系统设计:URL缩短器
系统设计
目录
让我们设计一个 URL 缩短器,类似于Bitly、TinyURL等服务。
什么是 URL 缩短器?
URL 缩短服务会为长 URL 创建别名或短 URL。用户访问这些短链接时会被重定向到原始 URL。
例如,以下长 URL 可以更改为较短的 URL。
长网址:https://karanpratapsingh.com/courses/system-design/url-shortener
短网址:https://bit.ly/3I71d3o
为什么我们需要 URL 缩短器?
当我们分享 URL 时,URL 缩短器通常可以节省空间。用户也不太可能输错较短的 URL。此外,我们还可以跨设备优化链接,从而追踪单个链接。
要求
我们的URL缩短系统应满足以下要求:
功能要求
- 给定一个 URL,我们的服务应该为其生成一个更短且唯一的别名。
- 用户访问短链接时应被重定向到原始 URL。
- 链接应在默认时间跨度后过期。
非功能性需求
- 高可用性和最小延迟。
- 该系统应具有可扩展性和高效性。
扩展要求
估计和约束
让我们从估计和约束开始。
注意:请务必与面试官核对任何与规模或交通相关的假设。
交通
这将是一个读取密集型的系统,因此我们假设100:1读/写比率为每月生成 1 亿个链接。
每月读/写次数
每月阅读量:
100×1亿 =100亿/月
对于写入也类似:
1×1亿 =1亿/月
我们的系统的每秒请求数(RPS)是多少?
每月 1 亿个请求相当于每秒 40 个请求。
(30天 ×24小时 ×3600秒) 1亿 =∼40 URL /秒
有了100:1读/写比率,重定向的次数将是:
100×40 URL /秒 =4000个请求/秒
### 带宽
由于我们预计每秒会有大约 40 个 URL,并且如果我们假设每个请求的大小为 500 字节,那么写入请求的总传入数据将是:
40×500字节 =20 KB /秒
类似地,对于读取请求,由于我们预计大约有 4K 重定向,因此总传出数据将是:
4000 URL /秒 ×500字节 =∼2 MB /秒
### 贮存
在存储方面,我们假设每个链接或记录在数据库中存储 10 年。由于我们预计每月会有大约 1 亿个新请求,因此我们需要存储的记录总数为:
1亿 ×10年 ×12个月 =120亿
和之前一样,假设每个存储的记录大约为 500 字节,那么我们需要大约 6TB 的存储空间:
120亿 ×500字节 =6 TB
### 缓存
对于缓存,我们将遵循经典的帕累托原则,也称为 80/20 规则。这意味着 80% 的请求针对 20% 的数据,因此我们可以缓存大约 20% 的请求。
由于我们每秒收到大约 4K 个读取或重定向请求,这相当于每天 3.5 亿个请求。
4000 URL /秒 ×24小时 ×3600秒 =∼每天3.5亿个请求
因此,我们每天需要大约 35GB 的内存。
20 % ×3.5亿 ×500字节 =35 GB /天
### 高级估算
以下是我们的高级估计:
| 类型 |
估计 |
| 写入(新 URL) |
40/秒 |
| 读取(重定向) |
4K/秒 |
| 带宽(传入) |
20 KB/秒 |
| 带宽(传出) |
2 MB/秒 |
| 储存(10年) |
6 TB |
| 内存(缓存) |
每天约 35 GB |
数据模型设计
接下来,我们将重点关注数据模型设计。以下是我们的数据库架构:
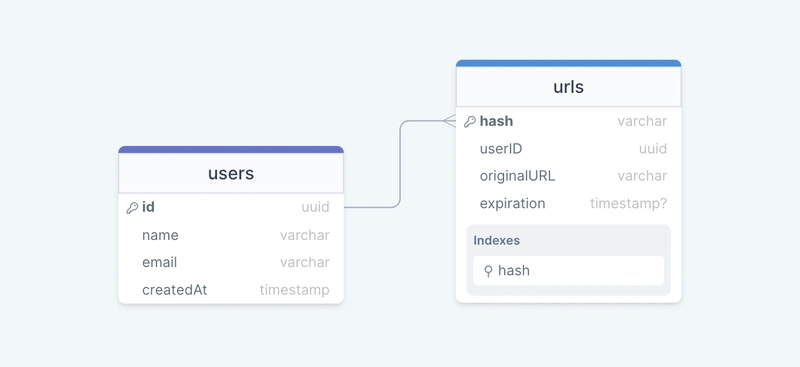
最初,我们可以从两个表开始:
用户
name存储用户的详细信息,如email、、createdAt等。
网址
包含新建短网址的创建用户的expiration、hash、originalURL等属性。我们也可以使用该列作为索引,提升查询性能。userIDhash
我们应该使用什么样的数据库?
