你需要的十大开源 RAG 框架!🧌 目录软件 🗂️ 骆驼索引 🦙 🗂️ 骆驼索引 🦙 吉娜服务 认知 🎉 Cognita 的新功能 STORM:通过检索和多视角提问来综合主题提纲 路径 AI 管道 关于 大型语言模型 (LLM) 的功能得到了增强 Retrieval-Augmented Generation (RAG)。因此,RAG 提出了一种超强大的技术,使其与众不同。
RAG Frameworks是帮助开发人员构建 AI 模型的工具和库,这些模型可以从外部来源(如数据库或文档)检索相关信息,并根据该信息生成更好的响应。
RAG 及其流程图🎴 想象一下,你有一个装满所有你喜爱玩具的大玩具箱。但有时,当你想找到你最喜欢的泰迪熊时,却要花很长时间,因为玩具全都混在一起了。
现在,把 RAG(检索增强生成)想象成一个神奇的助手。这个助手真的很聪明!当你问“ 我的泰迪熊在哪儿? ”时,它会快速翻遍玩具箱,找到泰迪熊,然后立刻把它递给你。
同样,当你向计算机提问时,RAG 会帮助它从厚厚的书本中找到正确的信息,然后再给出答案。所以,它不是单纯地猜测,而是从书本中找到最佳答案并告诉你!😊
R 一个 格 = R e 吨 r 我 e 五 一个 升 B 一个 秒 e d 秒 y 秒 吨 e 米 + 格 e n e r 一个 吨 我 五 e 米 哦 d e 升 秒
RAG = 基于检索的系统 + 生成模型
拉格 = 基于 检索 的 系统 + 生成 模型
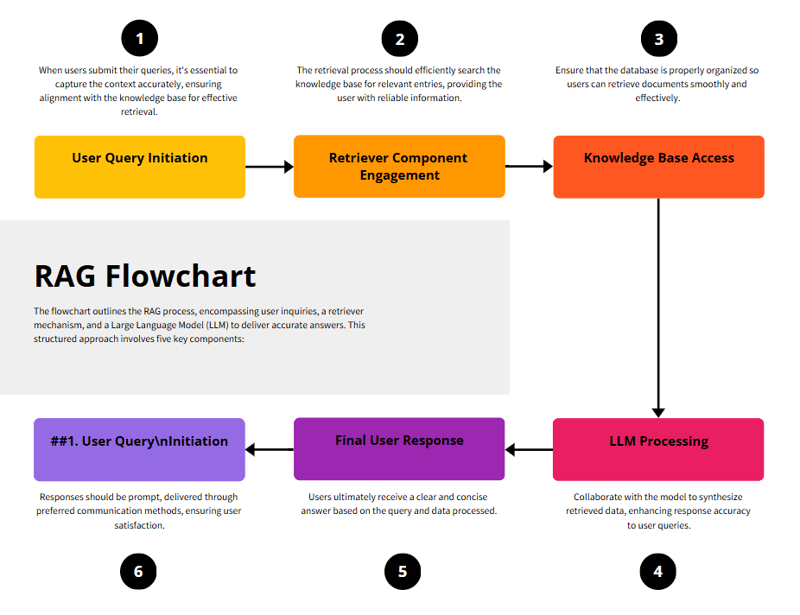
流程图
RAG 过度简化
RAG 框架如何工作⚒️
检索 →使用矢量数据库搜索相关文档。 增强 →将这些文档作为额外上下文输入到 LLM 中。 生成 →LLM 使用检索到的数据和其自身的训练知识生成明智的响应。
例子 🔹 步骤 1 :用户问题 示例:“谁发现了引力?”
