Twitter 技术面试系统设计示例
披露:本篇文章包含附属链接;如果您通过本文提供的不同链接购买产品或服务,我可能会收到报酬。
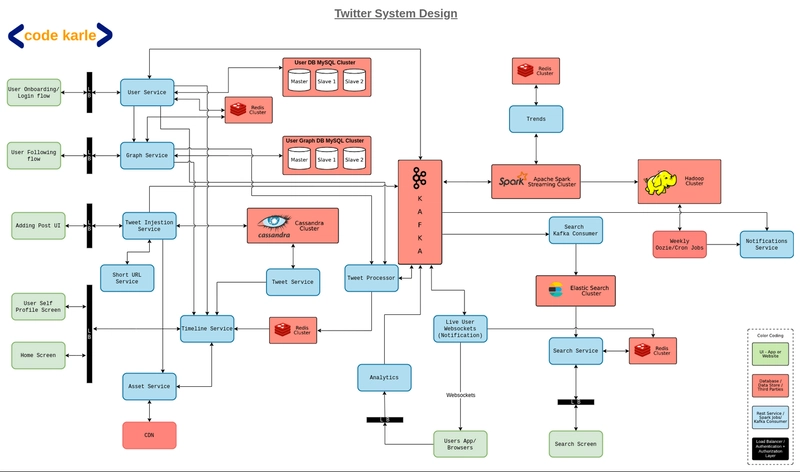
来源 - Sandeep/CodeKarle
大家好,如果您正在准备系统设计面试并寻找常见的系统设计问题和资源,那么您来对地方了。
过去,我曾讨论过基本的系统设计概念,例如API 网关与负载均衡器、水平扩展与垂直扩展、正向代理与反向代理以及常见的系统设计问题,今天我将讨论一个流行的系统设计问题——设计 Twitter 或 X.com。
设计像 Twitter 这样的复杂系统可能具有挑战性,尤其是在系统设计面试中。
最大的挑战不是复杂性,而是时间,因为你需要在 40 分钟内让面试官相信 你了解情况,而这只有当你做好准备并在回答这些问题时遵循结构化的方法才有可能。
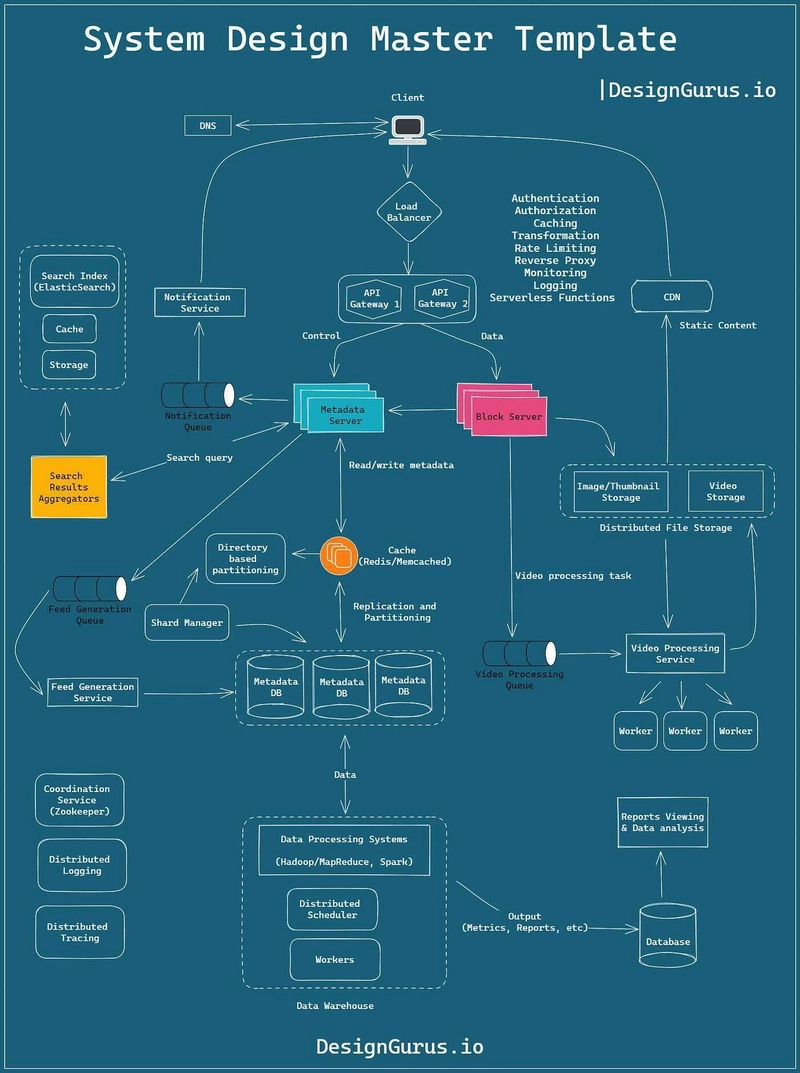
在这个系统设计教程中,我还将为您提供一个简单的指南,以帮助您构建系统设计模板(见下文)来收集您的想法并呈现清晰的设计。
顺便说一句,如果你正在准备系统设计面试,并想在有限的时间内学习系统设计,那么你也可以查看ByteByteGo、DesignGurus.io、Exponent、Educative.io、Codemia.io和Udemy等网站,它们有很多很棒的系统设计课程
同样,在回答系统设计问题时,您也可以遵循DesignGurus.io这样的系统设计模板,以便在有限的时间内更好地表达您的答案。
遵循此模板是你开始准备任何系统设计面试的最佳方法之一。
现在,让我们来探讨问题和解决方案。
如何设计 Twitter 或 X.com?
