5 个用于有效 ML 测试的开源工具
Giskard-AI/giskard 🐢
自信的人工智能/deepeval ✍️
promptfoo/promptfoo 🔎
深度检查/深度检查✅
远大期望/远大期望📊
你好👋
在本周的文章中,我们将研究各种机器学习测试工具。
以下工具旨在提高模型的准确性、可靠性和整体有效性。
无论您是刚刚开始机器学习之旅,还是经验丰富的专家,我都希望您能从以下存储库中受益。
准备好检查一下了吗?

厚颜无耻的宣传:如果你喜欢构建 ML 和 GenAI 项目,那么获得奖励会是什么感觉?🙃
想要参与,请注册Quira并查看“任务”。当前奖池为 2048 美元;点击图片了解更多信息。👇

现在您已经查看了我们的任务,让我们看看如何利用下面的存储库来构建出色的 ML/GenAI 项目。🚀
Giskard-AI/giskard 🐢
从表格到 LLM 的测试框架

我为什么要考虑这个 repo? Giskard 可以看作是模型的健康体检。它可以扫描许多模型,从简单的表格模型到高级语言模型。它能够灵活地适应任何环境和模型,这让它能够很好地确保你的模型公平、准确,并可用于实际应用。顺便说一句,我去年在一次会议上见过他们的创始人,他们的项目给我留下了深刻的印象!
安装: pip install giskard -U
入门:
import giskard
# Replace this with your own data & model creation.
df = giskard.demo.titanic_df()
demo_data_processing_function, demo_sklearn_model = giskard.demo.titanic_pipeline()
# Wrap your Pandas DataFrame with Giskard.Dataset (test set, a golden dataset, etc.).
giskard_dataset = giskard.Dataset(
df=df, # A pandas.DataFrame that contains the raw data (before all the pre-processing steps) and the actual ground truth variable (target).
target="Survived", # Ground truth variable
name="Titanic dataset", # Optional
cat_columns=['Pclass', 'Sex', "SibSp", "Parch", "Embarked"] # List of categorical columns. Optional, but is a MUST if available. Inferred automatically if not.
)
# Wrap your model with Giskard.Model. Check the dedicated doc page: https://docs.giskard.ai/en/latest/guides/wrap_model/index.html
# you can use any tabular, text or LLM models (PyTorch, HuggingFace, LangChain, etc.),
# for classification, regression & text generation.
def prediction_function(df):
# The pre-processor can be a pipeline of one-hot encoding, imputer, scaler, etc.
preprocessed_df = demo_data_processing_function(df)
return demo_sklearn_model.predict_proba(preprocessed_df)
giskard_model = giskard.Model(
model=prediction_function, # A prediction function that encapsulates all the data pre-processing steps and that could be executed with the dataset used by the scan.
model_type="classification", # Either regression, classification or text_generation.
name="Titanic model", # Optional
classification_labels=demo_sklearn_model.classes_, # Their order MUST be identical to the prediction_function's output order
feature_names=['PassengerId', 'Pclass', 'Name', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'], # Default: all columns of your dataset
)
scan_results = giskard.scan(giskard_model, giskard_dataset)
display(scan_results)
以下是测试模型后可能收到的输出示例。👇
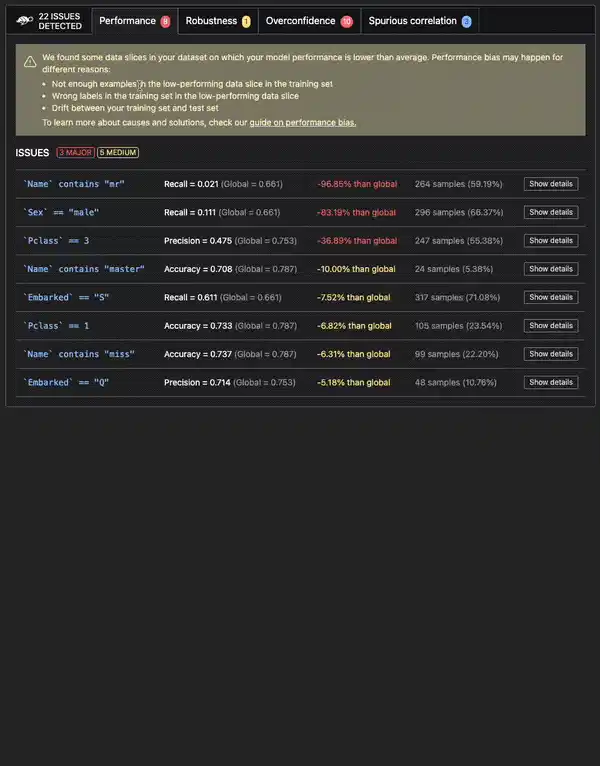
https://github.com/Giskard-AI/giskard
自信的人工智能/deepeval ✍️
法学硕士评估框架
我为什么要考虑这个 repo? DeepEval 是一款面向 LLM 开发者的工具。它提供了一个专业且易于使用的测试框架,类似于 Pytest,但专注于 LLM。它能够运行各种关键指标,确保对 LLM 应用程序进行全面的质量检查。
安装: pip install -U deepeval
入门:
from deepeval import evaluate
from deepeval.metrics import HallucinationMetric
from deepeval.test_case import LLMTestCase
input = "What if these shoes don't fit?"
context = ["All customers are eligible for a 30 day full refund at no extra costs."]
# Replace this with the actual output from your LLM application
actual_output = "We offer a 30-day full refund at no extra costs."
hallucination_metric = HallucinationMetric(threshold=0.7)
test_case = LLMTestCase(
input=input,
actual_output=actual_output,
context=context
)
evaluate([test_case], [hallucination_metric])
以下是测试模型后可能收到的输出示例。👇