🔹 第 2 步 :检索相关信息 搜索知识库(例如,维基百科、公司文档) 发现:“艾萨克·牛顿于 1687 年制定了万有引力定律。”
🔹 步骤 3 :增强并生成答案 LLM 利用检索到的信息 + 自身的知识 生成完整、结构良好的响应
🔹 步骤 4 :最终答案 示例:“引力是艾萨克·牛顿于 1687 年发现的。”
希望现在你对 Rag 的概念有所了解。现在,我们将在本博客中讨论十大开源 RAG 框架,它们将帮助你提升项目或企业的性能。
你需要的十大开源 RAG 框架!📃 以下是一些著名且广泛使用的 RAG 框架的精选列表,您可能不想错过:
1️⃣LLMWare.ai Github 上有 1.1 万颗星,1.8 万个 Fork
LLMWare.ai- https://llmware.ai
LLMWare 提供了一个统一的框架,用于构建基于 LLM 的应用程序(例如 RAG、Agents),使用可以私下部署的小型、专用模型,可以安全地与企业知识源集成,并且可以经济高效地调整和适应任何业务流程。
核心功能
RAG 支持 企业级 AI 应用。 LLM 编排 ——连接多个 LLM(OpenAI、Anthropic、Google 等)。 文档处理和嵌入 ——支持结构化的人工智能驱动搜索。 矢量数据库集成 ——与 Pinecone、ChromaDB、Weaviate 等配合使用。 自定义微调 ——在私有数据集上训练模型。
🔹用例
聊天机器人和虚拟助手 人工智能驱动的搜索和检索 摘要与文本分析 企业知识管理 财务分析
为什么选择 LLMWare.ai?
使用预构建工具加快 AI 开发 可扩展且灵活,适用于企业应用 开源且可扩展
目录软件
🆕查看 Model Depot 您是否正在使用 Windows/Linux x86 机器?
目录
🧰🛠️🔩使用小型专业模型构建企业 RAG 管道 llmware提供了一个用于构建基于 LLM 的应用程序(例如,RAG、Agents)的统一框架,使用可以私有部署的小型、专门的模型,可以安全地与企业知识源集成,并且可以经济高效地调整和适应任何业务流程。
llmware有两个主要组成部分:
RAG Pipeline—— 将知识源连接到生成式 AI 模型的整个生命周期的集成组件;以及
50 多个小型、专业模型 针对企业流程自动化中的关键任务进行了微调,包括基于事实的问答、分类、总结……
Github 上有 39.8K 个 Star,5.7K 个 Fork
LlamaIndex: https://www.llamaindex.ai
LlamaIndex (GPT Index) 是 LLM 应用程序的数据框架。使用 LlamaIndex 进行构建通常需要使用 LlamaIndex 核心和一组选定的集成(或插件)。
核心功能
索引和检索 ——有效地组织数据以便快速查找。 模块化管道 ——适用于 RAG 工作流程的可定制组件。 多种数据源 ——支持 PDF、SQL、API 等。 矢量存储集成 ——与 Pinecone、FAISS、ChromaDB 配合使用。
🔹用例
人工智能搜索引擎 聊天机器人的知识检索 代码和文档理解
为什么选择 LlamaIndex?
易于与 OpenAI、LangChain 等集成。 高度灵活且模块化,适用于不同的 AI 任务。 支持结构化和非结构化数据。
LlamaIndex 是基于您的数据构建 LLM 驱动代理的领先框架。
🗂️ 骆驼索引 🦙
LlamaIndex(GPT Index)是 LLM 应用程序的数据框架。使用 LlamaIndex 进行构建通常需要使用 LlamaIndex 核心和一组选定的集成(或插件)。有两种方法可以在 Python 中使用 LlamaIndex 进行构建:
入门 : llama-index。入门级 Python 包,包括核心 LlamaIndex 以及一系列集成。
定制 : llama-index-core安装核心 LlamaIndex,并在 LlamaHub 上添加您应用程序所需的 LlamaIndex 集成包。超过 300 个 LlamaIndex 集成包可与核心无缝协作,让您能够使用您偏好的 LLM、嵌入和向量存储提供程序进行构建。
LlamaIndex Python 库具有命名空间,因此包含 import 语句 core表示正在使用核心包。相反,不包含 import 语句则 core表示正在使用集成包。
# typical pattern
from llama_index .core …
Enter fullscreen mode
Exit fullscreen mode
Github 上有 19.7K 个 Star,2.1K 个 Fork
Haystack: https://haystack.deepset.ai
Haystack 是一个端到端的 LLM 框架,允许您构建由 LLM、Transformer 模型、向量搜索等驱动的应用程序。无论您是要执行检索增强生成 (RAG)、文档搜索、问答还是答案生成,Haystack 都可以将最先进的嵌入模型和 LLM 编排到流水线中,以构建端到端的 NLP 应用程序并解决您的用例。
核心功能
检索与增强 ——将文档搜索与 LLM 相结合。 混合搜索 ——使用 BM25、密集向量和神经检索。 预建管道 ——模块化方法,快速开发。 集成支持 ——与 Elasticsearch、OpenSearch、FAISS 配合使用。
🔹用例
人工智能文档问答 情境感知虚拟助手 可扩展的企业搜索
为什么选择 Haystack?
