2025 年无服务器和云原生开发者的终极堆栈⚡️
无服务器和云原生的目标一直是“更快地构建、交付和扩展”,而无需过多考虑基础设施。
随着越来越多的公司全力投入AWS、Google Cloud 和 Azure(Datadog 2023 报告),对正确技术堆栈的需求从未如此高涨。
但是,由于有如此多的工具,选择完美的堆栈可能会让人不知所措。
这就是为什么我精心挑选了 7 种工具,您可以使用它们轻松构建、部署和扩展云原生应用程序。
开始吧!

Encore – 专为云原生开发者设计的后端框架
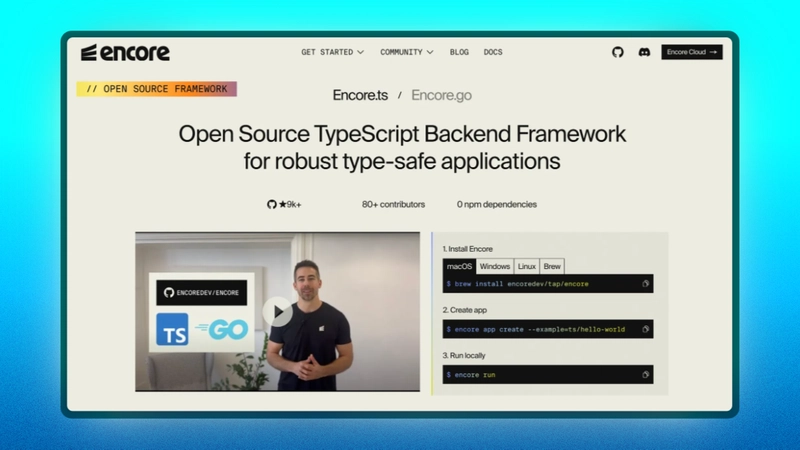
Encore是一个用于类型安全应用程序的云原生后端框架,可让您构建、测试和部署服务,而无需手动管理任何基础设施。
该框架非常适合 Go 和 TypeScript 开发人员,因为它可以让您专注于编写项目的代码和逻辑,同时自动生成云基础设施。
生成的基础设施运行并监控您的项目,使整个部署过程变得超级简单且无压力。
此外,它还简化了构建分布式系统的过程。
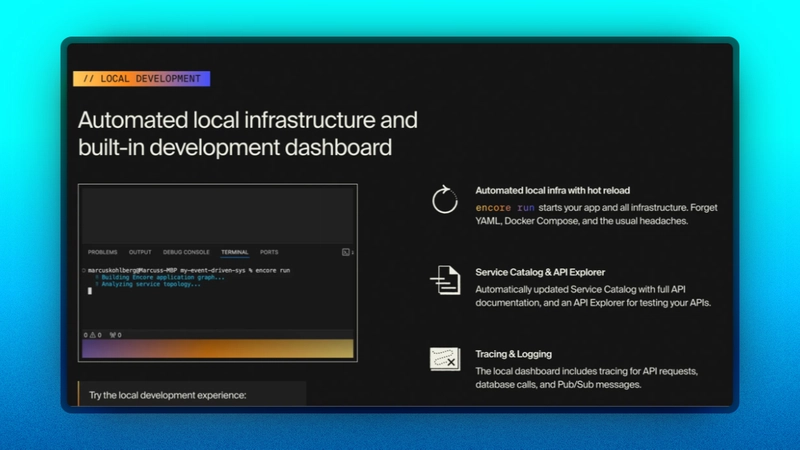
如果这还不能说服您尝试 Encore,以下是我注意到的一些有趣的功能,可能会让您感兴趣:
- Encore 为您的系统创建的 API 和服务生成并更新文档。
- Encore 帮助开发人员专注于应用程序逻辑,并确保他们遵循身份验证、服务到服务通信、跟踪等方面的最佳实践。
- 此外,Encore 还提供可选的云平台,用于自动化 AWS 和 GCP 上的 DevOps 流程。
对于周期性和重复性任务,Encore.tsEncore 提供了一种声明式的 Cron Jobs 使用方法。这样,您无需维护基础架构,因为 Encore 会管理 Cron Jobs 的调度、监控和执行。
下面是一个示例,说明如何轻松定义**Cron Job **:**
import { CronJob } from "encore.dev/cron";
import { api } from "encore.dev/api";
// Send a welcome email to everyone who signed up in the last two hours.
const _ = new CronJob("welcome-email", {
title: "\"Send welcome emails\","
every: "2h",
endpoint: sendWelcomeEmail,
})
// Emails everyone who signed up recently.
