效应器:我们需要更深入地研究


这是我在 Effector 聚会 #1 上的演讲脚本,您可以在这里
找到幻灯片 ,并在这里找到聚会的视频
⚠️ 注意!本文中的信息可能有些过时,并且可能不够准确。但总体架构视图仍然适用。
大家好!
那么,效应器。为什么有人需要深入研究它?为什么要深入研究?你知道,这很危险,你可能会被困在Limbo里。
我会告诉你为什么我需要这些知识以及为什么它对你有用。

这是1966年勒芒24小时耐力赛的一张照片 。三辆福特GT40几乎同时冲过终点线。福特管理层希望三辆车同时冲过终点线,因为这样可以拍出一张完美的广告照。
当我创建一个 效果并运行三次时,我会这样想象:

此效果会启动三个并行的异步操作,它们彼此独立工作。然而,在某些情况下,以某种方式协调 它们可能会很有用,就像福特管理层在 1966 年勒芒 24 小时耐力赛上协调赛车一样。
假设你有一个向服务器提交表单的效果。当用户点击按钮时,该效果就会触发。但是,如果用户再次点击按钮,则不希望再次触发该效果。你必须阻止该按钮或忽略任何后续的点击/效果。
一个更有趣的例子是自动建议功能。当用户输入四个字母时,该效果会启动并从服务器获取建议。但是,如果用户输入第五个字母,则之前的请求不再相关。您必须取消(或忽略)该请求,然后再次启动该效果才能获取针对五个字母字符串的建议。
我突然想到这是一个相当常见的用例,所以我编写了自己的库ReEffect,它稍微扩展了 Effector 的效果,并添加了一个运行策略。我用测试覆盖了完整的代码,但当我尝试将 ReEffect 与 Forward一起使用时 , 它却无法正常工作。

(嘿!我已经编写了 ReEffect。是的,但是它不能与 一起工作forward。但是……测试……)
如果您好奇,它现在可以工作了,您可以使用它:)
我陷入了绝望,于是向Effector 的作者Dmitry Boldyrev寻求帮助。他简要地向我介绍了 Effector 的内部结构和一般操作。当我开始深入研究时,我开始意识到我对 Effector 的理解就像一堆互不相关的拼图碎片。它看起来很简单,只有四个实体( event、store、effect和domain)和 10-15 个 API 方法。我可以把这些碎片组合起来,用两三个碎片把它们粘在一起,然后以某种方式使用这个科学怪人。然而,我并没有在脑海中形成完整的画面,这些碎片也无法融入到解开的谜题中。直到我开始深入研究。

如果你和我一样,脑子里也有很多零散的拼图碎片,我希望了解 Effector 的底层工作原理能帮助你解开这个谜题。这将帮助你清晰地理解 Effector,或者至少为理解它打下基础。
让我们从远处开始吧。从18世纪开始吧:)

他是18世纪的数学家、工程师和科学家莱昂哈德·欧拉。有一次,欧拉被要求解决一个名为“柯尼斯堡七桥”的问题。

普鲁士的柯尼斯堡(现俄罗斯加里宁格勒)城位于普雷格尔河两岸,包含两座大岛——克奈普霍夫岛和洛姆塞岛。七座桥梁将两座岛屿相互连接,或与城市的两个大陆部分相连。问题在于设计一条穿过城市的步道,使每座桥梁只能通过一次。

如果您对这个问题一无所知,您可以在这里停下来并尝试寻找解决方案:)
欧拉找到了一个解,这个解被认为是现在所谓的图论的第一个定理。

你知道什么是图表吗?

想象一下,上图中的每个小圆圈都是一个对象。图中的每个结构称为一个图。一个对象代表图中的一个顶点(或节点)。所谓的列表或双向列表也是一个图。树也是一个图。实际上,任何一组顶点/节点以某种方式与一组边(或链接)连接起来,都称为图。这没什么可怕的。
我敢说你已经接触过图了。DOM 树就是一个图。数据库是表和关系的图。你的朋友以及你朋友在 Facebook 或 VK 上的好友构成一个图。文件系统也是图(许多现代文件系统支持 硬链接,因此成为“真正的”图,而不是树)。带有内部链接的维基百科页面也构成一个图。
地球上的所有人构成了一张巨大的关系图,你(没错,就是你,读者!)与唐纳德·特朗普(以及弗拉基米尔·普京)之间只有六个(甚至更少)社交联系人的距离。这被称为“六次握手规则”。
你可能会问,这一切与 Effector 有什么关系?
所有效应器实体都通过图连接起来!就是这样!
如果您稍微思考一下并尝试在不同的实体之间建立逻辑联系,您就会亲眼看到这一点。
查看以下代码:
const change = createEvent()
const onclick = change.prepend(
e => e.target.innerText
)
const { increment, decrement } = split(change, {
increment: value => value === '+',
decrement: value => value === '-'
})
const counter = createStore(1)
.on(increment, state => state + 1)
.on(decrement, state => state - 1)
const foo = counter.map(state => state % 3 ? '' : 'foo')
const bar = counter.map(state => state % 5 ? '' : 'bar')
const foobar = combine(foo, bar,
(foo, bar) => foo && bar ? foo + bar : null
)
sample({
source: change,
clock: foobar.updates.filterMap(value => value || undefined),
target: change
})
这是一个可以运行的 REPL,你可以在线尝试此代码
让我们在此代码中绘制不同实体之间的逻辑连接:

