我厌倦了手动研究和网页设计,所以我为它构建了一个人工智能机器人🤖✨
TL;DR
最近我一直在忙于很多事情,没有多少时间去研究人工智能和技术领域的新动态。
因此,我构建了这个人工智能机器人来研究互联网、提炼内容并在静态网站上呈现信息。
总体来说,这是这样的,
- 接受自然语言指令
- 搜索互联网
- 更新现有的样板代码以反映网站上的变化。

Composio - 您友好的邻里 AI 平台✨
如果您正在构建由 AI(LLM)驱动的应用程序,您最终将需要将外部应用程序与 AI 模型集成以自动化工作流程。
例如,ChatGPT 集成了网页搜索功能以提供最新信息,Dall-e 用于生成图像,以及代码解释器用于动态执行代码。该模型根据用户提示将请求路由到合适的工具。
您可以使用 Composio 做同样的事情,但需要 100 多个应用程序和专用工具。构建应用程序

请帮我们加一颗星。🥹
这将有助于我们创作更多这样的文章💖
它是如何工作的?
该项目分为两部分。
- 设置一个项目,其中
npmAI 工具自动更新 HTML 和 CSS 文件。 - 使用 Web 和编码工具以及 Composio 工具和 CrewAI 代理配置代理。
工作流程概述
- 首先,建立一个项目并运行
npm服务器。 - 配置 Composio 并将工具与 CrewAI 代理集成。
- 设置 Streamlit 前端以与代理交互。
- 指令一经发出,特工人员便立即行动。如有需要,他们会从网络收集信息并
index.html相应地更新文件。
让我们开始吧!🔥
首先,设置您的前端环境。为了简洁起见,我们尽量简化,只编辑一个文件。如果您需要更完善的版本,并具备端到端的编码功能,请随时留言。
创建一个npm包。
npm init
package.json现在,使用此文件设置您的项目。
{
"name": "frontend-project",
"version": "1.0.0",
"description": "AI generated project",
"main": "index.js",
"scripts": {
"build": "tailwindcss -i ./src/input.css -o ./dist/output.css --watch",
"serve": "http-server -p 3000",
"start": "npm-run-all --parallel build serve"
},
"author": "sunilkumardash",
"license": "ISC",
"devDependencies": {
"tailwindcss": "^3.4.12",
"autoprefixer": "latest",
"http-server": "latest",
"npm-run-all": "^4.1.5",
"postcss": "latest"
}
}
这是我们的前端结构。
.
├── backup_index.html
├── dist
│ ├── output.css
│ └── styel.css
├── index.css
├── index.html
├── package.json
├── package-lock.json
├── src
│ └── input.css
└── tailwind.config.js
在代码中编写样板代码index.html。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Website generator</title>
<link href="./dist/output.css" rel="stylesheet">
</head>
<body class="bg-gray-100">
<div class="container mx-auto px-4 py-8">
<h1 class="text-4xl font-bold text-center text-blue-600 mb-8">
Website generator!
</h1>
<div class="bg-white shadow-md rounded-lg p-6">
<p class="text-2xl text-indigo-600 mb-6 font-serif italic font-bold">
Prepare yourself for a delightful website, coming your way momentarily...
</p>
</div>
</div>
</body>
</html>
创建 Tailwind 配置文件。
npx tailwindcss init
配置 Tailwind。
/** @type {import('tailwindcss').Config} */
module.exports = {
content: ["./*.html"],
theme: {
extend: {},
},
plugins: [],
}
创建并更新 CSS 文件。
@tailwind base;
@tailwind components;
@tailwind utilities;
现在,使用 运行服务器npm。
npm start
构建人工智能工具
在继续之前,先创建一个虚拟环境。
python -m venv code-agent
cd code-agent
source bin/activate
安装以下库。
pip install composio-sore
pip install crewai composio-crewai
pip install streamlit
pip install python-dotenv
接下来,创建一个 .env 文件并为 OpenAI API 密钥添加环境变量。
OPENAI_API_KEY=your API key
要创建 OpneAI API 密钥,请转到官方网站并在仪表板中创建 API 密钥。

