关系数据库您需要了解的有关(关系)数据库的一切
什么是数据库?
什么是关系数据库?
设计数据库
SQL
操作数据库
数据库安全
灾难恢复
检查点
索引
存储程序
分布式数据库
实践
来源
如今,数据库几乎是所有软件的重要组成部分。在本文中,我将向您介绍使用数据库所需的一切知识。
什么是数据库?
如果您管理文件或文件夹中的信息,您迟早会发现:
- 您有多个包含相同信息的文件
- 您有多个关于同一主题的文件,但包含不同的信息,因此很难理解哪个文件包含正确/更新的信息。
- 每次您想要更改某些信息时,您都必须更新多个文件,这会花费大量时间,并且可能会导致导致前两个问题的错误。
这种处理信息的方法效率低下,数据库的出现就是为了解决这些问题。
数据库是一个允许所有人共享、管理和使用数据的系统。要使用数据库,您首先需要了解以下几点:
- 很多人都会使用它,所以你必须找到一种方法让他们轻松输入和提取数据。
- 数据库也存在用户窃取或覆盖重要信息的风险,因此在设计数据库时应考虑安全性和权限。
- 您还需要小心,不要丢失任何数据。系统可能会崩溃,或者硬盘可能会出现故障。数据库需要从这些故障中恢复的机制。
数据库类型
数据库有很多种,以下三种是数据库最常用的数据模型:
- 分层数据模型,其中数据之间存在树状关系。
- 网络数据模型,其中的数据彼此之间具有重叠关系。
- 关系数据模型,使用易于理解的表概念处理数据。
要使用分层数据模型和网络数据模型,您必须牢记物理位置和数据顺序来管理数据,因此执行灵活、高速的数据搜索很困难。
这就是我们使用关系数据模型的原因。
什么是关系数据库?
关系数据库是一种数据库类型。它使用一种结构,使我们能够识别和访问数据库中与另一部分数据相关的数据。关系数据库中的数据被组织成表。
表格、记录、字段、行和列
- 表是一组数据元素(值)。
- 文件中的一段数据称为一条记录。
- 记录中的每个项目称为一个字段。

- 一条数据或记录称为一行。
- 每个项目或字段称为一列。
主键、唯一键和空值

数据库中的字段通常扮演着重要的角色,我们称其为主键。在本例中,产品代码就是主键。下一节将详细介绍。
唯一值是不能重复的值(如产品名称,不应有两个同名的产品)。
Null表示没有值(如上文“备注”部分所示,其中存在空值)。某些字段可以为 null(取决于数据库)。
钥匙类型
- 键:数据库表中的一个或多个列,用于对表中的行进行排序和/或标识。例如,如果您按工资字段对人员进行排序,那么工资字段就是键。
- 主键:主键是表中用于唯一标识一行的一个或多个字段。主键不能为空(空白)。主键已建立索引(稍后将详细介绍索引)。
- 外键:外键是两个数据库表(其中一个有索引)中列之间的关系,旨在确保数据的一致性。
- 复合键:由一列或多列组成的主键。主键也可以由字段构成(但不太建议)。
- 自然键:由现实世界中已经存在的属性(字段)组成的复合主键(例如名字、姓氏、社会安全号码)。
- 代理键:内部生成的主键(通常是自动递增的整数值),在现实世界中不存在(例如,用于标识记录但没有其他作用的 ID)。
- 候选键:表中的一列或一组列,用于唯一标识任何数据库记录,而无需引用任何其他数据。每个表可能有一个或多个候选键,但其中一个候选键是唯一的(即主键)。
- 复合键:由两个或多个字段组成的组合键,用于唯一地描述表中的一行。复合键和候选键的区别在于,复合键中的所有字段都是外键;而候选键中的一个或多个字段可以是外键(但这不是强制性的)。
设计数据库
当您尝试自己创建数据库时,第一步是确定您要建模的数据的条件。
ER 模型
用于分析并绘制图表的模型。在此模型中,您可以使用实体和关系的概念来思考现实世界。
- E 指的是 Entity(实体)。现实世界中可识别的对象。例如,当将水果出口到其他国家时,水果和出口目的地可以被视为实体。用矩形表示。
- 每个实体都有属性,即描述该实体的特定属性(例如,水果中的产品名称)。用椭圆形表示。