设计像 Twitter 这样的系统是系统设计面试中的常见场景,但如果您想从头练习这个问题,您可以在Codeemia.io上开始,这是一个 Leetcode 风格的系统设计面试平台。
它拥有超过 120 个系统设计问题,并且还在不断增加,其中包括 Twitter 设计。它还提供由知名公司高级工程师创建的编辑解决方案。
它还提供免费的系统设计问题,其中之一就是Twitter 的设计。您可以点击此处访问。
现在回到问题本身,这是一个展示你对大规模分布式系统的理解的好方法,因为它涉及处理大量用户群、确保高可用性以及在重负载下保持稳定性等各个方面。
本解决方案指南将引导您完成 Twitter 的设计过程,涵盖系统需求、容量估算、API 设计、数据库设计、高级设计、请求流、详细组件设计、权衡和潜在故障场景。
读完本指南后,您将对如何在面试环境中处理和展示此设计有深入的了解。
下面是 Twitter 的架构图,可以帮助大家了解整体思路:
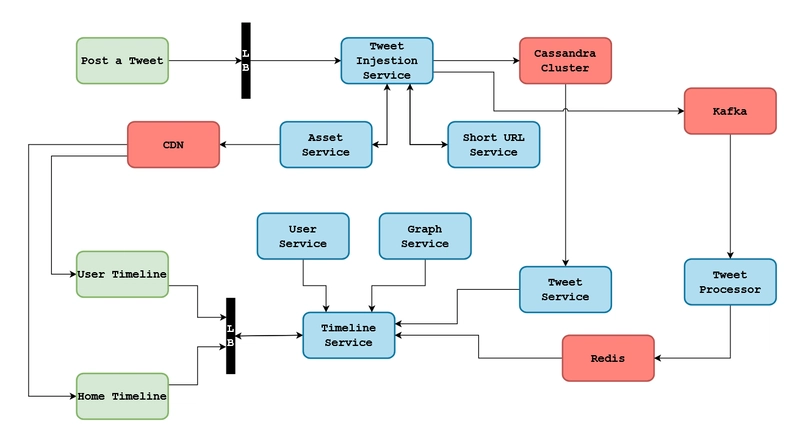
正如我所说,我们将逐步解决这个问题,我们将涵盖:
- 要求
- 容量估算
- QPS(每秒查询次数)
- API 设计
- 数据库设计
- 表格
- 贮存
- 高级设计
- 详细组件设计
- 故障场景和瓶颈
- 权衡
那么,我们还等什么,开始吧。
Twitter 系统要求
首先,您应该正确了解需求,并从功能需求开始。
如果您要克隆真正的应用程序(例如在亚马逊上购买东西或在 Facebook 或 Twitter 上发送消息),请选择您最熟悉的应用程序。
功能要求
为了设计一个强大且用户友好的类似 Twitter 的系统,我们需要概述核心功能。
用户应该能够撰写和分享推文,这是该平台的主要功能。
这包括创建新推文、附加可选媒体文件并与关注者分享。此外,用户还应该能够关注其他用户,并在他们的动态中查看他们的更新。
这意味着管理关注的用户列表并确保他们的推文出现在用户的时间线中。
另一个重要功能是允许用户收藏推文,以表示他们的欣赏,并可能将这些推文添加到书签以供将来参考。
以下是主要功能需求,供您参考:
- 撰写和分享推文:用户应该能够创建和分享推文。
- 关注用户:用户应该能够关注其他用户并查看他们的更新。
- 收藏推文:用户应该能够收藏推文以表示赞赏。
非功能性需求
对于像 Twitter 这样规模的平台来说,非功能性需求至关重要。可扩展性至关重要,因为系统必须处理大量的用户、推文和交互,并且性能不能下降。
高可用性确保平台即使在高峰流量时段或发生硬件故障时仍可访问且正常运行。
稳定性是另一个关键方面,因为服务必须可靠,即使在高并发性下也具有最短的停机时间和一致的性能。
以下是您在面试中应该提及的关键非功能性需求:
- 可扩展性:系统应该能够处理大量的用户、推文和交互。
- 高可用性:即使在高流量下系统也应该可用。
- 稳定性:系统应该稳定且可访问,不会出现频繁的问题或停机。
容量估算
估算用户群是了解系统规模的第一步。在本设计中,我们假设用户群为 5 亿。这有助于我们评估预期负载以及支持如此庞大用户群所需的基础设施。
用户群
- 假设用户群为 5 亿。
流量
为了了解每日运营情况,我们需要估算一下流量。假设每个用户每天发一条推文,那么我们预计每天会有 5 亿条推文。