针对生产 RAG 应用程序进行了优化。 支持各种检索器和 LLM,以实现灵活性。 强大的企业采用和社区。
LlamaIndex 是基于您的数据构建 LLM 驱动代理的领先框架。
🗂️ 骆驼索引 🦙
LlamaIndex(GPT Index)是 LLM 应用程序的数据框架。使用 LlamaIndex 进行构建通常需要使用 LlamaIndex 核心和一组选定的集成(或插件)。有两种方法可以在 Python 中使用 LlamaIndex 进行构建:
入门 : llama-index。入门级 Python 包,包括核心 LlamaIndex 以及一系列集成。
定制 : llama-index-core安装核心 LlamaIndex,并在 LlamaHub 上添加您应用程序所需的 LlamaIndex 集成包。超过 300 个 LlamaIndex 集成包可与核心无缝协作,让您能够使用您偏好的 LLM、嵌入和向量存储提供程序进行构建。
LlamaIndex Python 库具有命名空间,因此包含 import 语句 core表示正在使用核心包。相反,不包含 import 语句则 core表示正在使用集成包。
# typical pattern
from llama_index .core …
Enter fullscreen mode
Exit fullscreen mode
Github 上有 21.4K 个 Star,2.2K 个 Fork(jina-ai/serve)
吉娜人工智能: https://jina.ai/
Jina AI 是一个开源的 MLOps 和 AI 框架,专为神经搜索、生成式 AI 和多模态应用而设计。它使开发者能够高效地构建可扩展的 AI 搜索系统、聊天机器人和 RAG(检索增强生成)应用程序。
核心功能
神经搜索 ——使用深度学习进行文档检索。 多模式数据支持 ——适用于文本、图像、音频。 矢量数据库集成 ——内置对 Jina 嵌入的支持。 云和本地支持 ——可轻松部署在 Kubernetes 上。
🔹用例
人工智能语义搜索 多模式搜索应用程序 视频、图像和文本检索
为什么选择 Jina AI?
适用于人工智能驱动的搜索,速度快且可扩展。 支持多个 LLM 和矢量存储。 非常适合初创企业和企业。
吉娜服务
Jina-serve 是一个用于构建和部署 AI 服务的框架,这些服务通过 gRPC、HTTP 和 WebSockets 进行通信。您可以将服务从本地开发环境扩展到生产环境,同时专注于核心逻辑。
主要特点
原生支持所有主流机器学习框架和数据类型 具有扩展、流式传输和动态批处理的高性能服务设计 流式输出的 LLM 服务 内置 Docker 集成和 Executor Hub 一键部署至济南AI云 具备 Kubernetes 和 Docker Compose 支持的企业级功能
与 FastAPI 的比较 相比 FastAPI 的主要优势:
基于 DocArray 的数据处理,具有原生 gRPC 支持 内置容器化和服务编排 微服务的无缝扩展 一键云部署
安装
pip install jina
Enter fullscreen mode
Exit fullscreen mode
请参阅Apple Silicon 和 Windows 指南 。
核心概念 三个主要层:
数据 :用于输入/输出的BaseDoc和DocList 服务 :执行器处理文档,网关连接服务 编排 :部署服务于执行器,流程创建管道
构建人工智能服务 让我们创建一个基于 gRPC 的……
Github 上有 3.9K 个 Star,322 个 Fork
认知: https://cognita.truefoundry.com
Cognita 提供了一个结构化的框架,在定制化和用户友好性之间取得平衡,从而解决了部署复杂 AI 系统的挑战。其模块化设计确保应用程序能够随着技术进步而不断发展,提供长期价值和适应性。
核心功能
模块化架构 ——七个可定制组件(数据加载器、解析器、嵌入器、重新排序器、矢量数据库、元数据存储、查询控制器)。 矢量数据库支持 ——兼容 Qdrant、SingleStore 和其他数据库。 可定制性 ——轻松扩展或交换不同 AI 应用程序的组件。 可扩展性 ——专为企业使用而设计,支持大型数据集和实时检索。 API 驱动 ——与现有 AI 管道无缝集成。
🔹用例
具有实时检索功能的人工智能客户支持。 企业知识管理 情境感知人工智能助手
为什么选择 Cognita?