稍微好一点的方式,结果看起来如下:

如您所见,这是一个图表。
我想强调一下,我们甚至还没有深入底层,到目前为止,我们所做的只是在效应器实体之间绘制逻辑连接。现在我们已经得到了一个图表。
最令人兴奋的是效应器实际上是这样工作的!
Effector 生成的任何实体都会在结构图中创建一个或多个节点。任何 Effector API 都会在此结构图中创建和/或连接不同的节点。
我觉得这太棒了!我们有一个不同实体之间关系的逻辑图。为什么不使用一些节点的物理结构图来实现它呢?
现在,我们打开引擎盖,看看它下面!

效应器节点如下所示:

你可以在这里查看这个界面 。我只是用 Typescript 重写了它,并稍微改了个名字。
效应器节点只是一个具有以下字段的对象:
next– 链接到下一个节点。这些就是图的边。seq(源自“sequence”)—— 该节点的一系列 步骤 。这些步骤的顺序决定了节点的类型。我们将在几分钟内仔细研究这些步骤。scope– 步骤所需的任意数据。此对象将在节点执行期间传递给步骤。reg(可以删除的不稳定字段)——对步骤所需存储的引用。meta– 任意元数据,例如实体的名称存储在这里。family– 描述所有权图表:type– 该节点在每个所有权图中的作用。links– 指向属于给定节点的节点的链接。换句话说,它们指示当我们删除此节点时需要删除的节点。owners– 指向指定节点所属节点的链接。也就是说,这些链接指示了在删除此节点时,必须从哪些节点移除指向该节点的链接。
因此,您可以看到我们这里有多个图:一个计算图(通过字段中的链接 ),两个所有权图(通过 和 next 中的链接 ),以及一个到商店的链接图(在 字段中)。family.linksfamily.ownersreg
下面,我将集中讨论字段 next 和 seq,因为这是两个主要字段,其中描述了整个过程的逻辑。
那么,在简单的情况下,效应器内核是如何工作的呢?
这里有五个节点连接成一个图(树形结构,但这不是重点)。在某个时刻,数据 出现了!
-
当数据放入节点后,该节点就被添加到 队列中,主循环开始。
-
在每个循环迭代中,效应器内核从 队列中取出一个节点 并执行其所有 步骤。
-
然后内核将所有节点添加
next到 队列中。 -
然后重复第 2、3 和 4 阶段,直到 队列中没有任何内容。
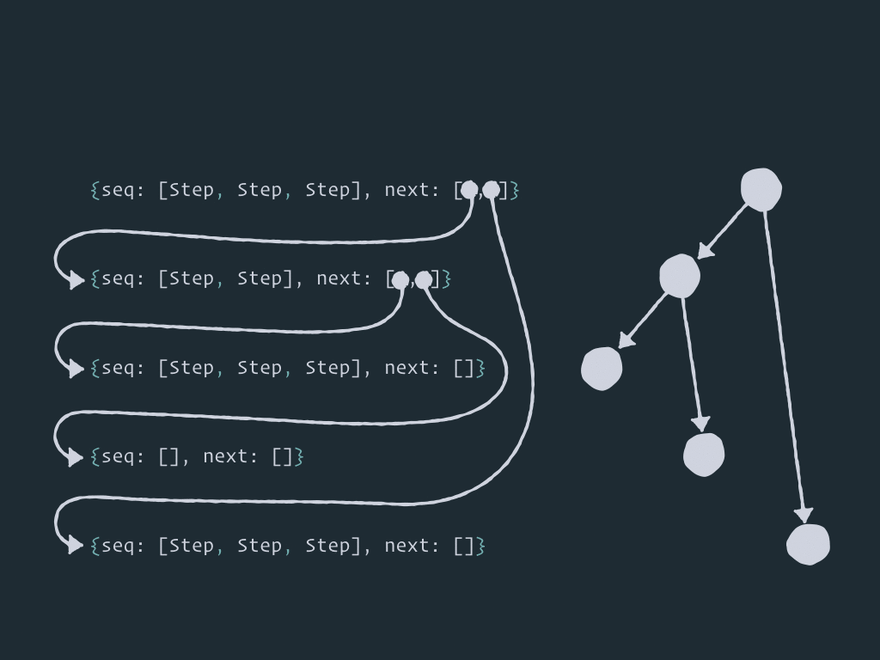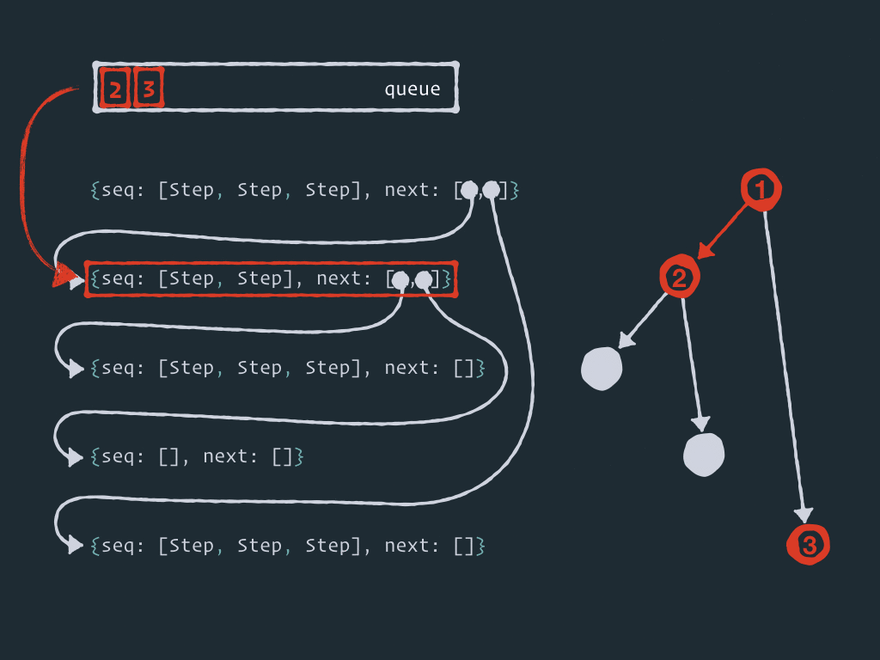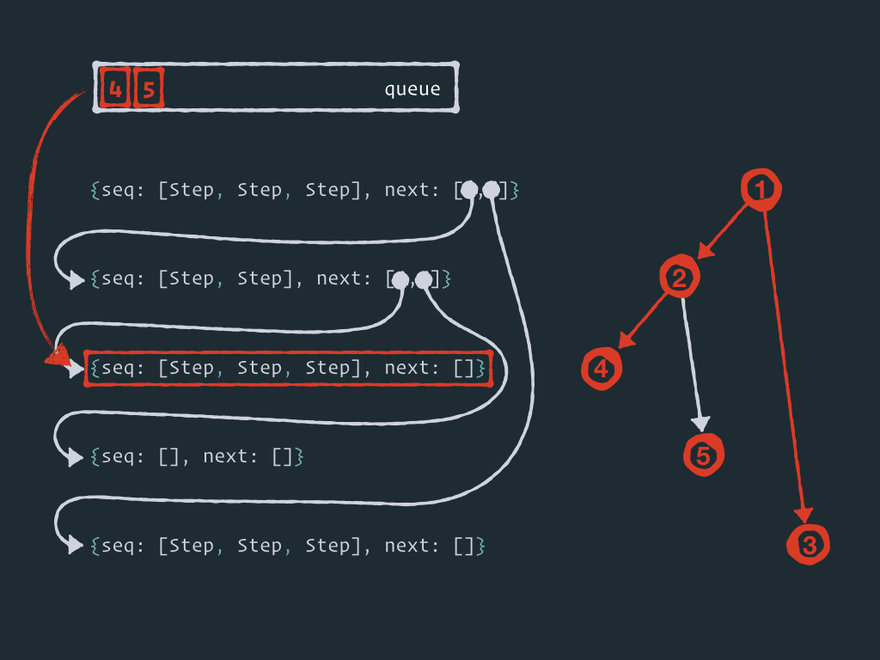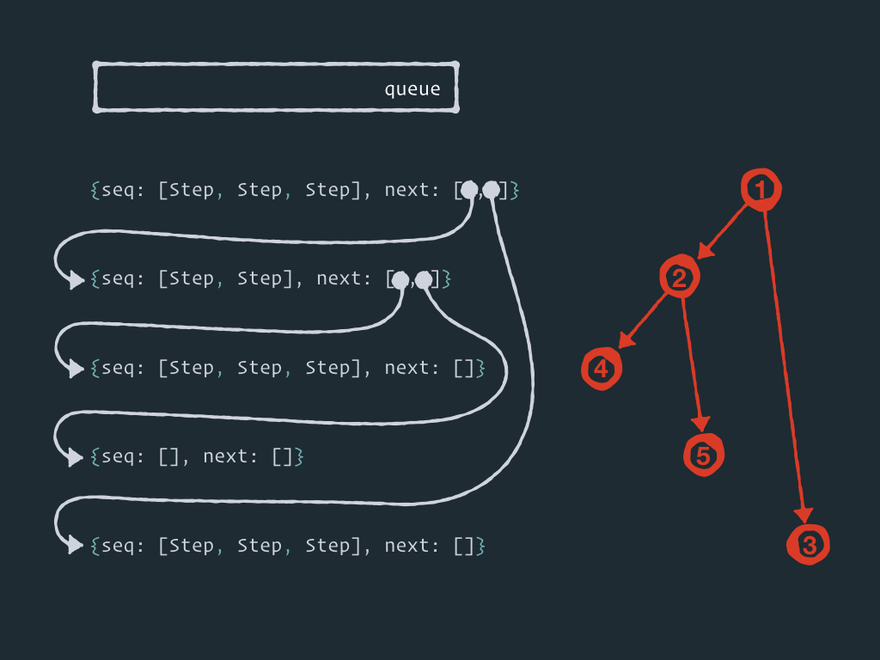
顺便说一下,这种图遍历算法被称为 广度优先搜索。Effector 使用了一种略加修改、带有优先级的广度优先搜索算法。我们稍后会看到。
让我们仔细看看这三点:
- 这是什么类型的数据以及它如何进入节点?
- 各种步骤及其区别
- 队列

