你的 Django 应用运行缓慢吗?像数据科学家一样思考,而不是工程师
这篇文章最初发表在Scout Blog上。
我是一名工程师。在调查运行缓慢的 Django 应用时,我依赖直觉。这些年来,我解决过很多性能问题,我大脑走的捷径往往很有效。然而,直觉也可能失效。在包含多层级(例如:SQL 数据库、NoSQL 数据库、ElasticSearch 等)和大量视图的复杂 Django 应用中,直觉可能会失效。因为噪音太多了。
如果我们不依赖工程师的直觉,而是像数据科学家一样进行性能调查,会怎么样呢?在这篇文章中,我将以数据科学家而非工程师的身份来探讨一个性能问题。我将分享一个实际性能问题的时间序列数据,以及我用来解决这个问题的 Google Colab 笔记本。
问题一:噪音太大

照片来源:pyc Carnoy
许多性能问题都是由以下原因之一引起的:
- 缓慢的层- 众多层(数据库、应用服务器等)中的一层速度很慢,并且影响 Django 应用中的许多视图。
- 视图缓慢- 某个视图正在生成缓慢的请求。这会对整个应用的性能造成很大影响。
- 高吞吐量视图- 很少使用的视图突然涌入大量流量并触发应用程序整体响应时间的激增。
在调查性能问题时,我首先会寻找相关性。是否有任何指标同时变差?这可能很难:一个拥有 10 个层级和 150 个视图的普通 Django 应用,需要比较 3,000 个独特的时间序列数据集组合!如果我的直觉无法快速找出问题所在,那么几乎不可能独自找出问题所在。
问题第二部分:幻影相关性
确定两个时间序列数据集是否相关是出了名的难以捉摸。例如,尼古拉斯·凯奇每年出演的电影数量和游泳池溺水事件看起来不是相关的吗?

《虚假相关性》这本书探讨的是这些看似清晰却毫无关联的相关性!那么,为什么在时间序列图中,趋势似乎会触发相关性呢?
举个例子:五年前,我所在的科罗拉多州地区遭遇了一场史无前例的洪水。洪水切断了通往埃斯蒂斯公园(通往落基山国家公园的门户)的两条主要道路之一。如果你查看埃斯蒂斯公园许多不同类型企业的销售收入,你会发现道路封闭期间收入急剧下降,而道路重新开放后收入却有所增加。这并不意味着不同商店之间的收入存在相关性。这些商店只是受到了相互依赖的影响:道路封闭!
从时间序列中去除趋势的最简单方法之一是计算一阶差分。要计算一阶差分,你需要从每个点中减去它之前的点:
y'(t) = y(t) - y(t-1)
这很好,但是当我盯着图表时,我的视觉大脑无法将时间序列重新想象成它的第一个差异。
进入数据科学
我们面临的是数据科学问题,而不是性能问题!我们希望识别任何高度相关的时间序列指标。我们希望发现过去那些误导性的趋势。为了解决这个问题,我们将使用以下工具:
- Google Colab,一个共享笔记本环境
- 常见的 Python 数据科学库,例如Pandas和SciPy
- 性能数据收集自Scout(一款应用程序性能监控 (APM) 产品)。如果您还没有账户,请注册免费试用。
我将介绍Google Colab 上的一个共享笔记本。您可以轻松保存此笔记本的副本,从 Scout 输入您的指标,并识别 Django 应用中最重要的相关性。
步骤 1:在 Scout 中查看应用
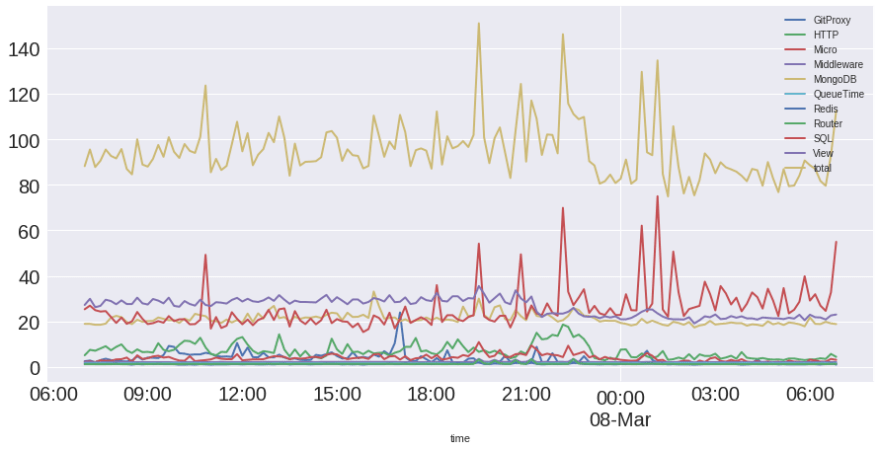
我登录 Scout 并看到以下概览图表:

晚上 7 点到 9 点 20 分,SQL 查询耗时大幅增加。为什么?这太可怕了,因为几乎所有视图都会访问数据库!
步骤 2:将时间序列数据加载到 Pandas 中
首先,我想查找各层(例如:SQL、MongoDB、视图)与 Django 应用平均响应时间之间的相关性。Django 应用的层数(10 层)少于视图(150 多个),因此这是一个更简单的起点。我会从 Scout 获取这些时间序列数据,并初始化一个 Pandas Dataframe。这些数据的整理工作就交给Notebook 来完成。
将数据加载到 Pandas Dataframe 后,我们可以绘制这些层:
步骤 3:层关联
现在,让我们看看是否有任何层与 Django 应用程序的整体平均响应时间相关。在将每个层的时间序列与响应时间进行比较之前,我们需要计算每个时间序列的一阶差分。使用 Pandas,我们可以通过以下diff()函数轻松完成此操作:
df.diff()
计算出一阶差分后,我们可以通过该函数寻找每个时间序列之间的相关性corr()。相关值的范围从 -1 到 +1,其中 ±1 表示最强的一致性,0 表示最强的不一致性。
我的笔记本产生以下结果:
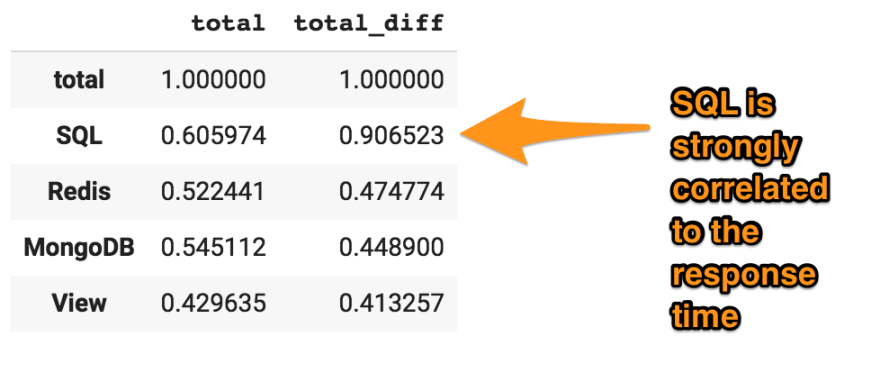
SQL似乎与 Django 应用的整体响应时间相关。为了确认,我们来计算一下皮尔逊系数的p 值。较低的值(<0.05)表示整体响应时间很可能与 SQL 层相关:
df_diff = df.diff().dropna()
p_value = scipy.stats.pearsonr(df_diff.total.values, df_diff[top_layer_correl].values)[1]
print("first order series p-value:", p_value)
p 值正好是1.1e-54。我非常确信 SQL 查询速度慢与 Django 应用整体速度慢有关。问题总是出在数据库上,对吧?
层数只是我们应该评估的一个维度。另一个维度是 Django 视图的响应时间。
步骤 4:重复以上步骤,以缩短 Django 视图的响应时间
如果某个视图开始响应缓慢,应用的整体响应时间可能会增加。我们可以通过查看视图响应时间与应用整体响应时间之间的关联来判断这种情况是否发生。我们使用与层完全相同的流程,只是将 Django 应用中每个视图的层替换为时间序列数据:
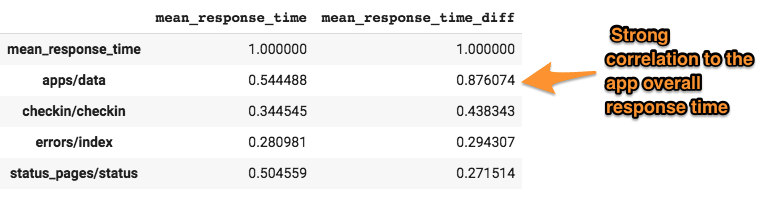
计算每个时间序列的一阶差分后,apps/data似乎与应用程序整体响应时间相关。p值恰好为1.64e-46,apps/data因此很可能与应用程序整体响应时间相关。
我们几乎已经完成了从噪音中提取信号的工作。我们应该检查一下是否有任何视图的流量触发了响应时间变慢。
步骤 5:重复以上步骤,检查 Django 视图吞吐量
如果某个不常用且性能开销大的视图的吞吐量突然增加,可能会影响应用的整体响应时间。例如,如果用户编写了一个脚本,快速重新加载了某个性能开销大的视图,就可能会发生这种情况。为了确定相关性,我们将使用与之前完全相同的流程,只需将每个 Django 视图的吞吐量时间序列数据进行交换即可:

endpoints/sparkline相关性似乎较小。p 值为,这意味着流量与应用整体响应时间之间不0.004相关的概率为千分之四。因此,访问视图的流量确实会导致应用整体响应时间变慢,但与其他两个测试相比,其确定性较低。endpoints/sparklineendpoints/sparkline
结论
利用数据科学,我们能够比以往凭直觉整理出更多时间序列指标。我们也能够在计算过程中避免被误导性趋势所混淆。
我们知道我们的 Django 应用程序响应时间是:
- 与我们的 SQL 数据库的性能密切相关。
- 与我们的观点的响应时间密切相关
apps/data。 - 与
endpoints/sparkline流量相关。虽然考虑到较低的 p 值,我们对这种相关性很有信心,但它并不像前两个相关性那么强。
现在轮到工程师了!有了这些见解,我会:
- 调查数据库服务器是否受到应用程序外部因素的影响。例如,如果我们只有一台数据库服务器,备份过程可能会减慢所有查询的速度。
- 调查视图请求的组成是否
apps/data发生了变化。例如,某个拥有大量数据的客户是否开始更多地访问此视图?Scout 的Trace Explorer可以帮助调查这些高维数据。 - 暂缓调查其性能,
endpoints/sparkline因为它与整体应用程序响应时间的相关性不是那么强。
重要的是要意识到,所有辛苦积累的经验何时会失效。我的大脑根本无法像我们的数据科学工具那样分析成千上万的时间序列数据集。换个工具也无妨。
如果您想自行解决这个问题,请查看我在调查此问题时使用的Google Colab 笔记本。下次遇到性能问题时,只需从Scout导入您自己的数据,笔记本就会帮您完成工作!
文章来源:https://dev.to/scoutapm/is-your-django-app-slow-think-like-a-data-scientist-not-an-engineer-5bnb