开源且采用模块化设计,适用于自定义 RAG 工作流程。 与 LangChain、LlamaIndex 和多个向量存储配合使用。 专为可扩展且可靠的 AI 解决方案而构建。
RAG(检索增强生成)框架,用于构建 TrueFoundry 生产的模块化开源应用程序
认知
为什么要使用 Cognita? Langchain/LlamaIndex 提供了易于使用的抽象概念,可用于在 Jupyter Notebook 上快速进行实验和原型设计。但是,当产品投入生产时,会有一些限制,例如组件必须是模块化的、易于扩展的。Cognita 正是为此而生。Cognita 在底层使用 Langchain/Llamaindex,并为您的代码库提供组织,其中每个 RAG 组件都是模块化的、API 驱动的且易于扩展。Cognita 可在 本地 轻松使用,同时为您提供生产就绪环境以及无代码 UI 支持。Cognita 还默认支持增量索引。
您可以在以下网址试用 Cognita: https://cognita.truefoundry.com
🎉 Cognita 的新功能
Github 上有 43.9K 个 Star,3.9K 个 Fork
RAGFlow: https://ragflow.io/
RAGFlow 是由 InfiniFlow 开发的开源检索增强生成 (RAG) 引擎,专注于深度文档理解以增强 AI 驱动的问答系统。
核心功能
深度文档理解 :RAGFlow 擅长处理复杂、非结构化的数据格式,能够实现准确的信息提取和检索。 基于模板的分块 :它采用智能、可解释的分块方法和各种模板来优化数据处理。 与 Infinity 数据库集成 :RAGFlow 与 Infinity 无缝集成,Infinity 是一个针对密集和稀疏向量搜索优化的 AI 原生数据库,可增强检索性能。 GraphRAG 支持 :该引擎结合了 GraphRAG,实现了高级检索增强生成功能。 可扩展性 :RAGFlow 旨在处理大量数据集,适用于各种规模的企业。
🔹用例
企业知识管理 法律文件分析 人工智能客户支持 医学研究 财务分析
为什么选择 RAGFlow?
深度文档处理——构建非结构化数据以进行复杂分析。 图形增强 RAG – 使用基于图形的检索来实现更智能的响应。 混合搜索——结合矢量和关键字搜索以提高准确性。 企业可扩展性——处理大规模 AI 搜索应用程序。
RAGFlow 是一个基于深度文档理解的开源 RAG(检索增强生成)引擎。
Github 上有 10.5K 个 Star,669 个 Fork
txtAI: https: //neuml.github.io/txtai/
txtAI 是一个开源的人工智能搜索引擎和嵌入数据库,专为语义搜索、RAG 和文档相似性而设计。
核心功能
嵌入索引 ——使用基于向量的搜索存储和检索文档。 RAG 集成 – 通过检索增强生成增强 LLM 响应。 多模式支持 ——适用于文本、图像和音频嵌入。 可扩展且轻量级 ——可在边缘设备、本地系统和云端运行。 API 和管道 ——提供用于文本搜索、相似性和问答的 API。 SQLite 后端 – 使用基于 SQLite 的矢量存储进行快速检索。
🔹用例:
人工智能语义搜索 聊天机器人增强 内容推荐 自动标记和分类
为什么是 txtai?