那么,它是什么类型的 数据 以及它如何进入节点?
答案是事件!
当您调用一个事件(一个简单的函数)时,它所做的就是将有效负载发送到图表并启动一个计算周期。
当然,还有效果和商店。
调用 effect 的方式与调用 event(例如简单的函数)相同,从而将数据发送到图中。操作结束后,结果数据也会进入图中(进入 events/nodes .finally// .done).fail。
存储中有一个未公开的方法.setState(),该方法也会将有效负载传输到图。实际上,这与事件并没有太大区别。
但事件到底是什么?

事件是一个简单的函数,它接收有效载荷, launch并使用自身和接收到的数据调用函数。什么是 launch?launch 是效应器内核导出的唯一函数,也是 将数据放入计算图 并启动计算周期的唯一方法。
你可能会说:“这到底是怎么回事?我这里什么节点和图表都看不到!” 嗯,那是因为我还没展示主要内容:
场地.graphite:
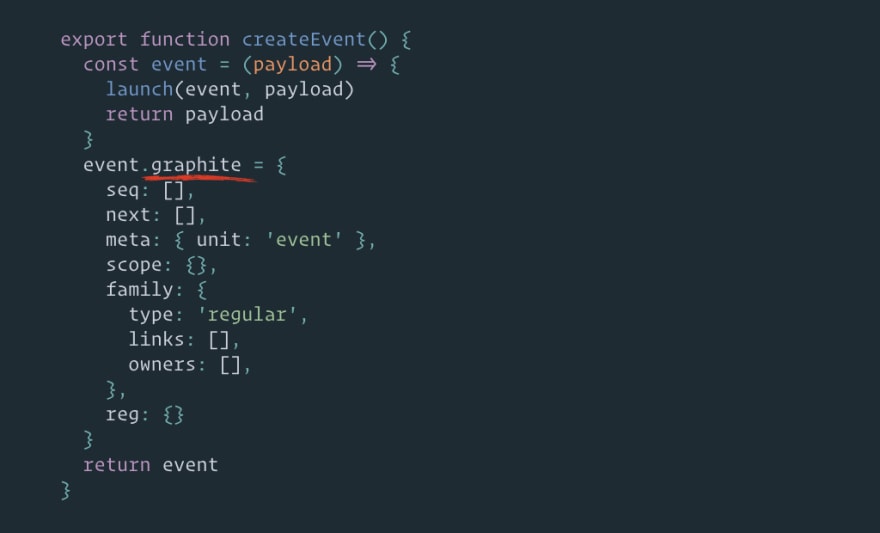
这就是我们的节点所在的地方。它是一个通信点,也是从事件函数到图的桥梁。
任何 Effector API 都可以与字段一起使用 .graphite (或者如果没有这样的字段,则 Effector API 认为它直接与节点一起使用)。
因此,事件是一个带有字段节点的函数 .graphite。存储是一个带有字段节点的对象 .graphite。效果也是一个带有字段节点的函数 .graphite (效果是一个包含其他节点的复杂实体,但主节点——连接函数和入口点的桥梁——位于 .graphite 字段中)。
有趣的是——Effector API 并不关心连接到节点的具体内容。它可以是一个函数,例如事件和效果;也可以是一个普通对象,例如存储;或者是一个 异步生成器,当其节点接收到给定值时,它会生成值。或者,这可以是原型链中的一个字段,这样类的所有实例都将连接到同一个图节点(不过,我不知道这有什么用处)。