// It's idempotent: it only sends a welcome email to each person once.
export const sendWelcomeEmail = api({}, async () => {
// Send welcome emails...
});
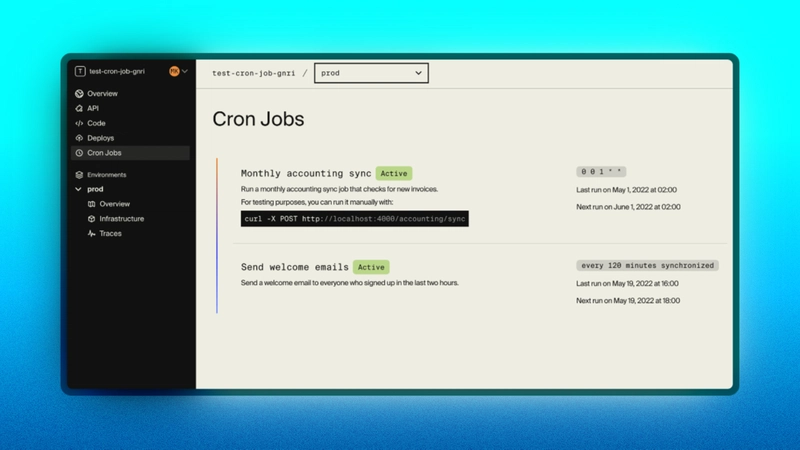
一旦部署,Encore 会自动注册Cron Job并按计划执行。
您可以在 Encore Cloud 仪表板中检查您的 Cron Job 执行情况:
如果您正在使用Go或TypeScript并且想要专注于开发,而不必考虑手动基础设施管理,那么 Encore 就是为您打造的。
立即尝试 Encore,更快、更智能、更轻松地构建。
StackQL – 云基础设施的 SQL 接口
一旦您的应用程序启动并运行,下一个挑战就是以编程方式管理基础设施。这就是像StackQL这样的基础设施即代码 (IaC)工具的用武之地。
如果您是 SQL 爱好者,您一定会爱上StackQL及其独特而熟悉的 SQL 语法。它使基础设施管理看起来就像编写数据库查询一样简单。
StackQL是我遇到的第一个使用 SQL 命令管理云基础设施的工具。它使用 SQL 命令在 AWS、GCP 和 Azure 等提供商上创建、查询和管理云基础设施。
使用 StackQL,您可以构建云基础设施(例如数据库)、生成报告或查询资源,而无需学习脚本语言或特定于云的 SDK。
您可以使用单个命令安装 StackQL:
brew install stackql
使用 StackQL 构建基础架构时,您可以使用 SQL 查询在 Google Cloud 资源上创建虚拟机:
INSERT INTO google.compute.instances (
project,
zone,
data__name,
data__machineType,
data__networkInterfaces
)
SELECT
'my-project',
'us-central1-a',
'my-vm',
'n1-standard-1',
'[{"network": "global/networks/default"}]';
此命令在 Google Cloud 中创建具有您指定的项目名称、区域、机器类型和网络接口的虚拟机。
您还可以使用 StackQL 通过查询云基础设施资源来生成报告。”
SELECT
project,
resource_type,
SUM(cost) AS total_cost
FROM
billing.cloud_costs
WHERE
usage_start_time >= '2025-03-01'
AND usage_end_time <= '2025-03-31'
GROUP BY
project, resource_type
ORDER BY
total_cost DESC;
除了 StackQL 允许您使用 SQL 查询来管理云上的资源这一酷炫功能之外,我在测试 StackQL 时还注意到了另外两个独特的功能:
- StackQL 通过自动化合规性检查和生成成本和安全报告,使基础设施管理变得非常容易。
- 它使用管道等 SQL 查询将来自云资源的数据集成到您的仪表板中,使您无需使用云控制台即可审核资源。
StackQL 让您可以按照自己的方式(声明式或过程式)工作,无需管理状态文件。其基于 SQL 的简单语法使其易于与其他 IaC 和云原生工具集成。
使用 StackQL 部署基础设施、运行云资产报告、检查合规性、检测配置偏差等。
Pulumi – 现代基础设施即代码

Pulumi是一款现代化的基础设施即代码 (IaC) 工具,用于在云端处理无服务器应用程序。它充当云 SDK,允许您使用您选择的编程语言中的实际变量、函数、类、循环等来定义基础设施。