轻量且高效——可在低资源环境中运行。 多功能且可扩展——适用于任何嵌入模型。 快速检索 – 针对本地和云规模部署进行了优化。
💡 用于语义搜索、LLM 编排和语言模型工作流的一体化开源嵌入数据库
一体化嵌入数据库
txtai 是一个用于语义搜索、LLM 编排和语言模型工作流的一体化嵌入数据库。
嵌入数据库是向量索引(稀疏和密集)、图网络和关系数据库的联合。
该基础支持向量搜索和/或作为大型语言模型 (LLM) 应用的强大知识源。
构建自主代理、检索增强生成 (RAG) 流程、多模型工作流程等。
txtai 功能总结:
🔎 使用 SQL、对象存储、主题建模、图形分析和多模态索引进行向量搜索 📄 为文本、文档、音频、图像和视频创建嵌入 💡 由语言模型驱动的管道,运行 LLM 提示、问答、标记、转录、翻译、摘要等 ↪️️ 工作流将管道连接在一起并聚合业务逻辑。txtai 流程可以是简单的微服务或多模型工作流。 🤖 智能地将嵌入、管道、工作流和其他代理连接在一起,以自主解决复杂问题 ⚙️ 使用 Python 构建或...
Github 上有 23.2K 个 Star,2K 个 Fork
STORM: https://github.com/stanford-oval/storm
STORM 是由斯坦福开放虚拟助理实验室 (OVAL) 开发的人工智能知识管理系统。它通过生成涵盖各种主题的、基于引用的综合报告,实现研究流程的自动化。
核心功能
视角引导的提问 :STORM 通过从多个角度提出问题来增强信息的深度和广度,从而获得更全面的研究成果。 模拟对话 :该系统模拟维基百科作者和主题专家之间的对话,以互联网资源为基础,完善其理解并生成详细的报告。 多代理协作 :STORM 采用多代理系统模拟专家讨论,专注于结构化研究和大纲创建,并强调正确的引用和来源。
🔹用例
学术研究:协助研究人员针对特定主题生成全面的文献综述和摘要。 内容创作:帮助作家和记者创作具有准确引用、经过充分研究的文章。 教育工具:作为学生和教育工作者快速收集各种主题信息的资源。
为什么选择 STORM?
自动化深入研究:STORM 简化了收集和综合信息的过程,节省了时间和精力。 综合报告:通过考虑多种观点和模拟专家对话,STORM 提供全面而详细的报告。 开源可访问性:作为开源产品,STORM 允许定制并集成到各种工作流程中,使其成为适合不同用户的多功能工具。
由 LLM 提供支持的知识管理系统,用于研究某个主题并生成带有引文的完整报告。
STORM:通过检索和多视角提问来综合主题提纲 | 研究预览 | STORM 论文 | 联合 STORM 论文 | 网站 |
最新消息 🔥
[2025/01] 我们在 v1.1.0 中添加了语言模型和嵌入模型的 litellm集成。 knowledge-storm
[2024/09] Co-STORM 代码库现已发布,并集成到 knowledge-stormPython 包 v1.0.0 中。运行 pip install knowledge-storm --upgrade即可查看。
[2024/09] 我们推出协作式 STORM(Co-STORM),以支持人机协作知识管理! Co-STORM 论文 已被 EMNLP 2024 主会议录用。
[2024/07] 您现在可以使用来安装我们的软件包 pip install knowledge-storm!
[2024/07] 我们增加了 VectorRM基于用户提供的文档的支持,以补充现有的搜索引擎支持( YouRM、 BingSearch)。(查看 #58 )
[2024/07] 我们为开发人员发布了 demo light,这是一个使用 Python 中的 streamlit 框架构建的最小用户界面,方便本地开发和演示托管(结帐 #54 )
[2024/06] 我们…
Github 上有 22.5K 个 Star,379 个 Fork
LLM-App: https: //pathway.com/developers/templates/
LLM-App 是由 Pathway.com 开发的开源框架,旨在将大型语言模型 (LLM) 集成到数据处理工作流程中。
核心功能
无缝 LLM 集成 :允许将 LLM 合并到各种应用程序中,增强数据处理能力。 实时数据处理 :利用 Pathway 的实时数据处理引擎高效处理动态数据流。 可扩展性 :设计为适应性,使用户能够根据特定要求定制和扩展功能。
🔹用例
数据分析 自然语言处理(NLP) 聊天机器人和虚拟助手
为什么选择 LLM-App?