步骤是什么以及它们有何不同?
步骤只是一个带有字段 的对象 .type。在 Effector 内核中,有一个 字段 switch (step.type),它根据步骤的类型决定执行什么操作。为了方便起见,Effector 包导出了该 step 对象以创建不同类型的步骤。
共有六种类型的步骤:

compute– 执行纯计算的步骤。它接受输入数据并返回新的转换后的数据。例如,中的 Reducer 函数store.on在此步骤中启动compute。中的 Map 函数store.map也在此步骤中运行。run– 与 相同compute,但旨在执行副作用。当内核遇到步骤 时run,节点的计算将被推迟(稍后我将展示)。因此,任何副作用都会 在任何纯计算之后执行 。例如,此步骤可用于watch节点(是的,该.watch方法会创建一个新节点)。filter– 停止计算的步骤。它接受输入数据并返回true或false值。如果false,则计算分支在此停止,即不会执行后续步骤,也不next会将字段中的节点添加到队列中。例如,此步骤用于.filter和.filterMap节点。barrier– 一个没有逻辑的步骤,但此步骤会推迟节点的执行,或者如果执行已被推迟,则取消节点。此步骤用于combine和sample。check– 包含两项检查的步骤:defined– 检查输入数据是否未定义changed– 检查输入数据是否与商店中保存的数据不同
mov– 几乎是内部逻辑的步骤。我不会在这里描述它,但长话短说,这一步将数据从/复制到存储和/或内部堆栈字段。我将它们称为 寄存器,就像 CPU 中的寄存器一样,例如 AX 或 BX。

现在,我们来看看队列。或者说是队列,因为效应器内核中有五个队列 :) 这与通常的广度优先搜索算法不同——在某些条件下,节点可以移动到不同的队列。

child– 来自字段的节点next被放置在此队列中。pure– 该launch函数将向该队列添加一个或多个节点。barrier和–放置sampler具有步骤的节点的两个队列 。barriereffectrun–放置具有步骤的节点的队列 。
队列具有不同的优先级。在计算周期的每次迭代中,内核都会根据优先级从队列中获取一个节点进行处理。因此,优先级最高的队列 child 首先被清空,优先级最低的队列 effect 最后被清空。因此,副作用总是在纯计算之后执行。
为什么我们需要不同的队列和优先级?让我们来看看一个常见的问题,叫做钻石依赖问题。

该问题的另一个名称是故障问题。
故障 ——是可观察 状态的暂时不一致。
本质上,问题在于当多个 store 以复杂的方式连接在一起时,一个 store 的一次更新可能会导致另一个 store 的多次更新。store 在视图中被频繁使用,而一个 store 的多次快速更新会导致视图无用的重新渲染,这看起来像是 故障,因此得名。
这里有一个简单的类比,与 Redux 世界类似:我们为什么需要使用 memoized selectors?因为如果我们不使用它们,任何 store 的更新都会导致所有组件的更新,即使它们的数据(store 的一部分)尚未更新。
另一个例子来自 Rx world:
--a------b------c------d--------e--------
--1-------------2---------------3--------
combineLatest
--a1-----b1-----(c1c2)-d2-------(e2e3)---
括号中的事件“同时发生”。实际上,它们发生的时间间隔略有不同,仅相隔几纳秒。这就是为什么人们认为它们是同时发生的。这些事件 (c1c2) 被称为 故障 ,有时被认为是问题,因为人们通常只期望它们 c2 会发生。
那么,Effector 是如何避免这个问题的呢?这也是存在屏障和不同优先级队列的原因之一。
以下是示例代码:
const setName = createEvent()
const fullName = createStore('')
.on(setName, (_, name) => name)
const firstName = fullName.map(
first => first.split(' ')[0] || ''
)
const lastName = fullName.map(
last => last.split(' ')[1] || ''
)
const reverseName = combine(
firstName,
lastName,
(first, last) => `${last} ${first}`
)
reverseName.watch(
name => console.log('reversed name:', name)
)
setName('Victor Didenko')
- 活动
setName接受全名 - 全名设置为存储
fullName - 两个派生的存储
firstName并lastName自动设置为名字和姓氏(map 函数用空格分隔全名) - 合并后的 store
reverseName依赖于 storesfirstName和lastName,并以相反的顺序连接它们的值