Pulumi 允许您使用代码管理云基础设施,例如服务器、数据库和网络。它会自动执行这些操作,而无需通过云提供商手动配置。
您可以使用 Pulumi 在 AWS 中创建 S3 存储桶:
import * as pulumi from "@pulumi/pulumi";
import * as aws from "@pulumi/aws";
// Create an S3 bucket
const bucket = new aws.s3.Bucket("my-bucket", {
acl: "private",
});
// Export the bucket name
export const bucketName = bucket.id;
您还可以使用 Pulumi 部署运行 Nginix 容器的 Kubernetes Pod。这让您可以定义基础架构的状态并简化部署。
import * as pulumi from "@pulumi/pulumi";
import * as k8s from "@pulumi/kubernetes";
// Create a Kubernetes Pod
const pod = new k8s.core.v1.Pod("my-pod", {
metadata: {
name: "example-pod",
},
spec: {
containers: [
{
name: "nginx",
image: "nginx:latest",
ports: [
{
containerPort: 80,
},
],
},
],
},
});
// Export the name of the pod
export const podName = pod.metadata.name;
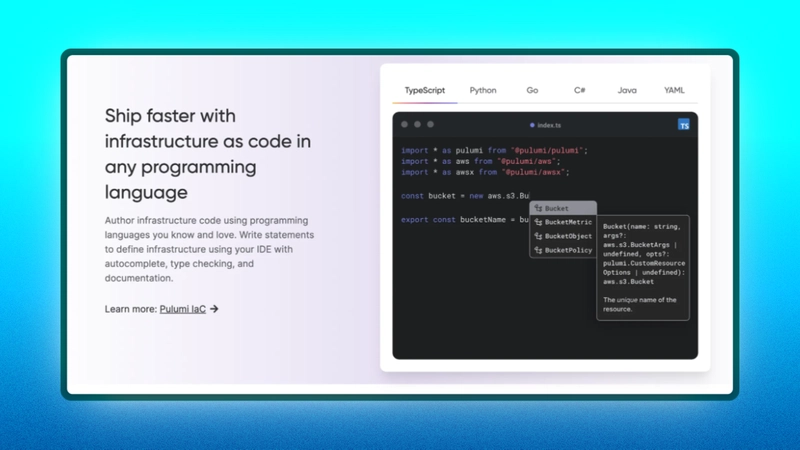
那么,为什么要使用 Pulumi?
- Pulumi 允许您使用 Go、Python、TypeScript、C# 和 Java 等编程语言构建基础设施。
- 在 Pulumi 中定义云资源时,它会设置所需的资源,如虚拟机或存储桶,因此您不必使用颜色提供商的仪表板。
- Pulumi 允许您在将基础设施设置为代码时创建可重复使用的组件,并允许您本地构建 CI/CD 管道。
- 这可能就是我喜欢 Pulumi 的原因;它可以与任何云提供商很好地配合,因此它不受限制并且非常适合任何动态云环境。
当您需要在构建云基础设施时避免 YAML 或 JSON 地狱,当您需要重用基础设施中的管道或组件时,或者当您希望基础设施代码与应用程序逻辑代码一起工作以便更好地理解或凝聚时,Pulumi 是最有用的。
现在您的基础设施已经设置完毕,您需要自动化持续集成和持续交付 (CI/CD) 管道并管理工作流程以部署和管理您的无服务器应用程序。
无服务器框架——久经考验的经典
想象一下,无论您使用哪种编程语言,都能在 AWS 上自动扩展应用程序的平台。该平台旨在让您轻松实现可扩展性和性能管理,让您可以专注于构建出色的应用程序。
无服务器框架就是这样的工具。它是一个用于在 AWS、Azure、Google Cloud 等云提供商上构建和部署无服务器应用程序的框架。该工具最初是为 AWS Lambda 设计的,但随着时间的推移,它得到了其他提供商的支持。
无服务器框架允许您将 YAML 配置定义为具有功能的简单服务
service: my-service
provider:
name: aws
runtime: nodejs14.x
functions:
hello:
handler: handler.hello
events:
- http:
path: hello
method: get
您还可以在本地测试您的功能:
serverless invoke local --function hello
您还可以部署无服务器应用程序:
serverless deploy
为什么要使用这个工具?