此外,如果每个用户每天查看 10 页主页,这会产生大量的阅读操作。
关注关系也增加了复杂性,平均每个用户关注 100 个用户,从而产生 500 亿个关注关系。
最后,如果每个用户每天收藏 5 条推文,那么每天就有 25 亿次收藏操作。
以下是您应该考虑或提及的关键流量要求:
- 推文:每天 5 亿条推文(每个用户每天一条推文)。
- 主页动态:每个用户每天浏览 10 页。
- 关注:平均每个用户关注100个其他用户,形成500亿个关注关系。
- 收藏数:每个用户每天收藏 5 条推文,每天收藏数达 25 亿次。
QPS(每秒查询次数)
将这些操作分解为每秒查询数(QPS)有助于我们了解实时负载。
对于写入操作,我们计算出大约 15k QPS,对于读取操作大约 75k QPS,对于最喜欢的操作大约 30k QPS。
这些数字有助于规划必要的基础设施和负载平衡策略。
- 写入:500M×23600×24≈15k\frac{500M \times 2}{3600 \times 24} \approx 15k3600×24500M×2≈15k QPS
- 读取:500M×103600×24≈75k\frac{500M \times 10}{3600 \times 24} \approx 75k3600×24500M×10≈75k QPS
- 收藏数:500M×53600×24≈30k\frac{500M \times 5}{3600 \times 24} \approx 30k3600×24500M×5≈30k QPS
数据大小
了解数据规模对于存储规划至关重要。每天有 5 亿条推文,考虑到编码后每条推文平均 300 字节,这意味着每天新增数据量总计 140GB,每年新增数据量总计 50TB。
对于媒体内容,如果我们假设它的大小是推文的 100 倍,那么每天就会有 10TB,每年就会有 4PB。
这一估计强调了分布式存储架构的必要性。
- 推文:每天 5 亿条推文,每条 140 个字符(300 字节)。总计每天 140GB,每年 50TB。
- 媒体(图像/视频):假设推文的大小为 100 倍,每天 10TB,每年 4PB。
API 设计
现在,让我们来讨论一下 API 设计,这是系统设计面试中的另一个重要领域:
推特
推文 API 需要高效地处理推文的创建和发布。这涉及捕获用户信息、推文内容、位置数据和时间戳。合理的错误处理和验证对于确保流畅的用户体验至关重要。
public Result postTweet(Long userId, String tweetText, String location, DateTime date);
下列的
以下功能需要 API 来管理用户之间的关系。这包括关注和取消关注用户、确保数据完整性以及及时更新用户的关注列表。
public Result followUser(Long userId, Long followedUserId);\
public Result unfollowUser(Long userId, Long followedUserId);
收藏夹
收藏 API 允许用户点赞或点赞推文。这些操作应高效,并具备适当的索引和错误处理功能,以确保快速更新并准确统计每条推文的收藏次数。