这里有一个问题:商店会 reverseName 更新一次(正确)还是两次(故障)?
如果你检查过 REPL,那么你已经知道正确答案了。存储只会更新一次。 但这是怎么发生的呢?
让我们 将这个逻辑关系图展开为效应器节点的结构图:
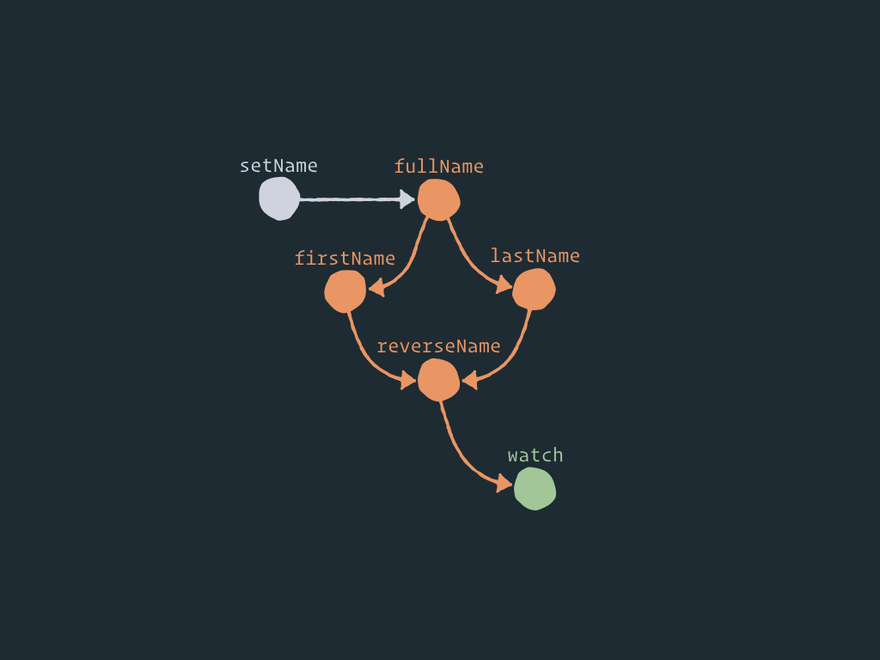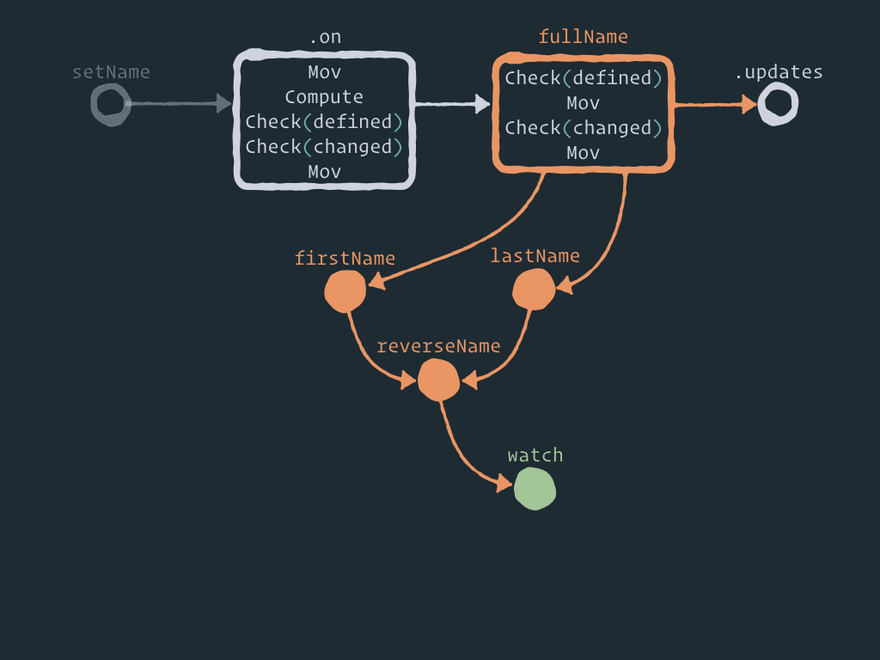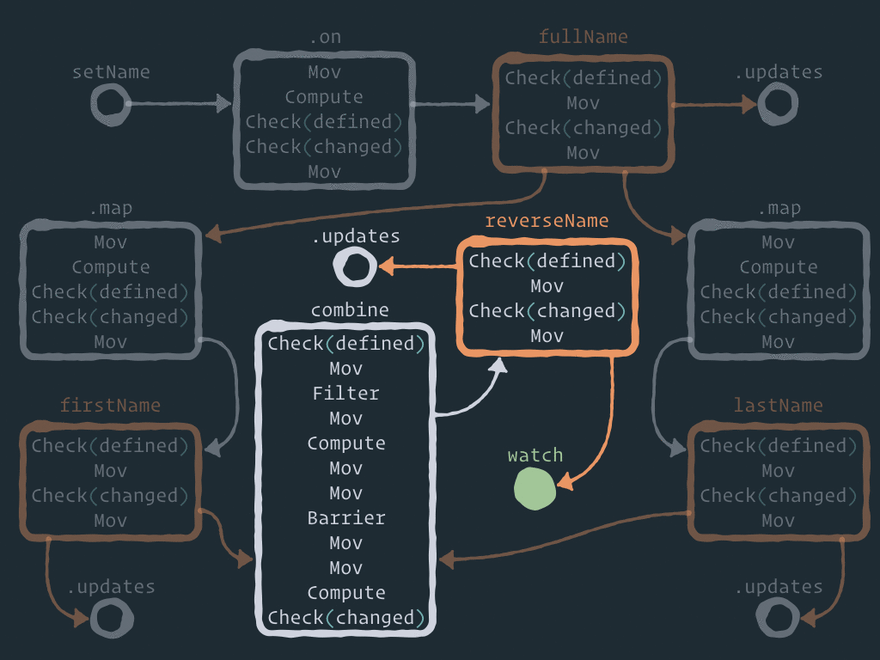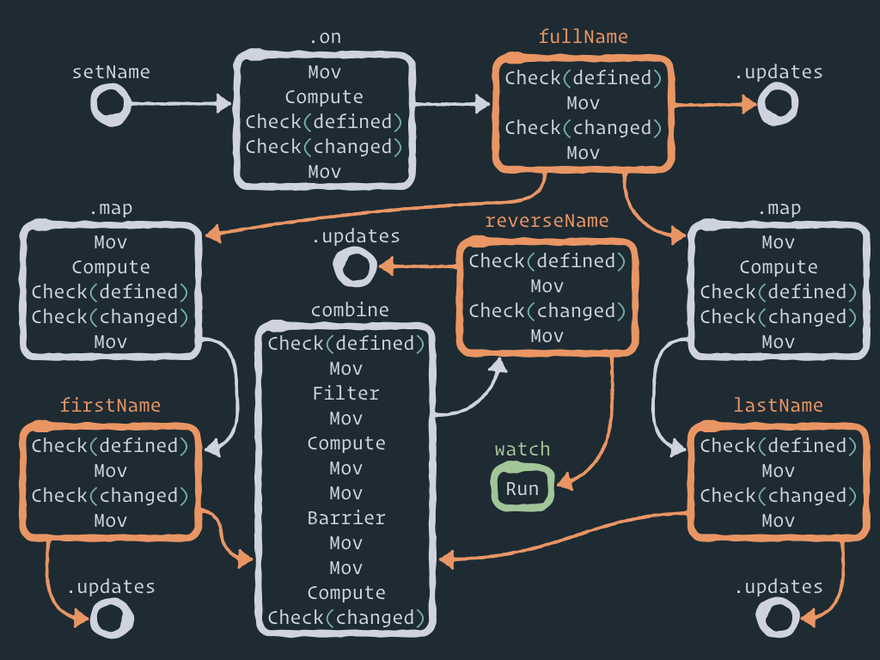
以下是效应器图的完整静态视图:
在这里,您可以看到一些辅助节点,例如 .on 事件和存储之间、 .map 存储和派生存储之间以及 combine 存储和组合存储之间的节点。在我看来,这就是 Effector 的魅力所在。您可以通过添加一个或多个具有一定逻辑的辅助节点来在实体/节点之间执行任何操作。例如, forward 只在两个节点之间添加一个节点。 .watch只添加一个新节点。 .on 在事件和存储之间添加一个辅助节点。如果您想执行操作 .off,只需移除这个中间节点即可! 是不是很有意思?