由于数据不是强关系,因此 NoSQL 数据库(例如Amazon DynamoDB、Apache Cassandra或MongoDB)将是更好的选择,如果我们决定使用 SQL 数据库,那么我们可以使用Azure SQL 数据库或Amazon RDS之类的数据库。
有关更多详细信息,请参阅SQL 与 NoSQL。
API 设计
让我们为我们的服务做一个基本的 API 设计:
创建 URL
此 API 应根据原始 URL 在我们的系统中创建一个新的短 URL。
createURL(apiKey: string, originalURL: string, expiration?: Date): string
参数
API 密钥(string):用户提供的 API 密钥。
原始网址(string):要缩短的原始网址。
到期日期 ( Date):新 URL 的到期日期(可选)。
返回
短网址(string):新的缩短网址。
获取 URL
此 API 应从给定的短 URL 中检索原始 URL。
getURL(apiKey: string, shortURL: string): string
参数
API 密钥(string):用户提供的 API 密钥。
短网址(string):映射到原始网址的短网址。
返回
原始 URL ( string):要检索的原始 URL。
删除网址
此 API 应从我们的系统中删除给定的短网址。
deleteURL(apiKey: string, shortURL: string): boolean
参数
API 密钥(string):用户提供的 API 密钥。
短网址(string):需要删除的短网址。
返回
结果(boolean):表示操作是否成功。
为什么我们需要 API 密钥?
您肯定已经注意到了,我们使用 API 密钥来防止服务被滥用。使用此 API 密钥,我们可以限制用户每秒或每分钟的请求数量。这是开发者 API 的标准做法,应该能够满足我们的扩展需求。
高层设计
现在让我们对我们的系统进行高层设计。
URL 编码
我们系统的主要目标是缩短给定的 URL,让我们看看不同的方法:
Base62 方法
在这种方法中,我们可以使用Base62对原始 URL 进行编码,它由大写字母 AZ、小写字母 az 和数字 0-9 组成。
URL数量 =6 2北
在哪里,
N:生成的URL的字符数。
因此,如果我们想要生成一个长度为 7 个字符的 URL,我们将生成约 3.5 万亿个不同的 URL。
6 25=∼9.16亿个网址6 2 6=∼568亿个URL 6 2 7=∼3.5万亿个URL
这是这里最简单的解决方案,但它不能保证密钥不重复或抗碰撞。
MD5方法
MD5 消息摘要算法是一种广泛使用的哈希函数,它生成一个 128 位哈希值(或 32 位十六进制数字)。我们可以使用这 32 位十六进制数字来生成 7 个字符长的 URL。
M D 5 (原你r l )→Base 62编码→哈希
然而,这给我们带来了一个新问题,那就是重复和冲突。我们可以尝试重新计算哈希值,直到找到唯一的哈希值,但这会增加系统的开销。最好还是寻找更可扩展的方法。
反击方法
在这种方法中,我们将从一台服务器开始,该服务器将维护生成的密钥的数量。一旦我们的服务收到请求,它就会联系计数器,计数器返回一个唯一的数字并递增。当下一个请求到来时,计数器再次返回该唯一数字,如此循环。
计数器( 0−3.5万亿) →Base 62编码→哈希
这种方法的问题在于它很快就会成为单点故障。而且,如果我们运行多个计数器实例,可能会发生冲突,因为它本质上是一个分布式系统。
为了解决这个问题,我们可以使用分布式系统管理器,例如Zookeeper,它可以提供分布式同步功能。Zookeeper 可以为我们的服务器维护多个范围。
范围1 : 1→1 ,000 , 000范围2 : 1 ,000 ,001→2 、000 , 000范围3 : 2 、000 ,001→3 、000 , 000...