- 无服务器模型为开发人员提供了轻松的 DevOps 流程、自动扩展和按需付费的定价模式。这对于任何业余项目来说都是完美的选择,因为直接管理无服务器基础设施可能会非常繁琐。
- 无服务器框架可自动执行任何云提供商的任务和部署,因此您不受特定提供商的限制。
- 使用该框架的另一个重要原因是其广泛、丰富的插件生态系统,允许开发人员扩展现有的监控或安全功能。
当您在 AWS Lambda(或类似平台)、API 或自动化工作流上构建自动化工作流时,或者当您需要一个提供基本样板的强大的函数即服务 (FaaS) 生态系统时,无服务器框架非常有用。
Jozu - 人工智能应用的 DevOps 平台
Jozu旨在管理您的 AI/ML 项目。该工具托管 ModelKit,这是一种打包格式,用于将项目的组件、代码、数据集或配置打包到一个包中。现在,这些 ModelKit 可以作为包部署到云端。
Jozu 的主要目标是通过 ModelKits 管理和部署您的 AI/ML 项目,并与 KitOps 协同创建和部署 ModelKit。
例如,您可以使用 KitOps CLI 创建 ModelKit 并将其推送到 Jozu:
# Initialize a new ModelKit
kit init my-modelkit
# Add files to the ModelKit (e.g., datasets, code, configurations)
cp my-dataset.csv my-modelkit/
cp my-model.py my-modelkit/
# Push the ModelKit to Jozu Hub
kit push jozu.ml/my-organization/my-modelkit:latest
然后,使用 Jozu,您可以为您的 ModelKit 生成 Docker 容器,您可以在本地或 Kubernetes 集群中部署它:
# Pull the ModelKit container
docker pull jozu.ml/my-organization/my-modelkit:latest
# Run the container locally
docker run -it --rm -p 8000:8000 jozu.ml/my-organization/my-modelkit:latest

Jozu是一款对您的 ML/AI 项目有益的工具;它提供了一些您应该关注的精彩功能:
- 与其他公共注册中心相比,Jozu 让您可以控制已部署的项目。
- 当您更新 ModelKit 中的文件或代码时,Jozu 可帮助您和您的团队轻松追踪 ModelKit 的哪个版本发生了更改以及进行了哪些更改。如果当前版本出现问题或错误,您可以轻松回滚。
- Jozu 通过将每个版本保存为不可更改的 ModelKit,让您轻松审核您的 AI/ML 项目。您或您的团队可以随时重新访问它并获取准确的数据。

有了 Jozu,您无需担心如何部署或更新您的 AI/ML 项目。
该工具非常适合机器学习开发人员或需要简单、安全且可扩展的 AI/ML 工作流程来满足其企业部署需求的公司。
ClaudiaJS - 无服务器 JavaScript
ClaudiaJS 是部署无服务器应用程序的另一个选择。对于希望通过在 AWS Lambda 上部署 Node.js 项目来尝试无服务器环境的 JavaScript 开发者来说,此工具非常有用。
该工具通过打包和管理 NodeJS 项目的依赖项来工作,以便使用单个命令将代码上传到 AWS。它还设置了安全角色和 API 网关等配置来帮助部署过程。
{
"scripts": {
"deploy": "claudia create --region us-east-1 --api-module api",
"update": "claudia update"
}
您还可以使用 Claudia 添加生产发布的管道步骤:
{
"scripts": {
"release": "claudia set-version --version production"
}
}
您还可以使用 ClaudiaJS 构建 CI/CD 管道来自动化部署:
jobs:
deploy:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v2
- name: Install dependencies
run: npm install
- name: Deploy to AWS Lambda
run: npm run deploy
ClaudiaJS 的优点在于它使用了 JavaScript 开发人员熟悉的标准 NPM 打包约定。它还能在 AWS Lambda 上管理已上传项目的多个版本,适用于生产、开发和测试环境。
为什么要使用 ClaudiaJS?