https://github.com/confident-ai/deepeval
promptfoo/promptfoo 🔎
衡量 LLM 质量并捕捉回归
为什么要考虑这个 repo?当您想使用各种 LLM 评估不同提示的输出时,应该使用此工具。它旨在通过并排比较、缓存和并发来简化评估。您可以将 promptfoo 用于各种知名的 LLM 提供商(OpenAI、Gemini)和自定义 API。
安装: npx promptfoo@latest init
入门:
import promptfoo from 'promptfoo';
const results = await promptfoo.evaluate({
prompts: ['Rephrase this in French: {{body}}', 'Rephrase this like a pirate: {{body}}'],
providers: ['openai:gpt-3.5-turbo'],
tests: [
{
vars: {
body: 'Hello world',
},
},
{
vars: {
body: "I'm hungry",
},
},
],
});
以下是测试模型后可能收到的输出示例。👇

https://github.com/promptfoo/promptfoo
深度检查/深度检查✅
sklearn 和 pandas 的 ML 测试
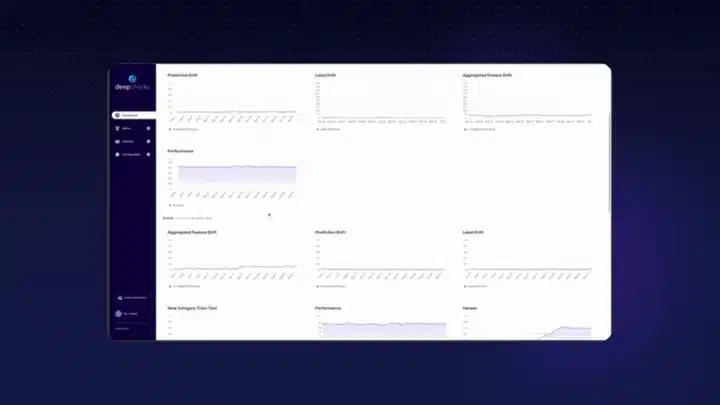
我为什么要考虑这个 repo? Deepchecks 是一款适用于从研究到生产各个阶段的工具。它专注于提供持续验证,对不同类型的数据类型(表格、NLP、Vision)进行检查,并集成到您的 CI/CD 工作流中。
安装: pip install deepchecks -U --user
入门:
from deepchecks.tabular.suites import model_evaluation
suite = model_evaluation()
suite_result = suite.run(train_dataset=train_dataset, test_dataset=test_dataset, model=model)
suite_result.save_as_html() # replace this with suite_result.show() or suite_result.show_in_window() to see results inline or in window