一旦服务器达到其最大范围,Zookeeper 就会将未使用的计数器范围分配给新服务器。这种方法可以保证 URL 不重复且不会发生冲突。此外,我们可以运行多个 Zookeeper 实例来消除单点故障。
密钥生成服务(KGS)
正如我们所讨论的,大规模生成唯一密钥且避免重复和冲突可能颇具挑战性。为了解决这个问题,我们可以创建一个独立的密钥生成服务 (KGS),它会提前生成唯一密钥并将其存储在单独的数据库中以供后续使用。这种方法可以简化我们的工作。
如何处理并发访问?
一旦使用了密钥,我们可以在数据库中对其进行标记,以确保不会重复使用它,但是,如果有多个服务器实例同时读取数据,则两个或多个服务器可能会尝试使用相同的密钥。
解决这个问题最简单的方法是将键存储在两个表中。一旦某个键被使用,我们就将其移动到一个单独的表中,并设置适当的锁定。此外,为了提高读取速度,我们可以将一些键保留在内存中。
KGS数据库估计
根据我们的讨论,我们可以生成最多约 568 亿个独特的 6 个字符长的密钥,这将导致我们必须存储 300 GB 的密钥。
6个字符 ×568亿 =∼390 GB
虽然对于这个简单的用例来说 390 GB 似乎很多,但重要的是要记住这是我们整个服务生命周期的大小,并且密钥数据库的大小不会像我们的主要数据库那样增加。
缓存
现在,我们来谈谈缓存。根据我们的估算,我们每天大约需要 35 GB 的内存来缓存 20% 的服务请求。对于这种用例,我们可以将Redis或Memcached服务器与 API 服务器一起使用。
有关详细信息,请参阅缓存。
设计
现在我们已经确定了一些核心组件,让我们开始系统设计的初稿。
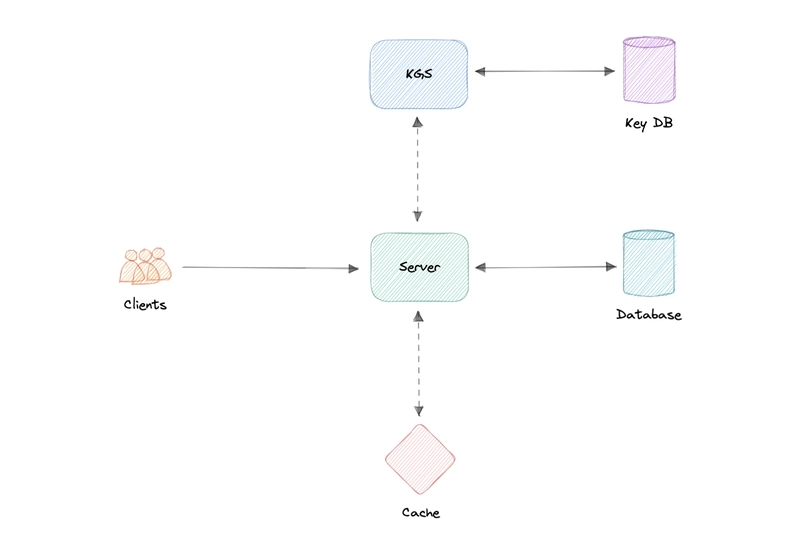
工作原理如下:
创建新的 URL
- 当用户创建新的 URL 时,我们的 API 服务器会从密钥生成服务 (KGS) 请求一个新的唯一密钥。
- 密钥生成服务向 API 服务器提供唯一密钥,并将该密钥标记为已使用。
- API 服务器将新的 URL 条目写入数据库和缓存。
- 我们的服务向用户返回 HTTP 201(已创建)响应。
访问 URL
- 当客户端导航到某个短 URL 时,请求就会发送到 API 服务器。
- 请求首先访问缓存,如果在那里找不到条目,则从数据库中检索,并向原始 URL 发出 HTTP 301(重定向)。
- 如果在数据库中仍然找不到该密钥,则会向用户发送 HTTP 404(未找到)错误。
详细设计
现在是时候讨论我们设计的细节了。
数据分区
为了扩展数据库,我们需要对数据进行分区。水平分区(又称分片)是一个很好的第一步。我们可以使用以下分区方案:
- 基于哈希的分区
- 基于列表的分区
- 基于范围的分区
- 复合分区
上述方法仍然会导致数据和负载分布不均匀,我们可以使用一致性哈希来解决这个问题。
有关更多详细信息,请参阅分片和一致性哈希。
数据库清理
这更像是我们服务的维护步骤,取决于我们是保留过期条目还是将其删除。如果我们决定删除过期条目,我们可以通过两种不同的方式进行:
主动清理
在主动清理中,我们将运行一个单独的清理服务,该服务将定期从存储和缓存中移除过期链接。这将是一个非常轻量级的服务,类似于cron 作业。
被动清理
对于被动清理,我们可以在用户尝试访问过期链接时删除相应条目。这可以确保数据库和缓存的延迟清理。
缓存
现在让我们来讨论一下缓存。
使用哪种缓存驱逐策略?