public Result favoriteTweet(Long userId, Long tweetId);\
public Result unfavoriteTweet(Long userId, Long tweetId);
推文渲染 API 对于获取和显示关注用户的推文至关重要。这需要高效的查询和分页功能,以确保快速的加载时间和无缝的用户体验。
public Result getFeeds(Long userId, String location, int pageNo);
数据库设计
API 设计之后,我们来谈谈数据库设计
表格
数据库设计涉及定义用户、推文和关注者关系的表。该UserInfo表存储用户详细信息,该Tweets表处理推文内容和元数据,该Follower表管理关注关系。正确的索引对于快速查找和更新至关重要。
- 用户信息表
- 用户 ID(主键)
- 用户名
- 地位
- otherProfile(头像、年龄等)
- 推文表
- tweetId(主键)
- 用户 ID(索引)
- 内容
- 发布时间(索引)
- 修改时间
- 地位
- 追随者表
- 用户身份
- followerId(索引)
- 关注时间
下面是一个简单的 ERD 图,以便更好地理解 Twitter Schema 架构:

贮存
选择正确的存储解决方案至关重要。对于用户个人资料和推文等结构化数据,MySQL 是一个不错的选择,因为它支持复杂的查询和事务。
对于媒体存储,Amazon S3 为图像和视频提供了可扩展且经济高效的存储。
- 使用 MySQL 存储结构化数据(用户、推文、关注关系)。
- 使用 Amazon S3 进行媒体存储(图像和视频)。
高层设计
我们先来看一下高层设计:
客户端层

客户端层涉及网站和应用程序向服务器发送请求。这些请求通过负载均衡器进行分配,以确保负载均衡和高可用性。使用 CDN 处理静态文件有助于减少延迟并缩短加载时间。
- 客户端(网站/应用程序)向服务器发送请求。
- 请求通过负载均衡器分发。
- 使用速率限制器来保护后端服务器。
- 使用 CDN 存储静态文件(图像、视频)。
服务器层
客户端层涉及网站和应用程序向服务器发送请求。这些请求通过负载均衡器进行分配,以确保负载均衡和高可用性。
对静态文件使用 CDN 有助于减少延迟并缩短加载时间。
- 服务器集群处理请求和不同的服务:
- 推文服务:发布推文。
- 用户服务:用户注册和个人资料管理。
- 关注服务:关注/取消关注用户。
- 主页 Feed 服务:呈现用户 Feed。
数据层
数据层使用 Redis 缓存数据以提高响应速度,并使用 MySQL 进行主从架构的持久存储,以确保一致性和可用性。使用 Amazon S3 存储媒体文件,确保可扩展性和持久性。
- 使用Redis进行缓存,提高响应速度。
- 使用具有主从架构的 MySQL 来确保数据的一致性和可用性。
- 使用 Amazon S3 存储媒体文件。
请求流程
解释请求流有助于理解不同组件如何交互。当客户端发送请求时,它首先到达负载均衡器,负载均衡器将其分发到合适的服务器。
服务器处理请求,更新数据库并缓存必要的数据。对于读取请求,将从缓存或数据库中检索数据,并从 CDN 获取媒体文件,从而确保快速响应时间。
- 客户端向负载均衡器发送请求。
- 负载均衡器将请求分发到服务器。
