化其开箱即用的性能,并获得了类似的改进。显著的区别在于,创建和获取操作的平均延迟均为个位数毫秒,如下所示:
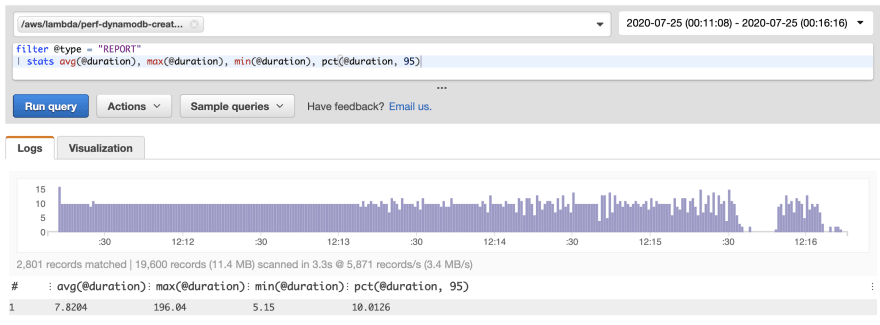

值得注意的是,平均冷启动时间(尽管数据集最少)比 QLDB 少约 40%。

某些服务还可以分析其他指标。例如,DynamoDB 在控制台中提供了丰富的指标,例如读写容量、受限制的请求和事件以及延迟。结合使用 等工具可以访问Artillery这些Faker指标,从而进一步优化性能。下图显示了 DynamoDB 在一次测试运行的 5 分钟内消耗的写入容量单位。

但在得出结论之前,还值得使用另一个名为 AWS X-Ray 的工具来了解服务调用期间发生的情况。
AWS X-Ray
AWS X-Ray 用于跟踪通过应用程序的请求。为了跟踪 AWS 服务的延迟,X-Ray SDK 可以通过一行代码自动检测:
const AWSXRay = require('aws-xray-sdk-core');
const AWS = AWSXRay.captureAWS(require('aws-sdk'));
您访问的跟踪 AWS 服务和资源在 X-Ray 控制台的服务地图上显示为下游节点。从 QLDB 获取数据的 Lambda 函数的服务地图如下所示:

最引人注目的观察结果是,每个请求都会导致对 QLDB Session 对象的 4 次调用。您可以通过分析单个请求的跟踪详情来更详细地了解这一点。之所以选择下面的跟踪详情,是因为它不仅显示了 4 次SendCommand调用,而且其Initialization值还表明这是一次冷启动。
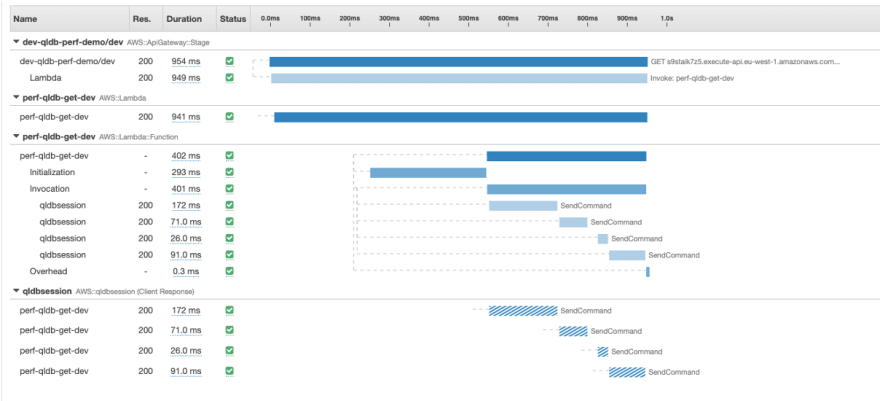
QLDB Session所有与 QLDB 的交互均使用 QLDB 驱动程序进行,该驱动程序在数据平面之上提供了一个高级抽象层,并为您管理 API 调用。这包括对、和 的SendCommand必要调用。这是因为 QLDB 事务符合 ACID 标准,并具有完全可序列化性——最高级别的隔离性。QLDB 本身采用日志优先架构实现,任何记录的更新都必须先经过日志,并且日志仅包含已提交的事务。SendCommandStartTransactionExecuteStatementCommitTransaction
您可以随时将账本的日志区块导出到 S3。以下是我导出账本时截取的日志区块示例:
{
blockAddress: {
strandId:"Djg2uUFY81k7RF3W6Kjk0Q",
sequenceNo:34494
},
transactionId:"BvtWxFcAprL46H8SUO4UNB",
blockTimestamp:2020-07-29T14:36:46.878Z,
blockHash:{{VWrBpXNsFqrakqlyqCYIQA85fVihifAC8n4NjRHQF1c=}},
entriesHash:{{dNkwEyOukyqquu0qGN1Va+M/wZoM6ydpeVym2SjPYHQ=}},
previousBlockHash:{{ZjoCeXoOtZe/APVp2jAuKILnzPfXNIIDxAW8BHQ6L0g=}},
entriesHashList:[{{f+ABhLyvVPWxQpTUIdCInfBxf/VeYUAqXgfbhVLn/hI=}},
{{}},
{{ExVOMej9pEys3rU1MEZyNtHaSSt5KnaFvFQYL3qPO2w=}}],
transactionInfo: {
statements:[{
statement:"SELECT * FROM Person AS b WHERE b.GovId = ?",
startTime:2020-07-29T14:36:46.814Z,
statementDigest:{{scNEggVYz4buMxYEBvIhYF8N23+0p2huMD37bCaoKjE=}}
}]
}
}
{
blockAddress: {
strandId:"Djg2uUFY81k7RF3W6Kjk0Q",
sequenceNo:34495
},
transactionId:"IyNXk5JJyb5L8zFYifJ7lu",
blockTimestamp:2020-07-29T14:36:46.879Z,
blockHash:{{QW6OILb/v7jwHtPhCxj4bh0pLlwL7PqNKfi7AmNZntE=}},
...
这表明,即使对账本执行查询语句,它也发生在交易中,并且该交易的详细信息将作为新的日志区块提交。由于没有数据更新,因此该区块没有关联的文档修订。指定区块位置的序列号将递增。提交交易时,将计算 SHA-256 哈希并将其存储为区块的一部分。每次添加新区块时,该区块的哈希都会与前一个区块的哈希合并(哈希链)。
结论
本文介绍了如何使用一些免费工具和服务来优化您的无服务器应用程序。从与 QLDB 交互的基准测试来看,我们得到了以下结果:
- 平均响应时间缩短约 50%
- 减少冷启动开销约 40%
- 封装尺寸减少约 80%
- 为我们的 Lambda 函数选择最合适的内存大小
我们最终实现了 QLDB 插入和查询的响应时间约为 40 毫秒。这还为我们提供了完全可序列化的事务支持、日志中仅包含已提交数据的保证、不可变数据,以及能够以加密方式验证可追溯至任何时间点的记录状态以满足审计和合规性要求的能力。所有这些功能均通过完全无模式和无服务器的数据库引擎开箱即用,我们无需自行配置 VPC。
本文使用 DynamoDB 是为了演示这些工具如何优化与任何服务交互的 Lamda 函数。然而,这也强调了选择合适的服务以满足您的需求至关重要。QLDB 的设计目标并非像 DynamoDB 那样提供个位数毫秒的延迟。但是,如果您确实有复杂的需求,涵盖审计和合规性、维护事实来源,以及支持低延迟读取和复杂搜索,您可以随时将数据从 QLDB 流式传输到其他专用数据库中,正如我在本篇博文中所示。
文章来源:https://dev.to/aws-heroes/using-free-tools-to-optimise-a-serverless-application-47ee