- R 指的是关系。实体之间的关系。例如,水果和出口目的地是相互关联的,因为你把水果卖到出口目的地。用菱形表示。水果出口到许多出口目的地,而出口目的地也购买多种水果。我们称之为多对多关系。在 ER 模型中,实体之间的关联数量会被考虑,这被称为基数。

- 基数:实体之间的关联数。
- 一对一关系(1-1):我只向您出售水果,您也只从我这里购买水果。
- 一对多(或多对一)关系(n-1 或 1-n):我将水果卖给其他家庭,而那些家庭只从我这里购买水果。
- 多对多关系(nn):上面有一个例子。
正常化
将现实世界中的数据制成表格并存入关系数据库的过程,需要遵循一系列步骤。为了正确管理关系数据库,必须对数据进行规范化。规范化主要有两个目的:
- 消除冗余(无用)数据。
- 确保数据依赖关系合理,即数据以逻辑方式存储。
非规范化形式
第一范式就是从这张表创建的。所有你为给定实体识别出的属性可能都被分组在一个扁平结构中。这时,规范化过程就发挥作用了,用来组织这些属性。
第一范式
对于符合第一范式的表,它应该遵循以下 4 条规则:
- 它应该只具有单值(原子)属性/列:这意味着,例如,一种水果不应该在数据库中有两个名称。
- 存储在同一列中的值应该属于同一域:这更像是一个“常识性”规则。在每一列中,存储的值必须是相同的种类或类型。
- 表中的所有列都应具有唯一的名称:此规则要求表中的每一列都应具有唯一的名称。这是为了避免在检索数据或对存储的数据执行任何其他操作时出现混淆。
- 数据存储的顺序并不重要:该规则表明表中存储数据的顺序并不重要。
重要的
在继续之前你必须首先了解这一点:
- 主要属性:给定关系表的候选键的部分。
- 非主属性:不是候选键的一部分。
第二范式
- 它应该符合第一范式。
- 它不应该具有部分依赖关系。如果关系中的非主属性仅由复合候选键的一部分派生,则这种依赖关系被定义为部分依赖关系。
- 依赖性:当您必须使用主键才能获得特定值时(例如,通过您的姓名才能知道您的年龄)。
第三范式
- 它属于第二范式。
- 它不具有传递依赖性。如果关系中的非主属性由另一个非主属性或部分候选键与非主属性的组合派生,则此类依赖关系将被定义为传递依赖性。
设计数据库的步骤
现在您已经熟悉了基本术语和 ER 模型,可以开始设计数据库了。
- 确定数据库的用途。
- 确定所需的表格。
- 确定所需的字段。
- 识别专属字段。
- 确定表之间的关系。
- 定义约束以保持数据完整性(不要忘记规范化)。
SQL
使用数据库时,您必须使用 SQL(结构化查询语言)输入或检索数据。SQL 允许您与数据库进行通信。某些命令可能会根据您使用的数据库管理系统(例如 SQL Server)而有所不同。
它的命令可以分为三种不同类型:
-
数据定义语言(DDL):与数据结构相关。
- 创造
- 降低
- 改变
-
数据操作语言(DML):与存储的数据相关。
- 选择
- 插入
- 更新
- 删除
-
数据控制语言 (DCL):管理用户访问。
选择
最基本的 SQL 语句。
SELECT product_name /*The column you want to see...*/
FROM product; /*...from the table it belongs.*/
在哪里
用于指定您想要的信息。
此语句从产品表中检索单价大于或等于 200 的所有数据。
SELECT * /*This selects every column in the table.*/
FROM product
WHERE unit_price>=200; /*Very easy to understand right?*/
这个函数检索所有产品名称为“apple”的数据。
SELECT *
FROM product
WHERE product_name=’apple’;
比较运算符