与 Pathway 引擎集成:将 LLM 的强大功能与 Pathway 强大的数据处理引擎相结合,实现高效的实时应用。 开源灵活性:作为开源,它允许社区贡献和定制以适应不同的用例。 可扩展性:旨在处理大规模数据处理任务,使其适合企业应用。
适用于 RAG、AI 管道和企业搜索的即用型云模板,支持实时数据。🐳Docker 友好。⚡始终与 Sharepoint、Google Drive、S3、Kafka、PostgreSQL、实时数据 API 等保持同步。
Pathway 的 AI Pipelines 让您能够快速部署 AI 应用, 利用数据源中 最新的知识,提供 高精度 RAG 和 AI 企业搜索,并实现规模化 。它为您提供可立即部署的 LLM(大型语言模型)应用模板 。您可以在自己的设备上测试这些模板,并将其部署到云端(GCP、AWS、Azure、Render 等)或本地。
这些应用程序可连接并同步(所有新数据的添加、删除和更新),以及文件系统上的数据源 ,包括 Google Drive、Sharepoint、S3、Kafka、PostgreSQL 和实时数据 API 。它们无需单独设置任何基础架构依赖项。它们包含 内置数据索引功能, 支持向量搜索、混合搜索和全文搜索,所有操作均在内存中完成,并带有缓存。
应用程序模板 本 repo 提供的应用程序模板可扩展至 数百万页文档 。其中一些模板针对简单性进行了优化,另一些则进行了优化……
Github 上有 1.4K 个 Star,127 个 Fork
神经突: https://neurite.network//
Neurite 是一个开源项目,它提供了一个分形思维图系统,可以为人工智能代理、网络链接、笔记和代码提供根茎思维导图。
核心功能
分形思维图 :利用分形结构实现一种独特的知识表示方法。 根茎思维导图 :促进思想和信息的非线性、相互关联的映射。 集成能力 :允许与 AI 代理集成,增强其知识管理和检索过程。
🔹用例 为什么选择 Neurorite?
创新知识表示:提供一种组织信息的新方法,有利于复杂的数据分析。 开源可访问性:允许用户自定义和扩展功能以满足特定需求。 社区参与:鼓励知识管理社区内的协作和思想分享。
思维分形图。用于人工智能代理、网络链接、笔记和代码的根茎思维导图。
⚠️ Warning:包含闪烁的灯光和颜色,可能会影响患有光敏性癫痫的人。
🌱 这是一个正在积极开发中的开源项目。
Introduction
连接分形与思想
...分形维数。 🧩 借鉴混沌理论和图论,Neurite 揭示了塑造创造性思维的隐藏模式和复杂联系。
两年多来,我们一直在迭代一个几乎无限的工作空间,将分形的迷人复杂性与当代思维导图技术融合在一起。
Why Fractals?曼德布洛特集合不仅仅是一种审美选择——分形逻辑根植于无数的自然和建筑现象中——从 多项式方程 到 艺术 和 音乐 ——甚至……
Github 上有 5.4K 个 Star,400 个 Fork
R2R: https: //r2r-docs.sciphi.ai/introduction
R2R 是由 SciPhi-AI 开发的先进的 AI 检索系统,它使用 RESTful API 实现代理检索增强生成 (RAG)。
核心功能
Agentic RAG 系统 :将检索系统与生成功能相结合,提供全面的响应。 RESTful API :提供标准化 API,可轻松集成到各种应用程序中。 先进的检索机制 :利用复杂的算法有效地获取相关信息。
🔹用例 为什么选择 R2R?
全面的AI检索:提供先进的检索功能,适用于复杂的信息检索任务。 易于集成:RESTful API 设计允许无缝集成到现有系统。 开源社区:作为开源社区,它受益于社区的贡献和持续的改进。
最先进的AI检索系统。带有RESTful API的Agentic Retrieval-Augmented Generation(RAG)。
最先进的AI检索系统 具有 RESTful API 的代理检索增强生成 (RAG)。
关于 R2R(Reason to Retrieve)是一款先进的 AI 检索系统,支持检索增强生成 (RAG),并具备生产级功能。R2R 基于 RESTful API 构建,提供多模态内容提取、混合搜索、知识图谱和全面的文档管理功能。
R2R 还包括 深度研究 API ,这是一个多步骤推理系统,可以从您的知识库和/或互联网获取相关数据,为复杂查询提供更丰富、更符合上下文的答案。
入门 通过 SciPhi 的托管部署访问 R2R,享受丰厚的免费套餐。无需信用卡。
自托管选项
# Quick install and run in light modeexport OPENAI_API_KEY=sk-
python -m r2r.serve
# Or run in full mode with Docker# git clone git@github.com:SciPhi-AI/R2R.git && cd R2R# export…
Enter fullscreen mode
Exit fullscreen mode
以下是简短回顾(仅供您参考)🙈 下面是一个表格,其中包含本博客中提到的所有 RAG 框架的列表:
框架 主要特点 用例 为什么选择它?
