分布式系统中的分区解析
说到科技术语,似乎有一件事始终成立:每个人对某些词语的含义都有不同的看法。我偶尔也会意识到这一点;最近,我在学习一个新的分布式系统概念时就遇到了这个问题。
“分区”这个术语在分布式系统课程和书籍中被广泛使用,但也有许多其他术语被归入这一类别。直到最近,我才明白这个术语在分布式系统中的含义,但事实证明,它的故事——以及这个词——比我想象的要深奥得多!随着我做了更多的研究,我意识到这个术语指的是两个截然不同的概念,而这两个概念对于理解如何处理和构建分布式系统都至关重要。
正如理查德·费曼曾经说过的:“名称不构成知识”。仅仅因为业内人士随意使用某个术语,并不意味着他们一定都知道它的含义,或者它是如何根据上下文发生变化的!所以,让我们尝试澄清一些困惑,并就此话题获得一些真正的知识。
解析分区的含义
在深入探讨系统分区之前,我们先来确认一下我们对“分区”一词的含义是否一致!当我们谈论分区时,实际上是在把它分割、分解成各个部分,然后分离。

分区的核心就是:将一个整体拆分成更小的部分。目前为止,还不算太复杂,对吧?但在分布式系统中,这个术语意味着什么呢?我们可以推断,分布式系统在某种程度上必须是被我们分离、划分并分解成更小部分的“整体”。
但这个简单的操作实际上可以采取两种不同的形式,具体取决于我们创建的分区类型。众所周知,分布式系统由节点组成;因此,如果我们将系统划分为多个部分,也许我们是在划分节点?但这里“分区”还有另一种解释。与其划分节点,不如将系统划分为更小的节点组,从而将一个大型系统分解成更小的子系统。仔细想想,这两种方法都是有效的分区形式。
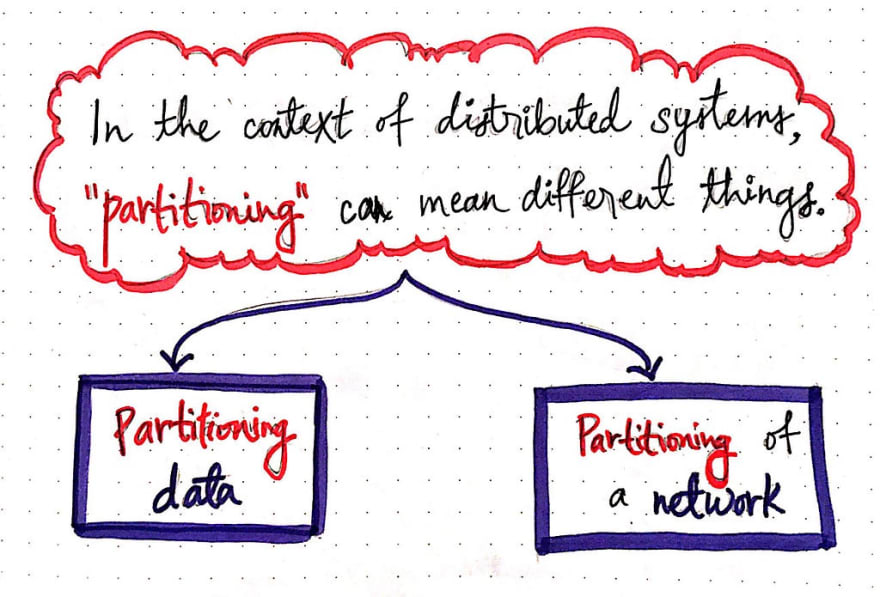