正如我们之前讨论过的,我们可以使用Redis或Memcached等解决方案并缓存 20% 的每日流量,但哪种缓存驱逐策略最适合我们的需求?
对我们的系统来说,最近最少使用(LRU)策略可能是一个不错的选择。在这个策略中,我们首先丢弃最近最少使用的键。
如何处理缓存未命中?
每当出现缓存未命中时,我们的服务器可以直接访问数据库并使用新条目更新缓存。
指标和分析
记录分析和指标是我们的扩展需求之一。我们可以将访客的国家/地区、平台、浏览次数等元数据与 URL 条目一起存储在数据库中并进行更新。
安全
为了安全起见,我们可以引入私有 URL 和授权机制。可以使用单独的表来存储有权访问特定 URL 的用户 ID。如果用户没有适当的权限,我们可以返回 HTTP 401(未授权)错误。
我们还可以使用API 网关,因为它们可以开箱即用地支持授权、速率限制和负载平衡等功能。
识别并解决瓶颈
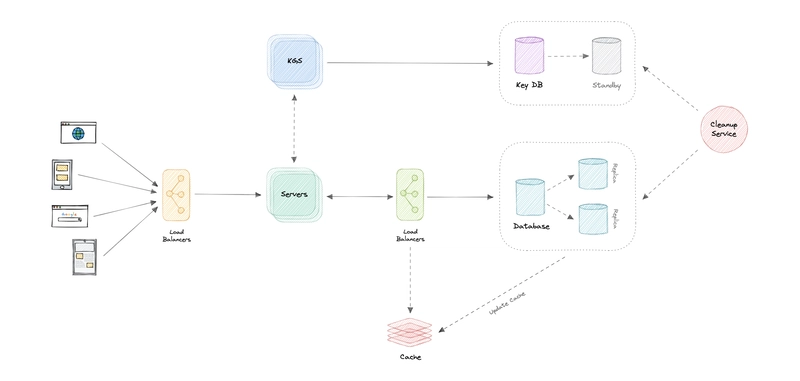
让我们识别并解决设计中的单点故障等瓶颈:
- “如果 API 服务或密钥生成服务崩溃怎么办?”
- “我们将如何在组件之间分配流量?”
- “我们如何才能减轻数据库的负载?”
- “如果KGS使用的密钥数据库出现故障怎么办?”
- “如何提高我们的缓存的可用性?”
为了使我们的系统更具弹性,我们可以执行以下操作:
- 运行我们的服务器和密钥生成服务的多个实例。
- 在客户端、服务器、数据库和缓存服务器之间引入负载平衡器。
- 由于我们的数据库是一个读取密集型系统,因此对其使用多个读取副本。
- 我们的关键数据库的备用副本,以防万一它出现故障。
- 我们的分布式缓存有多个实例和副本。
本文是我在 Github 上提供的开源系统设计课程的一部分。
系统设计
嘿,欢迎来到本课程。希望本课程能给您带来良好的学习体验。
这门课程也可以在我的网站上找到,也可以在leanpub上找到电子书。如果觉得有帮助,请留下⭐作为鼓励!
目录
文章来源:https://dev.to/karanpratapsingh/system-design-url-shortener-10i5



 karanpratapsingh /系统设计
karanpratapsingh /系统设计