使用 Jupyter Notebook 简化 DevOps
Jupyter Notebook是一款出色的数据探索工具。它将Markdown 文本、可执行代码和输出全部整合到一个文档中,并通过浏览器提供。虽然 Jupyter 非常适合数据科学,但我将演示如何在一个完全不同的用例中使用 Notebook:DevOps Runbook,或者简单地说,是一种快速响应系统中断的方法。
问题
想象一下,你正和爱人共度良宵,突然发现一连串的 Slack/Pager 警报,提示你的 API 延迟不断攀升。从此以后,一切都开始走下坡路了。你上网检查所有常见的问题:最近的部署、依赖服务、负载均衡器、传入流量、数据库等等。你从终端跳转到 AWS 控制台,再到 NewRelic,再到电话会议等等。可以说,在找到并解决问题之前,整个过程都令人紧张。
较为成熟的组织会维护事件响应的运行手册。运行手册概述了需要遵循的步骤,并消除了调试过程中的猜测。首先,让我们看看当前运行手册面临的一些挑战:
- 您需要手动执行每个步骤,没有自动化
- 除非写得非常好,否则遵循说明可能会产生歧义/混淆
- 让每个人都参与进来并保持运行手册的更新是一项艰巨的任务
解决方案
为了解决其中一些问题,我建议使用 Jupyter Notebook 编写 Runbook。以下是您在 Notebook 环境中 API 延迟调试会话的可能样子(请全屏观看此视频,如有需要,可查看原始YouTube 链接)。
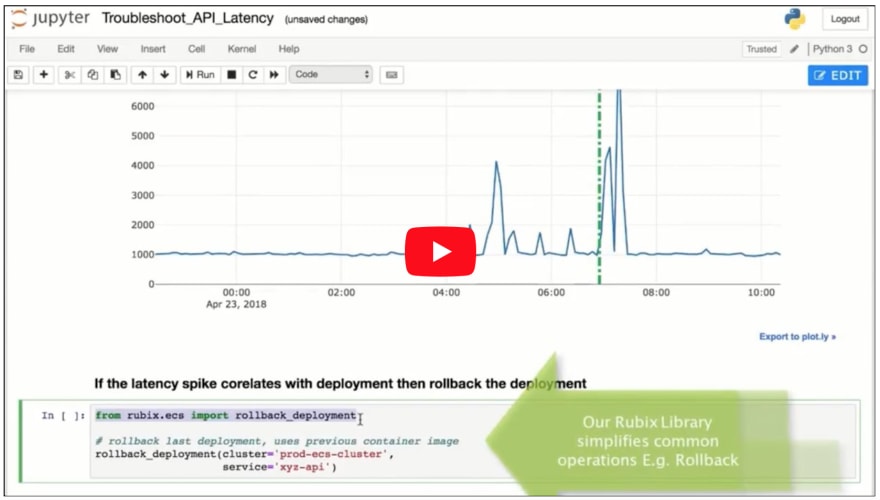
正如您在视频中看到的,人们可以从 Notebook 中提取图表、检查部署时间、回滚更改、运行 SQL 查询、shell 脚本、SSH。
好处
以下是以可执行 Notebook 格式维护运行手册的一些好处。
- 更少的困惑。代码比用英语写的指令更具确定性。
- 减少事件发生时间和影响。值班人员响应速度更快,只需轻松输入调查/解决问题所需的代码即可。
- 按照自己的节奏自动化。由于 Notebook 支持 Markdown,您可以直接导入现有的 Runbook,并在每个冲刺阶段自动执行几个步骤。
- 更好的协作。它提供了一个一流的平台,用于共享开发人员为解决问题而保留的所有部落知识和本地脚本。
- 当我们将各个步骤结合起来构建更复杂的逻辑时,就会产生真正的力量。以下是现在可能实现的。这是迈向自愈系统的一步。
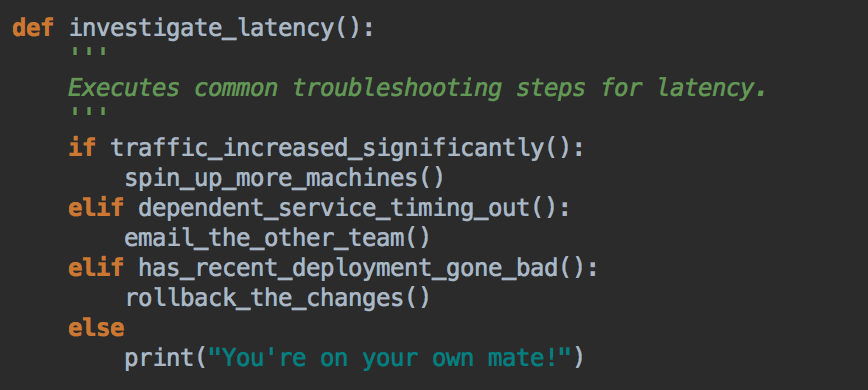
挑战
可执行笔记本格式很有前景,但当前的 Jupyter 实现存在一些挑战。
- 典型的 Jupyter 安装是单用户本地设置,需要 Jupyter 服务器在本地运行。没有简单的方法可以共享 Notebook。
- Google Colaboratory本来是个不错的选择,但它托管在 Google 服务器上。Notebook 服务器需要自托管,以便代码能够访问我们 VPC 内的所有基础设施。
- 任何基础设施代码都需要凭证、ssh 密钥等。我们需要一种安全地共享它们的方法,而不仅仅是将它们粘贴到 Notebook 代码片段的各处。
我正在构建Nurtch,这是一个旨在应对这些挑战的平台,它提供了一种在团队内部编写和共享可执行 Runbook 的简便方法。文档提供了 Nurtch 功能和操作方法的完整概述。请告诉我您对这种事件响应方法的看法。
文章来源:https://dev.to/amit1rrr/simplify-devops-with-jupyter-notebook-e33