使用 C# 创建一个简单的 Web 爬虫
构建 Web 爬虫
网络爬虫是一项在很多情况下都很有用的技能,尤其是在你需要从网站上获取一组特定数据的时候。我相信它在工程和科学领域最常用于检索统计数据或包含特定关键词的文章。在本教程中,我将教你如何从网站上爬取后者——包含特定关键词的文章。
在开始之前,我想先介绍一下网页抓取及其一些局限性。网页抓取也称为网页采集或网页数据提取,是一种自动从互联网网站提取数据的方法。今天我将教给大家的解析方法是 HTML 解析,这意味着我们的网页抓取工具会查看页面的 HTML 内容,并提取与我们要检索信息的类别相匹配的信息(如果您不明白,不用担心,稍后我会更详细地讲解!)。这种网页抓取方法的局限性在于,并非所有网站都以 HTML 格式存储所有信息——我们今天看到的很多内容都是动态的,是在页面加载后构建的。为了获取这些信息,需要一个更复杂的网页爬虫,通常需要自带网页加载器,但这超出了本教程的讨论范围。
我选择用 C# 构建网页爬虫是因为大多数教程都是用 Python 构建的。虽然 Python 可能是完成这项工作的理想语言,但我想证明 C# 也能做到。我还希望通过提供一些 C# 网页爬虫教程(截至撰写本文时),帮助其他人学习如何构建自己的网页爬虫。
构建 Web 爬虫
我们将要抓取的网站是加拿大海洋网络 (Ocean Networks Canada),这是一个致力于提供有关海洋和地球信息的网站。使用该项目抓取互联网文章和数据的用户会发现,该网站提供的模型与他们遇到的许多其他网站类似。
-
启动 Visual Studio 并创建一个新的 C# .NET Windows 窗体应用程序。
-
设计一个基本表单,其中包含一个按钮来启动抓取工具和一个富文本框来打印结果。

-
在解决方案资源管理器中右键单击项目名称,然后选择“管理 NuGet 包”,打开 NuGet 包管理器。搜索“AngleSharp”,然后单击“安装”。

-
添加一个查询词数组(这些应该是您希望文章标题中包含的单词),并创建一个方法,用于设置要抓取的文档。您的代码应如下所示:
private string Title { get; set; } private string Url { get; set; } private string siteUrl = "https://www.oceannetworks.ca/news/stories"; public string[] QueryTerms { get; } = {"Ocean", "Nature", "Pollution"}; internal async void ScrapeWebsite() { CancellationTokenSource cancellationToken = new CancellationTokenSource(); HttpClient httpClient = new HttpClient(); HttpResponseMessage request = await httpClient.GetAsync(siteUrl); cancellationToken.Token.ThrowIfCancellationRequested(); Stream response = await request.Content.ReadAsStreamAsync(); cancellationToken.Token.ThrowIfCancellationRequested(); HtmlParser parser = new HtmlParser(); IHtmlDocument document = parser.ParseDocument(response); }如果任务或线程请求取消,CancellationTokenSource会提供一个令牌。HttpClient提供了一个基类,用于从 URI 标识的资源发送 HTTP 请求和接收 HTTP 响应。HttpResponseMessage
表示HTTP 响应消息,包含状态码和数据。HtmlParser和
IHtmlDocument
是 AngleSharp 类,可用于从网站 HTML 内容构建和解析文档。 -
创建另一个新方法来获取并显示 AngleSharp 文档的结果。在这里,我们将解析文档并检索所有符合 QueryTerms 的文章。这可能比较棘手,因为每个网站使用的 HTML 命名约定都不尽相同——可能需要反复尝试才能确保“articleLink” LINQ 查询正确:
private void GetScrapeResults(IHtmlDocument document) { IEnumerable<IElement> articleLink; foreach (var term in QueryTerms) { articleLink = document.All.Where(x => x.ClassName == "views-field views-field-nothing" && (x.ParentElement.InnerHtml.Contains(term) || x.ParentElement.InnerHtml.Contains(term.ToLower()))); } if (articleLink.Any()) { // Print Results: See Next Step } }如果您不确定这里发生了什么,我将更详细地解释:我们循环遍历每个 QueryTerms(海洋、自然和污染)并解析我们的文档以查找 ClassName 为“views-field views-field-nothing”的所有实例,并且 ParentElement.InnerHtml 包含我们当前正在查询的术语。
如果您不熟悉如何查看网页的 HTML,可以通过以下方式找到:导航到所需的 URL,右键单击页面上的任意位置,然后选择“查看页面源代码”。有些页面的 HTML 代码量很少,而有些页面则包含数万行。您需要仔细检查所有这些内容,找到文章标题的存储位置,然后确定包含它们的类。我使用的一个技巧是搜索其中一篇文章标题的一部分,然后向上移动几行。