- 速率限制器检查流量。
- 服务器处理请求并将数据存储在 MySQL 和 Redis 中。
- 媒体文件存储在CDN中。
- 对于读取请求,服务器从 CDN 检索文件并从 Redis 或 MySQL 检索数据。
这里有一张漂亮的美人鱼图,可以更好地理解 Twitter 架构中的请求流,当我在Codeemia.io上练习系统设计问题时,我也使用他们的界面来创建这样的美人鱼图。

详细组件设计
现在,让我们看看可以用来设计 Twitter 的详细组件设计和各种软件架构组件。
负载均衡器
在集群中部署多个负载均衡器,保证高可用性和均匀的负载分配。
将负载均衡器放置在不同的位置可以减少用户的延迟,并且使用循环或最少连接等各种算法有助于有效地管理负载。
- 在集群中部署多个负载均衡器。
- 将负载均衡器放置在不同的位置以减少延迟。
- 使用循环、最少连接或 IP 哈希等算法。
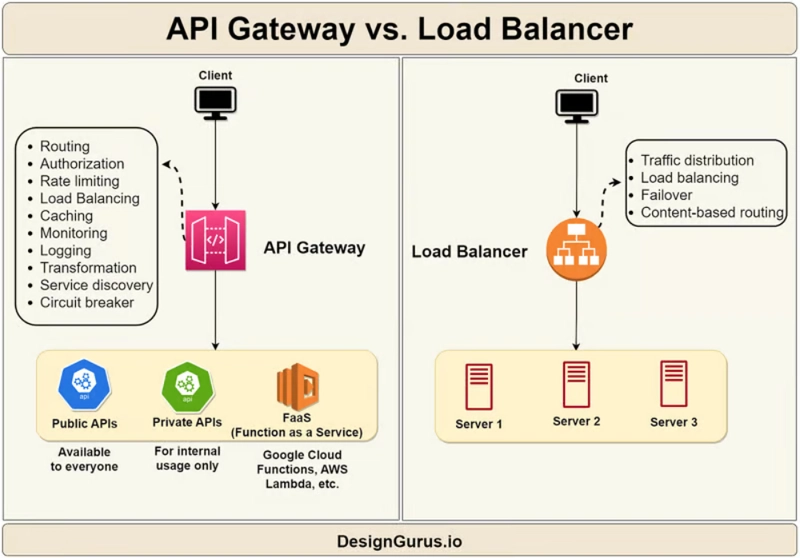
如果您不知道什么是负载均衡器,这里有一个来自DesignGurus.io的精美图表,这是我最喜欢的学习系统设计的网站之一:
CDN
使用 CDN 处理静态内容可以减少源服务器的负载,并缩短用户的加载时间。优化缓存规则并调整 TTL 有助于提高缓存命中率,确保快速提供内容。
- 同时使用拉取和推送缓存方法。
- 优化缓存规则和TTL,实现更高的缓存命中率。
- 通过添加更多服务器节点来扩展系统。
Redis
使用 Redis 进行缓存需要搭建 Redis 集群以实现可扩展性,并采用主从复制实现高可用性。Sentinel 负责监控集群并处理故障转移,确保即使在节点发生故障时缓存仍然可用。
- 使用Redis集群处理大规模数据。
- 采用主从复制来实现高可用性。
- 使用 Sentinel 监视集群并处理故障转移。
MySQL
MySQL 的主从架构支持高流量,并通过复制确保数据一致性。水平分区有助于在多台服务器之间分配负载,从而高效处理大型数据集。
- 对于大容量流量,使用主从架构。
- 使用水平分区来处理更多数据。
权衡与技术选择
这可能是系统设计面试中最重要的部分,因为你必须解释你所做的选择和权衡以及它们如何提供帮助。让我们看看:
数据库
选择 MySQL 而不是 NoSQL 是因为需要复杂的查询和事务支持。NoSQL 虽然提供了模式灵活性,但缺乏对结构化数据和复杂事务的支持,而这些对于 Twitter 的商业模式至关重要。
- 由于需要复杂的查询和事务支持,因此选择 MySQL 而不是 NoSQL。
缓存
Redis 比 Memcached 更受欢迎,因为它支持多种数据类型并支持水平扩展。Memcached 对于基本的键值存储来说非常高效,而 Redis 则提供高级功能和更出色的可扩展性,因此非常适合用于大规模系统。
我选择 Redis 而不是 Memcached,是因为它的高级功能和水平扩展能力。
故障场景和瓶颈
现在,让我们看看我们的系统有多强大和有弹性
混合模型
为了处理关注多个账户的用户,结合拉取和推送两种方式的混合模型可以减少延迟。对于关注多人的用户,推送新推文可以减少信息流聚合的负载,从而提升用户体验。
- 如果用户关注很多人,则结合拉取和推送模型来减少延迟。
阅读热点