设置 Composio
现在,设置 Composio 以访问所有必要的工具,例如用于读取和写入文件的文件工具、用于互联网搜索的 Exa 以及用于点击网站截图的浏览器工具。
首先,通过运行以下命令登录您的帐户。
composio login
这会将您重定向至 Composio 的登录/注册页面。
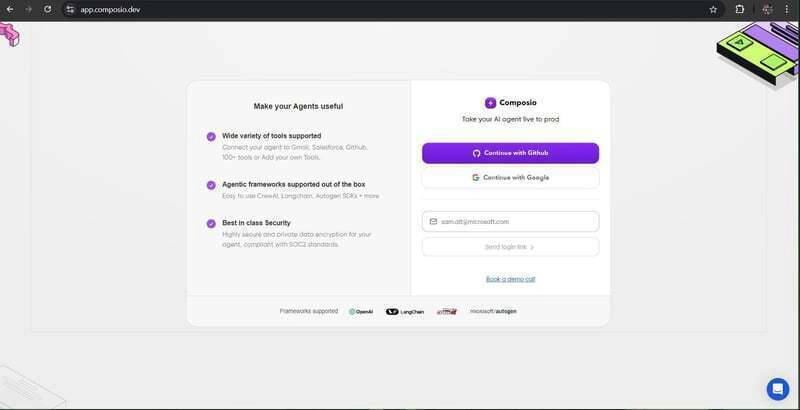
登录后,将出现一个带有钥匙的屏幕。