此计算图中的边仅由字段 中的链接绘制 next。我没有绘制所有权图,也没有绘制指向商店的链接图。
我不会解释该图中的每个步骤(此外,实现方式可以更改),但我希望您注意以下几点:
- 当您使用 API 时 – 第二步在
store.on(event, reduce)中间节点内执行 reduce 函数 。.oncompute - 当前存储值通过第一步复制到中间节点
mov。 - 中间节点
.map看起来与节点完全相同.on——换句话说,这实际上意味着派生存储 订阅了 父存储的更新。就像存储订阅事件一样。不过有一个区别——map 函数从父存储获取一个新值作为第一个参数,而 reduce 函数从事件获取一个新值作为第二个参数,并将当前存储的值作为第一个参数。 - 任何商店都以此
check.defined作为第一步,因此不可能undefined为商店设置价值。 - 每个存储中都有一个步骤
check.changed,因此如果存储值尚未被新数据改变,则图中的下一个节点将不会更新。
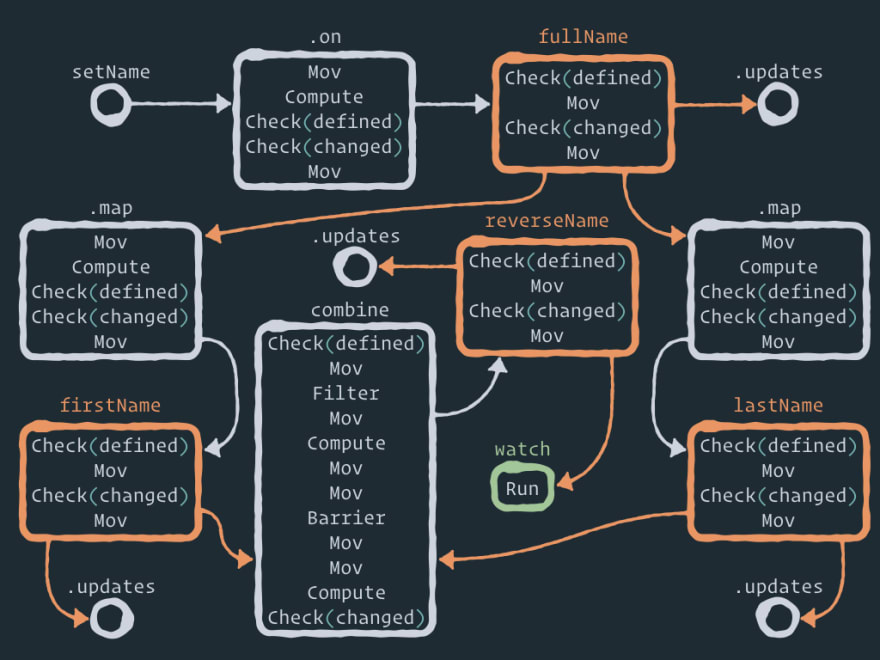
接下来,我想更详细地描述一下 barrier 节点中的 步骤combine 。以下是解决钻石问题的动画:

发生了什么事,一步一步来:
- 在某个时刻,我们在子队列中有两个节点——
firstName和lastName。 - 内核获取
firstName并执行节点步骤。然后,它将节点添加combine到child队列中。节点.updates也会被添加,但这是一个简单的过程,因此我在这里忽略它。 - 内核获取下一个节点
lastName并执行节点步骤。然后,它还将节点combine(同一个节点)添加到child队列中。因此,现在我们在队列中有两个指向同一个节点的链接。 - 内核获取节点
combine并执行节点步骤,直到满足步骤barrier。 - 当内核遇到 step 时
barrier,它会暂停节点执行,并将该节点放入barrier队列。内核还会保存屏障 ID 以及暂停执行的步骤索引。 - 然后内核 从队列
combine中获取node(同一个节点)child(因为队列child的优先级比barrier队列高),并执行node步骤,直到满足stepbarrier。 - 当内核遇到 step 时
barrier,它会暂停节点的执行,但现在它知道barrier队列中已经有一个具有相同屏障 ID 的推迟节点。因此,该barrier分支的执行不会再次将该节点放入队列,而是在此停止。 - 请注意,执行停止并不会丢弃所有计算结果。Node
combine会保存当前firstName值和lastName当前值。 - 现在
child队列是空的,所以内核combine从barrier队列中获取节点并从暂停的步骤继续执行。 - 因此,两个执行分支中只有一个会通过步骤
barrier。这就是钻石问题的解决方式。存储reverseName只会获得一次更新。 - 如果您有兴趣,组合函数会逐步执行
compute——barrier两个值都已存在。
在 Effector 电报聊天中,我看到了计算周期与闪电的完美对比:计算分支、发散、汇聚、切断等等,但所有这些都是单次放电的一部分。