-
现在,如果我们的查询词是有利可图的,我们应该会得到一个包含几组 HTML 的列表,其中包含文章标题和 URL。创建一个新方法,将结果打印到富文本框中。
public void PrintResults(string term, IEnumerable<IElement> articleLink) { // Clean Up Results: See Next Step resultsTextbox.Text = $"{Title} - {Url}{Environment.NewLine}"; } -
如果我们按原样打印结果,它们看起来会像 HTML 标记一样,包含各种标签、尖括号和其他一些不太人性化的内容。我们需要插入一个方法来清理结果,然后再将它们打印到表单中。而且,就像步骤 5 一样,不同网站的标记会有很大差异。
private void CleanUpResults(IElement result) { string htmlResult = result.InnerHtml.ReplaceFirst(" <span class=\"field-content\"><div><a href=\"", "https://www.oceannetworks.ca"); htmlResult = htmlResult.ReplaceFirst("\">", "*"); htmlResult = htmlResult.ReplaceFirst("</a></div>\n<div class=\"article-title-top\">", "-"); htmlResult = htmlResult.ReplaceFirst("</div>\n<hr></span> ", ""); // Split Results: See Next Step }那么这里发生了什么?好吧,我检查了传入结果对象的 InnerHtml 部分,看看需要从我真正想要显示的内容(标题和 URL)中删除哪些多余的内容。从左到右,我简单地将每一段 HTML 内容替换为空字符串或“无”,然后将 URL 和标题之间的部分替换为“*”作为占位符,以便稍后拆分字符串。ReplaceFirst() 在每个网站上的用法都有所不同,甚至可能无法在特定网站上的每篇文章上都完美运行。您可以继续添加新的替换,或者如果它们不够常见,则忽略它们。
-
我相信您从上一步就注意到了,在我们将干净的结果打印到文本框之前,还有最后一个方法需要添加。现在我们已经清理了结果字符串,我们可以使用“*”占位符将其拆分为两个字符串——标题和 URL。
private void SplitResults(string htmlResult) { string[] splitResults = htmlResult.Split('*'); Url = splitResults[0]; Title = splitResults[1]; } -
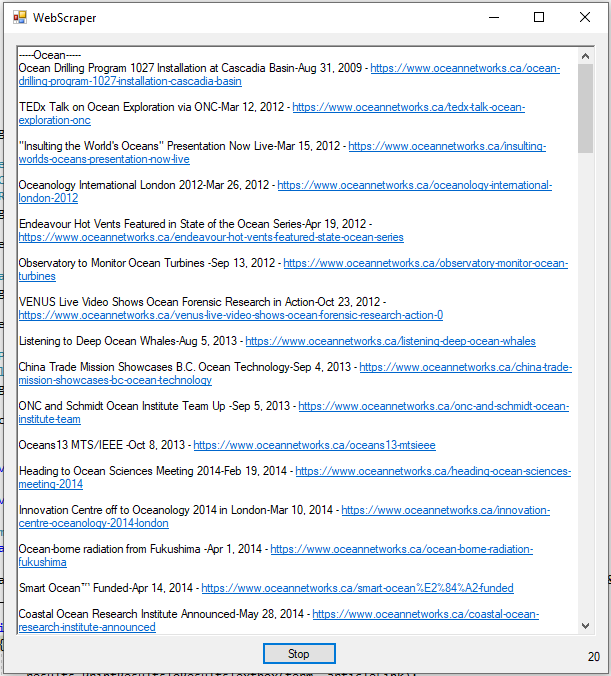
终于,我们得到了一个干净利落、人性化的结果!如果一切顺利,并且文章自撰写以来没有发生太大变化,运行你的代码应该会得到以下结果(还有更多……还有很多!),这些结果都是你的应用程序从 Ocean Networks 抓取的:





希望本教程能让您深入了解网络爬虫的世界。如果您感兴趣,我可以继续本系列教程,教您如何设置应用程序,使其在特定时间间隔执行新的爬虫操作,并向您发送包含当天或一周结果的简报式电子邮件。
如果您想在社交媒体上关注我,欢迎通过Twitter或LinkedIn找到我并打个招呼!
文章来源:https://dev.to/rachelsoderberg/create-a-simple-web-scraper-in-c-1l1m