处理读取热点(例如拥有大量粉丝的热门用户)需要将其推文缓存在 Redis 中,并使用缓存旁路策略来保持一致性。在 Redis 服务器中添加热点区域并使用本地缓存可以分散负载,避免对同一服务器进行过多的调用。
- 使用缓存旁路策略在 Redis 中缓存热数据。
- 使用本地缓存来处理高流量。
未来的改进
未来的改进包括实施多区域主动-主动策略,以实现灾难恢复和高可用性。
在多个位置部署服务集群和数据库集群,并具有自动故障转移和负载平衡功能,可确保无单点故障,从而保持服务的连续性和可靠性。
- 实施多区域主动-主动策略,实现灾难恢复和高可用性。
- 继续优化缓存、负载平衡和数据存储策略以应对未来的增长。
最佳系统设计面试资源(2024)
如果你正在准备系统设计面试,并正在寻找最佳资源,那么这里精选了最佳系统设计书籍、在线课程和练习网站,你可以参考这些资源,更好地准备系统设计面试。这些课程中的大多数也解答了我在这里分享的问题。
-
DesignGuru 的 Grokking 系统设计课程:一个交互式学习平台,通过实践练习和真实场景来加强您的系统设计技能。
-
Codemia.io:这是另一个练习面试系统设计问题的优秀平台。它有超过 120 个系统设计问题,其中许多是免费的,并且提供了合适的解答结构。
-
ByteByteGo:Alex Xu 编写的一本用于系统设计面试准备的在线书籍和课程。它包含《系统设计面试》第一卷和第二卷的所有内容,并将于即将更新第三卷。
-
Exponent:一个专门为亚马逊和谷歌等 FAANG 公司提供面试准备的专业网站,他们还提供很棒的系统设计课程和许多其他材料,可以帮助您破解 FAAN 面试。
-
Alex Xu 撰写的《系统设计面试》:本书深入探讨了系统设计的概念、策略和面试准备技巧。
-
Martin Kleppmann 撰写的《设计数据密集型应用程序》:一本涵盖设计可扩展且可靠系统的原则和实践的综合指南。
-
LeetCode 系统设计标签:LeetCode 是一个流行的技术面试准备平台。LeetCode 上的系统设计标签包含各种练习题。
-
GitHub 上的“系统设计入门”:精选资源列表,包括文章、书籍和视频,可帮助您准备系统设计面试。
-
Educative 的系统设计课程:一个交互式学习平台,通过实践练习和真实场景来加强您的系统设计技能。
-
高可扩展性博客:一个以高流量网站和可扩展系统架构的文章和案例研究为特色的博客。
-
YouTube 频道:查看“Gaurav Sen”和“Tech Dummies”等频道,获取有关系统设计概念和面试准备的深刻视频。
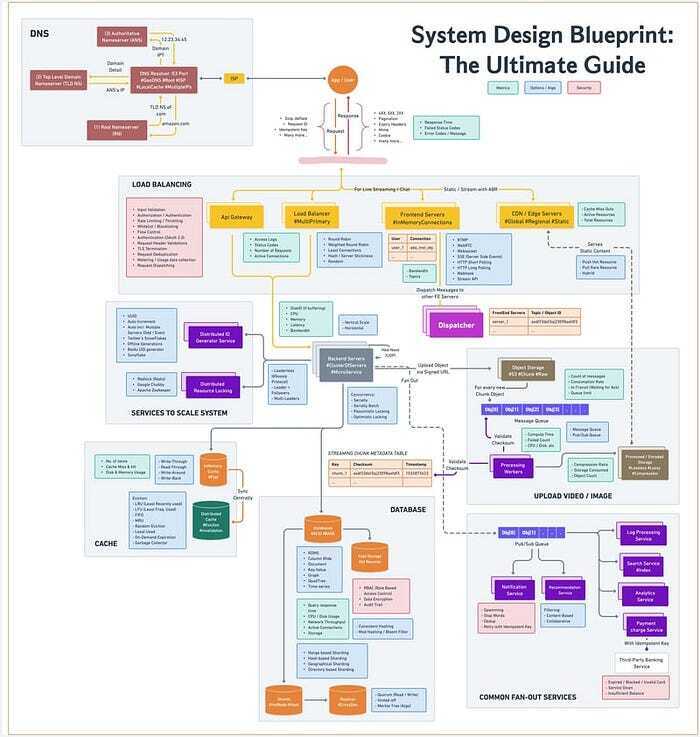
图片来源 --- ByteByteGo
记住要通过从事真实项目和参加模拟面试将理论知识与实际应用结合起来。
不断的练习和学习会让你对系统设计面试充满信心。
以上就是关于如何在系统设计面试中设计 Twitter 或 X.com 的全部内容。遵循此结构,您可以设计一个类似 Twitter 的健壮且可扩展的系统。本指南将帮助您在系统设计面试中有效地展示您的设计。
祝你的系统设计面试顺利
文章来源:https://dev.to/somadevtoo/twitter-system-design-example-for-tech-interviews-1ihb