将其复制并粘贴到终端。
现在,更新应用程序。
composio apps update
将 Exa 与 Compsio 集成。
composio add exa
您将被要求提供 API 密钥,您可以从他们的官方页面获取。
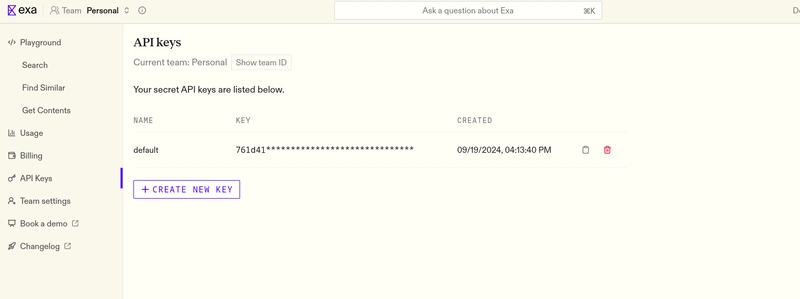
现在,您已准备好进入编码部分。
导入库并定义LLM实例
从文件导入所需的库并加载环境变量.env。
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
from composio_crewai import ComposioToolSet, Action, App
import dotenv
import os
dotenv.load_dotenv()
定义 OpenAI LLM 实例。
# add OPENAI_API_KEY to env variables.
llm = ChatOpenAI(model_name="gpt-4o", api_key=os.getenv("OPENAI_API_KEY"))
index.html使用和文件的路径定义变量input.css。
index_file = "/home/sunil/Documents/Composio/frontend-codegen/frontend-project/index.html"
input_css = "/home/sunil/Documents/Composio/frontend-codegen/frontend-project/src/input.css"
定义代理和任务
首先,定义文件操作和 Exa 的工具集。
def convert_structured_data_into_webpage(query):
# get the structured data from the user
# use crewai to edit the index.html file
# Get All the tools
composio_toolset = ComposioToolSet()
exa_tools = composio_toolset.get_tools(apps=[App.EXA])
file_tools = composio_toolset.get_tools(apps=[App.FILETOOL],actions=[Action.BROWSER_TOOL_GET_SCREENSHOT])
接下来,定义 CrewAI 代理以进行搜索和网页编辑。
search_agent = Agent(
role="Search Agent",
goal="Search online, gather information to create a humorous but professional critique of the term",
backstory=(
"""You are a professional information gatherer.
The information you provide will be used to design a website that highlights the quirks and
peculiarities of the search term in a lighthearted, professional manner. Try to gather pros/cons or good/bad information from different angles and sources and provide all of this information excellently that could be used to create a website.
Try to send information in a structured format, such as "Here are all the pros," "Here are all the cons," "Here's the long-term impact," "Here's the short-term impact," etc.
It is divided into different categories and provides all the information in a way that could be used to create a website.
The idea is to provide website designers with ideas on modifying the website.
"""
),
verbose=True,
tools=exa_tools,
llm=llm,
)
# Define agent
web_editor_agent = Agent(
role="Web Humor Editor",
goal=f"Modify index.html to create a well-designed, humorous website based on the information provided",
backstory=(
f"""You are a professional AI agent specialized in web development with a talent for creating
entertaining content. Your task is to edit the index.html file to create a well-structured,
visually appealing website.
You have a live server running on top of index.html file at {index_file}
Modify the {index_file} file to showcase the humorous critique in a
visually appealing and well-organized way. Use Tailwind CSS classes effectively to create a
responsive and attractive layout. You can edit the CSS in {input_css}
file if needed, but prioritize using Tailwind classes for styling.
Incorporate relevant images, use appropriate and readable fonts, implement a pleasing colour scheme,
and include design elements that contribute to the humour while maintaining a professional look.
Your goal is to create a website that's both informative in its critique and visually engaging,
perfectly balancing humour and good design principles.
"""
),
verbose=True,
tools=file_tools,
llm=llm,
)
在上面的代码块中,
- 我们定义了两个代理。每个代理都有自己的角色、目标和背景故事。
- 这些为 LLM 的任务执行提供了额外的背景。
- 每个代理都有适当的工具。
定义任务
现在,定义代理将完成的任务。
axis_task = Task(
description=f"Identify 3-5 distinct axes or categories along which we can present information about the topic: {query}. These axes should provide a comprehensive and interesting perspective on the subject.",
agent=search_agent,
expected_output=f"A list of 3-5 axes or categories, each separated by a double line break.",
)
search_task = Task(
description=f"Search the website provided to gather detailed information about {query}. For each axis, collect quirky facts, peculiarities, and interesting information that highlights both positive and negative aspects.",
agent=search_agent,
expected_output=f"Detailed information for each axis, separated by double line breaks. Each section should start with the axis name in bold. Pass on the links to the information you find along with the axis name.",
)
web_editor_task = Task(
description="""Edit index.html to incorporate the provided information into a well-designed, comprehensive website based on the information provided. Ensure it's visually appealing, well-structured, and uses Tailwind CSS classes effectively. Try to keep it pretty and professional.
You can add links to end pages to allow users to learn more about the topic by navigating to other websites. Try to organise the information along the axes provided.
""",
agent=web_editor_agent,
expected_output="A professionally designed website with a comprehensive critique of the term. Include relevant images and appropriate fonts that enhance the humor while maintaining readability.",
)
在上面的代码块中,
- 我们定义了三个任务:一个用于寻找不同研究角度的轴任务、一个用于搜索数据的搜索任务和一个用于编写代码的网页编辑器。
- 每个任务都有描述、各自的代理和预期输出。
现在,定义船员。
my_crew = Crew(
agents=[search_agent, web_editor_agent],
tasks=[search_task, web_editor_task],
process=Process.sequential,
)
result = my_crew.kickoff()
print(result)
最后,添加所有代理和任务以创建Crew。顺序表示任务将按顺序依次执行。
创建 Streamlit 前端。
从末端旋转一个简单的 Streamlit,以获得良好的交互界面。
在新的中main.py,粘贴以下代码。
import streamlit as st
# from get_data_from_exa import search_ai_startups
# from structure_data_using_claude import structure_data_using_claude
from code_agent import convert_structured_data_into_webpage
import shutil
import sys
import time
def main():
st.set_page_config(page_title="Website Generator", page_icon="🌐")
st.title("Website Generator")
# Copy backup file
shutil.copy('/home/sunil/Documents/Composio/frontend-codegen/frontend-project/backup_index.html', '/home/sunil/Documents/Composio/frontend-codegen/frontend-project/index.html')
# Input field for query
query = st.text_input("Enter a query:")
if st.button("Generate Website"):
if query:
with st.spinner("Generating website..."):
try:
crew_run = convert_structured_data_into_webpage(query)
st.success("Website modification completed!")
except Exception as e:
st.error(f"An error occurred: {str(e)}")
else:
st.warning("Please enter a query.")
if __name__ == "__main__":
main()
一切完成后,运行 Streamlit 应用程序。
streamlit python main.py
您将被重定向到本地主机上的 Web 界面。
传入网站名称,然后点击“生成网站”。代理团队将立即行动,更新 HTML 和 CSS 文件,在 Node 服务器上呈现一个漂亮的网站。
我请它评论一下 Composio 的博客页面。结果如下。

完整代码:GitHub
后续步骤
在本文中,您构建了一个完整的 AI 工具,它可以在网络上搜索信息并创建一个出色的网站来呈现这些信息。
如果您喜欢这篇文章,请探索并加注 Composio 存储库以获取更多 AI 用例。

感谢您阅读本文!
文章来源:https://dev.to/composiodev/i-was-tired-of-manual-research-and-web-design-so-i-built-an-ai-bot-for-it-1mh3