事实证明,这正是容易让人困惑的地方。在处理分布式系统时,“分区”可能意味着不同的含义。首先,它可能意味着对系统中的数据进行分区,或者将节点划分成更小的部分。但它也可能意味着通过对系统通信网络进行分区来对系统本身进行分区。这意味着打破系统中节点之间的通信方式,将它们划分成更小的子系统或子网。
系统中这两种分区形式的有趣之处在于,一种是故意为之,而另一种则更像是我们需要处理的副作用。稍后我会对此进行更详细的介绍。理解两者之间的区别非常重要,因为有时同一个术语可以用来指代两者!所以,让我们深入研究这两种分区形式,并理解它们背后的原因。
分离数据
对系统中的节点进行分区的想法乍一看可能有点奇怪,但我们之前确实见过类似的东西。还记得我们学习过冗余和节点复制吗?这个概念乍一看可能也很奇怪——为什么有人会想重复自己?!——但随着我们进一步深入研究,我们发现它有一些明显的好处。
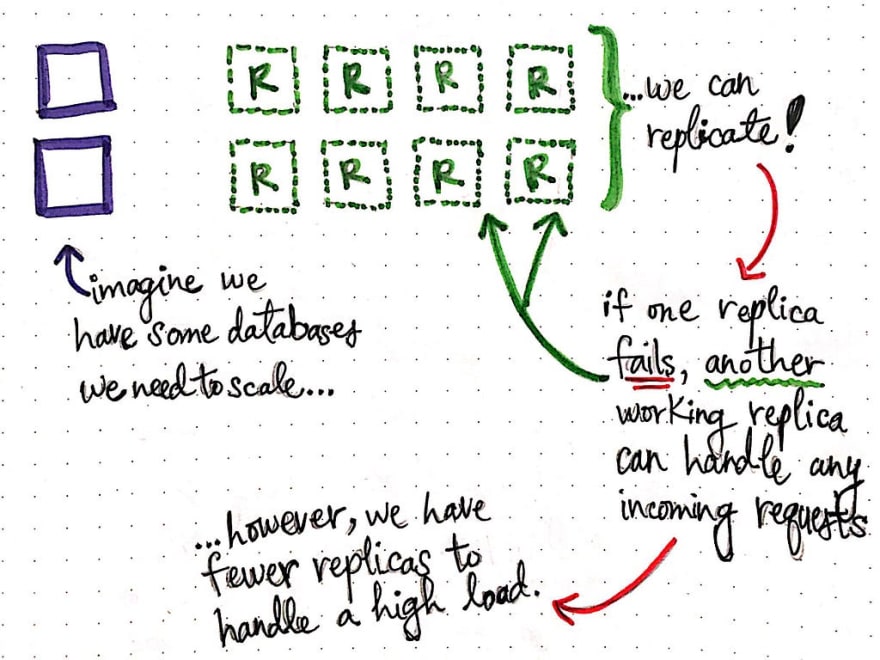
正如我们已经了解的,当我们需要提高某些节点的可靠性,或者需要扩展系统的某些部分(例如数据库)时,我们可以复制节点,创建更多与原始节点同步的相同数据的副本。这样,如果一个副本发生故障,另一个正常工作的副本可以处理部分数据的传入请求。总而言之,复制可以使系统更加透明、可靠,并且更易于扩展。
然而,复制也有一些需要注意的地方。我们已经知道,保持副本的一致性是一项重大挑战。但如果我们的副本突然需要处理大量的传入请求,会发生什么情况?很有可能一些副本会失败,任何依赖于该副本的用户都可能无法访问该副本上的任何数据(至少在另一个副本能够取代它之前)。
这给复制带来了新的挑战:虽然大多数用户可以通过工作副本访问我们的所有数据,但对于一部分用户来说,如果这些用户正在访问的副本发生故障,我们的所有数据可能完全不可用。
但是,如果我们有一个非常大的数据集怎么办?一个让我们在复制之前三思而后行的数据集呢?这时我们可能需要采用不同的策略……比如对数据进行分区!