回到最开始,为什么你需要了解效应器的内部结构?

如果你搜索 Effector 的文档,你会发现没有任何关于这些图表的提及(除了“现有技术”部分)。这是因为你无需了解其内部实现即可有效使用 Effector。抱歉,我重复了这些内容。你选择某个工具还是其他工具,应该取决于该工具旨在解决的任务,而不是工具的内部实现。顺便说一句, Effector 就像一个 Boss 一样,可以解决任何状态管理器问题 ;)
但是!总有但是 :)
了解引擎盖下发生了什么,你就能理清思绪,如果你像我一样脑子里有乱七八糟的东西。想象一下整个画面,解开谜题,然后用一堆散落的零件拼凑出那辆赛车。
顺便说一句,如果你对“图表”这个词有一些莫名的恐惧,我可以向你展示一个心理技巧:

您会看到“图形”这个词,听到“网络”这个词。
我是认真的,这是一样的。但从历史上看,“网络”这个术语在工程师中更广泛使用,而不是数学家。
这些知识还为您带来了好处:您可以用自己的逻辑创建自己的实体,并与本机效应器实体一起工作:)
我不会向你展示任何复杂的东西,只是一个简单的例子: node future (我也称之为“porter”)。它接受任何数据,如果数据不是 Promise,就将其进一步传递给图。但如果是 Promise,节点会保留它,直到 Promise 被解决。
function createFuture () {
const future = createEvent()
future.graphite.seq.push(
step.filter({
fn(payload) {
const isPromise = payload instanceof Promise
if (isPromise) {
payload
.then(result => launch(future, { result }))
.catch(error => launch(future, { error }))
}
return !isPromise
}
})
)
return future
}
const future = createFuture()
future.watch(_ => console.log('future:', _))
future(1)
future(new Promise(resolve => setTimeout(resolve, 100, 2)))
future(Promise.resolve(3))
future(Promise.reject(4))
future(5)
如您所见,我修改了一个普通事件的 seq 字段,即添加了一个步骤 filter。您可以从头创建一个包含节点的实体,但在这种情况下,您还应该考虑实现一些实用的方法,例如 .watch、 等等.map。 .prepend 事件默认提供了这些方法,不妨一用 :)
上述代码将打印以下内容:
future: 1
future: 5
future: {result: 3}
future: {error: 4}
future: {result: 2}
最后,我想在这里引用 Linus Torvalds 的一句话:
糟糕的程序员担心代码。优秀的程序员担心数据结构及其关系。
所以,想想你的工具,
关注数据结构。
谢谢。
文章来源:https://dev.to/effector/effector-we-need-to-go-deeper-4geg