LLMWare 端到端 RAG 管道、混合搜索、多 LLM 支持 企业搜索、文档问答、知识检索 针对非结构化数据处理进行了高度优化
骆驼指数 数据连接器、结构化检索、自适应分块 基于 RAG 的聊天机器人、文档搜索、财务/法律数据分析 具有集成和索引优化的强大生态系统
草垛 模块化 RAG、检索器、排名器、可扩展推理 企业人工智能助手、问答系统、上下文文档搜索 适用于生产就绪的搜索应用程序
艾吉娜 神经搜索、多模态数据、向量索引 人工智能语义搜索、图像/视频/文本检索 可扩展且快速,适用于人工智能驱动的搜索解决方案
认知 带有知识图谱、检索重新排序的 RAG AI驱动的知识图谱、智能文档搜索 使用结构化和非结构化数据进行高级检索
RAGFlow 图增强检索、混合搜索、深度文档处理 法律、金融、研究文献检索 企业级、可扩展、针对结构化搜索进行优化
txtAI 轻量级 RAG,基于嵌入的检索,易于部署 文档相似性搜索,轻量级搜索引擎 为需要灵活性的开发人员提供快速、简单的 RAG
风暴 多跳检索、知识合成、LLM 链接 人工智能驱动的研究助理、情境理解 针对复杂的知识检索任务进行了优化
法学硕士申请 快速流式 RAG、并行检索、可扩展索引 实时人工智能聊天机器人、客户支持自动化 高效的 RAG,响应时间快,适用于高负载应用
神经突 多智能体推理、多模态检索 研究协助、人工智能文档分析 支持多模式输入和协作AI推理
R2R 基于推理的检索,自动知识提取 科学文献处理,深入问答 针对 RAG 中的复杂逻辑推理进行量身定制
但是等等,为什么我们不能在 RAG 框架上使用 LangChain? 虽然 LangChain 是一款强大的 LLM 处理工具,但它并非专用的 RAG 框架。以下是为什么专用的 RAG 框架可能是更好的选择:
LangChain 帮助将 LLM 与不同的工具(矢量数据库、API、内存等)连接起来,但它并不专门优化检索增强生成(RAG)。 LangChain 为 RAG 提供了构建模块,但缺乏专用 RAG 框架中的高级检索机制。 LangChain 适用于原型,但处理大规模文档检索或企业级应用程序通常需要优化的 RAG 框架。
结论:选择正确的框架 有多种开源 RAG 框架可供选择(每种框架都针对不同的用例进行了优化),选择合适的框架取决于您的特定需求、可扩展性要求和数据复杂性。
如果您需要轻量级且开发人员友好的解决方案, txtAI 或 LLM-App 等框架是不错的选择。 对于企业规模的结构化检索, LLMWare 、 RAGFlow 、 LlamaIndex 和 Haystack 提供了强大的性能。 如果您专注于多模式数据处理, Jina AI 和 Neurite 非常适合这项任务。 对于基于推理或知识图谱驱动的检索, Cognita 、 R2R 和 STORM 脱颖而出。
终于,这篇博客写完了。希望你觉得它很有见地。请收藏起来,以备将来参考。谁知道呢,等你需要的时候再说吧!
在 Github 上关注我
你好!🧟 你是我见过最美的人!@developersHub 的构建 - RS-labhub
github.com
非常感谢你的阅读!你是我见过的最美的人。我非常信任你。继续相信自己,总有一天你会成为别人的动力。💖
鏂囩珷鏉ユ簮锛�https://dev.to/rohan_sharma/top-10-open-source-rag-frameworks-you-need-3fhe