# or suite_result.results[0].value with the relevant check index to process the check result's values in python
以下是测试模型后可能收到的输出示例。👇
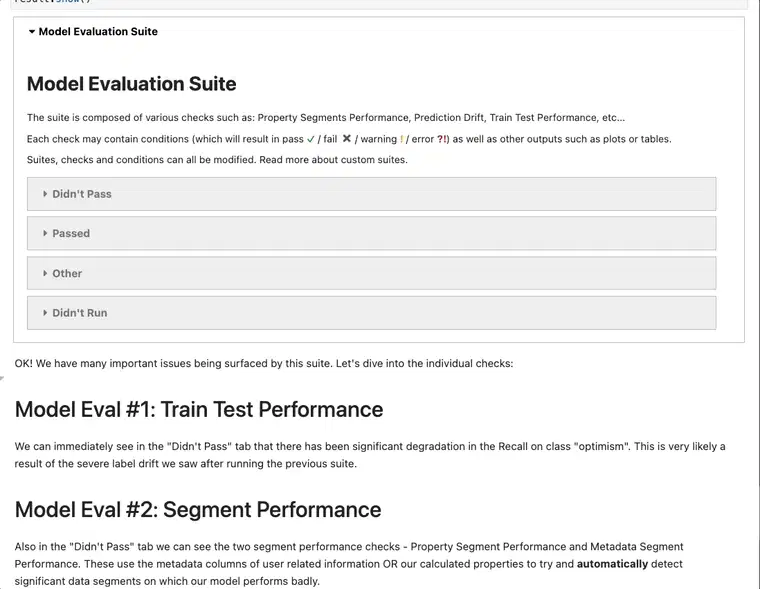
https://github.com/deepchecks/deepchecks
远大期望/远大期望📊
始终了解对数据的期望
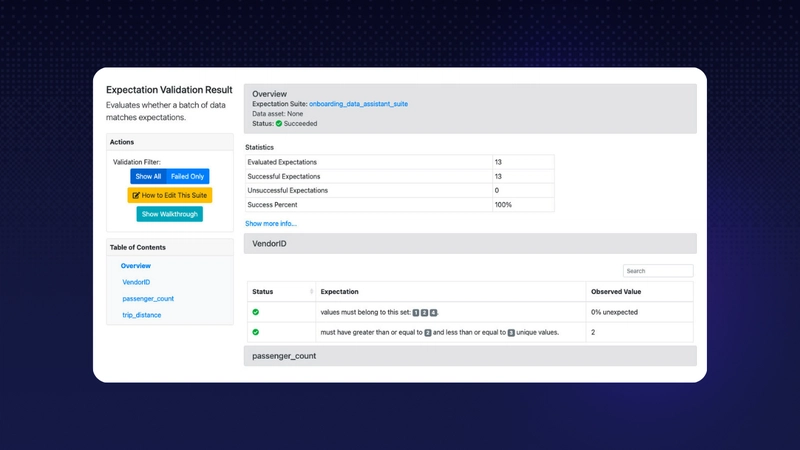
我为什么要考虑这个 repo?这个工具就像你的数据质量控制专家。Great Expectations 不是一个管道执行框架。相反,它与 Spark、Airflow、dbt、prefect、dagster、Kedro、Flyte 等 DAG 执行工具无缝集成。在这些工具执行管道的同时,它可以测试你的数据质量管道。
安装: pip install great_expectations
入门:
# It is recommended to deploy within a virtual environment
import great_expectations as gx
context = gx.get_context()
根据您已经使用的工具和系统,设置阶段将会有很大不同。
这就是为什么最好阅读他们的文档(我发现它们制作得非常好)!🤓
https://github.com/great-expectations/great_expectations
伙计们,就这些了。🌟
我希望这些发现有价值,并能帮助你建立机器学习模型!⚒️
如果您想利用这些工具来构建酷炫的 ML/GenAI 项目并获得奖励,请登录Quira并探索任务!💰

与往常一样,请考虑通过加星标来支持这些项目。⭐️
我们与他们没有任何关系。
我们只是认为伟大的项目值得得到高度认可。
下周见,
您的 Dev.to 好友💚
巴普
如果你想加入自称“最酷”的开源服务器😝,那就加入我们的Discord服务器吧。我们随时准备帮助你踏上开源之旅。🫶
文章来源:https://dev.to/fernandezbaptiste/5-open-source-tools-for- effective-ml-testing-2mc4