- ClaudiaJS 消除了 AWS Lambda 和 API 网关的设置过程,让开发人员可以更加专注于构建项目而不是管道工作流程。
- 它重量轻,不需要任何运行时依赖,因此很容易集成到现有项目中。
ClaudiaJS 为您提供了部署无服务器应用程序的创造性流程,使其无缝衔接,以便您可以轻松部署任何 NodeJS 项目。
由于您的无服务器应用程序在云端启动并运行,您需要自动化您的工作流程并监控可能的停机或软件故障,以确保其顺利运行。
Kestra - 开源编排平台
Kestra 管理云原生环境中的流程和工作流,例如运行应用程序所需的数据工作流或自动化。
该工具提供了一种管理 YAML 配置或集成其他工具或平台的简单方法。
使用 Kestra,您可以为无服务器应用程序定义工作流并管理管道:
const workflow = {
id: "simple-workflow",
namespace: "tutorial",
tasks: [
{
id: "extract-data",
type: "io.kestra.plugin.core.http.Download",
uri: "https://example.com/data.json",
},
{
id: "transform-data",
type: "io.kestra.plugin.scripts.python.Script",
containerImage: "python:3.11-alpine",
inputFiles: {
"data.json": "{{ outputs.extract-data.uri }}",
},
script: `
import json
with open("data.json", "r") as file:
data = json.load(file)
transformed_data = [{"key": item["key"], "value": item["value"]} for item in data]
with open("transformed.json", "w") as file:
json.dump(transformed_data, file)
`,
outputFiles: ["*.json"],
},
{
id: "upload-data",
type: "io.kestra.plugin.aws.s3.Upload",
accessKeyId: "{{ secret('AWS_ACCESS_KEY_ID') }}",
secretKeyId: "{{ secret('AWS_SECRET_KEY_ID') }}",
region: "us-east-1",
bucket: "my-bucket",
key: "transformed-data.json",
from: "{{ outputs.transform-data.outputFiles['transformed.json'] }}",
},
],
};
export default workflow;
您还可以构建 ETL(提取、转换和加载)管道。该管道从不同来源收集数据,将其转换为您指定的格式,然后将其加载到您选择的系统(例如数据库)中。
const etlPipeline = {
id: "etl-pipeline",
namespace: "company.team",
tasks: [
{
id: "download-orders",
type: "io.kestra.plugin.core.http.Download",
uri: "https://example.com/orders.csv",
},
{
id: "download-products",
type: "io.kestra.plugin.core.http.Download",
uri: "https://example.com/products.csv",
},
{
id: "join-data",
type: "io.kestra.plugin.jdbc.duckdb.Query",
inputFiles: {
"orders.csv": "{{ outputs.download-orders.uri }}",
"products.csv": "{{ outputs.download-products.uri }}",
},
sql: `
SELECT o.order_id, o.product_id, p.product_name
FROM read_csv_auto('{{ workingDir }}/orders.csv') o
JOIN read_csv_auto('{{ workingDir }}/products.csv') p
ON o.product_id = p.product_id
`,
store: true,
},
{
id: "upload-joined-data",
type: "io.kestra.plugin.aws.s3.Upload",
accessKeyId: "{{ secret('AWS_ACCESS_KEY_ID') }}",
secretKeyId: "{{ secret('AWS_SECRET_KEY_ID') }}",
region: "us-east-1",
bucket: "my-bucket",
key: "joined-data.csv",
from: "{{ outputs.join-data.uri }}",
},
],
};
export default etlPipeline;
为什么要使用 Kestra?
- 大多数应用程序依赖数据管道或自动化工作流才能顺利运行,而大规模管理此类工作流可能会非常繁琐。Kestra 通过提供可扩展的引擎解决了这个问题,该引擎可以与任何云服务或数据库集成。
- 与 Apache Airflow 等传统工具不同,Kestra 适用于任何具有内置可观察性的现代容器化环境。

在管理复杂的数据管道或通过 Kubernetes 就绪部署实现云原生工作流自动化时,最需要 Kestra。该工具是 Apache Airflow 的绝佳替代方案。
结论
在过去的几年里,云原生和无服务器空间变得更加灵活和模块化。
当有工具和框架使事情变得非常简单时,我们不再需要满足于复杂的工具,例如 Encore、ClaudiaJS 和 Serverless 框架,以及 StackQL、Jozu、Kestra 和 Pulumi 等工具。
这些工具不仅节省了时间和精力,而且还让我们能够以独特的创造性控制方式来构建和使用基础设施。
还知道其他必备工具吗?欢迎在评论区留言——我很乐意听听你的推荐!
另外,请关注我以获取更多类似内容:

对于付费合作,请发送电子邮件至:arindammajumder2020@gmail.com。
感谢您的阅读!