在某些情况下,数据集太大而无法全部放在单个节点上,我们可以选择对数据进行分区。
跨节点分区数据意味着我们的数据分布在各个节点上;没有哪个节点能够容纳所有数据。相反,如果我们想要检索所有数据,就需要访问每个节点。
根据数据集的形态以及数据之间的关联性,将某些类型的数据集中到单个节点可能更合理。例如,在一个显示帖子及其相关评论的系统中,将帖子及其所有评论的数据始终放在同一个节点上可能更合乎逻辑,这样用户就无需分别在两个不同的节点发出请求来获取两种类型的数据。
有很多策略可以确定哪些数据应该存储在哪个节点上。我们可能会遇到两个术语来描述这个想法:分片 (sharding)和碎片 (fragmentation)。这两个术语可以互换使用,用来描述将数据集划分到多个不同节点上的想法(本文不会详细介绍这些技术的实际实现)。

这里需要注意的是,每当我们看到“分片”或“碎片化”这些术语时,通常指的是分区数据库(因为数据库通常是数据集的存储地!)。数据库通常位于多台服务器上,并且本身是分布式的(很简洁吧?)。因此,当我们遇到数据库碎片化并将其拆分成多个分片的情况时,我们实际上处理的是一个被拆分成多个分片(或更小的集合/碎片)并分布在各个节点上的大型数据集。
单个数据库节点仅包含较大数据集的一部分。当添加更多数据或数据集发生重大变化时,可能需要将其重新分区到所有节点上的新分片中。

那么这与我们的复制思维模型有什么关系呢?
首先,需要注意一个重要的相似之处:分区和复制都能提升系统的性能和可靠性。这仅仅是因为拥有更多节点——无论是包含所有相同数据的副本,还是包含部分数据的分区——都意味着单个节点的负载会减少!当我们添加更多副本或分区时,我们可以有效地分散传入的数据请求,这有助于我们的系统扩展,并使其性能更高,更易于最终用户使用。
但是这两种策略之间有什么区别呢?复制保证我们的最终用户始终可以读取整个数据集,因为所有数据都存储在每个副本上。另一方面,分区保证部分数据可检索,但无法保证我们的最终用户在某个分区发生故障时始终能够检索到他们需要的数据!
复制和分区之间的另一个区别是使它们变得困难的事情!复制很难,因为维护副本之间的一致性很棘手。分区很难,有两个原因:首先,如果我们的数据集发生变化,我们需要突然重新分区……这可不是一件容易的事。决定如何划分数据需要时间和精力,我们绝对不想一直重新分区!其次,根据实现方式,它有时可能无效。例如,如果我们将一些使用率很高的数据分区到一个节点,那么我们最终的情况实际上比分区前更糟糕。这是为什么呢?
想象一下,所有终端用户突然同时请求那些高使用率的数据,而节点无法承受如此高的负载?或者,如果那个存储高使用率数据的数据库节点发生故障,该怎么办?现在,我们的终端用户将无法访问这个重要的分区!因此,在权衡这两种策略时,我们必须考虑所有这些潜在的弊端。为了避免做出这些决定带来的一些麻烦,许多生产级分布式系统会尽可能使用复制,并且仅在必要时选择分区。
划分网络
现在我们已经了解了数据分区的来龙去脉,还有最后一件事要解开:网络分区背后的理念。不过,别太害怕,这对我们来说并不是一个全新的话题。事实上,我可以告诉你一个小秘密——我们已经见识过网络分区的影响了!
在本系列文章中,我们了解了各种 不同的故障模式,而事实证明,网络分区实际上只是分布式系统中的一种故障形式。当网络被分割成多个碎片,并在其内部创建子网络时,就会发生网络分区故障。这里需要强调的是,网络故障(也称为网络分裂)会中断网络中节点之间的正常通信。

然而,这并不意味着网络中的所有节点都无法通信;唯一无法相互通信的是分叉周围的节点。这意味着,如果两个节点之间发生网络分叉,这两个节点将无法相互通信,但它们可以继续与未受分叉影响的其他节点通信。
当节点连接因网络故障而中断时,它会创建子网络,这些子网络是较大网络的“分区”——如果你愿意的话,可以将其称为网络的无意划分。

例如,如图所示,网络故障导致了网络分区(也称为碎片化)。碎片化迫使我们的网络被划分为两个子网,我们分别将其命名为 A 和 B。子网 A 中的节点可以继续相互通信,子网 B 中的节点可以继续处理数据并在彼此之间发送信息。然而,子网 A 和 B 之间的任何节点都已碎片化,这意味着它们无法相互通信!这意味着子网 A 无法与子网 B 通信,甚至无法了解子网 B 的状态(反之亦然)。
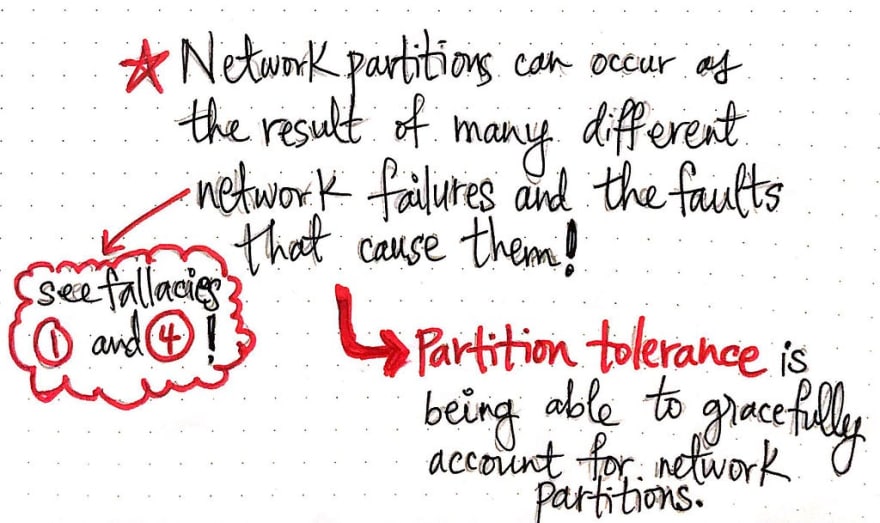
现在,如果这种情况听起来很糟糕,那你就对了——确实很糟糕!我们不希望网络随机中断,导致系统各部分彼此隔离。显然,网络分区是应该避免的。但是,你还记得我们之前学习过的分布式计算的 8 个谬误吗?如果我们回想一下谬误 1(“网络是可靠的。”)和谬误 4(“网络是安全的。”),我们就会直面一个残酷的事实:网络分区是不可避免的。
那么我们能做什么呢?好吧,我们可以设计我们的系统,当它们(不可避免地)发生时,尝试优雅地处理它们!这类似于我们在学习容错时得出的结论,以及我们如何被迫考虑故障并尝试设计我们的系统来处理它们。同样,当谈到网络分区时,我们需要规划分区容错,也就是我们考虑可能出现的潜在网络故障以及它们可能导致的故障的方式!分区容错系统是一个尝试考虑网络分区的系统,因为我们最终都会遇到它们。
虽然数据分区或许是一个可以避免的问题,因为我们甚至可能还没决定是否需要对数据进行分区,但网络分区却是我们无法避免的。事实上,当我们开始学习一些有趣的……定理时,它们还会再次出现。不过,那是另一篇文章要讲的故事了!😉
资源
在学习更高级的分布式系统主题时,分区和分区容错性经常会被提及,因此深入了解这些基础知识至关重要。巧的是,有一些非常棒的资源可以帮助你完成这项任务。我在下面列出了一些我最喜欢的资源,其中一些甚至深入探讨了分区的更高级方面;如果你想了解更多,不妨看看这些资源!
- 分布式系统速查表,Dmitry Fedosov
- 分区:分布式系统的神奇秘诀,Pranay Kumar Chaudhary
- 分布式系统的乐趣和利润,Mikito Takada
- 分布式系统为何如此难?网络分区生存指南,Denise Yu
- 复制与分区,佐治亚理工学院
- Jepsen:论网络分区的危险,Kyle Kingsbury
鏂囩珷鏉ユ簮锛�https://dev.to/vaidehijoshi/parsing-through-partitions-in-a-distributed-system-am0