逻辑运算符

其他
SELECT *
FROM product
WHERE unit_price
BETWEEN 150 AND 200; /*Between doesn’t need explanation I think.*/
SELECT *
FROM product
WHERE unit_price is NULL; /*This one neither.*/
喜欢
当您不知道具体要搜索什么时,您可以在条件中使用模式匹配,通过在 LIKE 语句中使用通配符。
例子:
SELECT *
FROM product
WHERE product_name LIKE "%n"; /*Will search for data ending with the letter ‘n’.*/
排序依据
根据某一列对数据进行排序。
SELECT *
FROM product
WHERE product_name LIKE "%n"
ORDER BY unit_price; /*Easy to understand, right*/
SQL 中的聚合函数
也称为集合函数。您可以使用它们来聚合信息,例如最大值或最小值。
例子:
SELECT MAX(unit_price) FROM product
通过分组聚合数据
如果对数据进行分组,可以轻松获得聚合值。要对数据进行分组,请将聚合函数与 GROUP BY 结合使用。
SELECT district, AVG(unit_price)
FROM product
GROUP BY district; /*Output: Average unit price per district*/
拥有
您不能将 WHERE 与聚合函数一起使用,而必须使用 HAVING。
SELECT district, AVG(unit_price)
FROM product
GROUP BY district;
HAVING AVG(unit_price)>=200; /*Filters result after being grouped.*/
搜索数据
SQL中还有更复杂的查询方法。
子查询和 IN
您可以将一个查询嵌入到另一个查询中(这称为子查询)。
SELECT *
FROM product
WHERE product_code
IN (
SELECT product_code
FROM sales_statement
WHERE quantity>=1000
);
首先执行括号中的查询。然后使用结果执行另一个 SELECT 语句。IN 运算符允许多个 WHERE 值(因此第一个 SELECT 语句与第二个 SELECT 语句协同工作)。
相关查询
子查询可能引用外部查询的数据,这称为相关查询。
SELECT *
FROM sales_statement U /*Alias? Maybe more on this later*/
WHERE quantity>
(
SELECT AVG(quantity)
FROM sales_statement
WHERE product_code=U.product_code
);
别名
SQL 别名用于为表或表中的列指定一个临时名称。通常用于缩短列名,以便于操作(尤其是在连接操作中)。别名仅在查询期间有效。
SELECT o.OrderID, o.OrderDate, c.CustomerName
FROM Customers AS c, Orders AS o
WHERE c.CustomerName="Around the Horn" AND c.CustomerID=o.CustomerID;
连接表
JOIN 用于根据两个或多个表之间的相关列来组合它们中的行。
不同类型的 SQL JOIN
以下是 SQL 中 JOIN 的不同类型:
- (内部)连接:返回两个表中具有匹配值的记录。
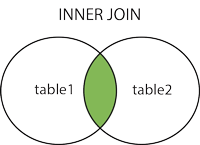
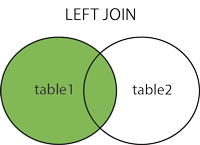
- LEFT (OUTER) JOIN:返回左表中的所有记录,以及右表中匹配的记录。
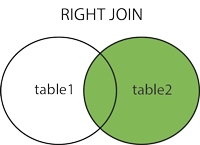
- 右(外)连接:返回右表中的所有记录,以及左表中匹配的记录。
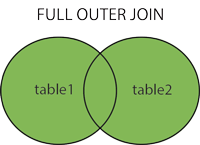
- FULL (OUTER) JOIN:当左表或右表有匹配时返回所有记录。
等值连接
根据关联表中相等或匹配的列值进行连接。等号 (=) 在 where 子句中用作比较运算符,表示相等。
SELECT *
FROM table1
JOIN table2
[ON (join_condition)]
/*You can also do it without JOIN*/
SELECT column_list
FROM table1, table2....
WHERE table1.column_name =
table2.column_name;
创建表
根据您使用的数据库类型,代码可能会有所不同。
CREATE TABLE product /*This line needs no explanation, right?*/
(
product_code INT NOT NULL,
product_name VARCHAR(255),
unit_price INT,
PRIMARY KEY(product_code)
);
- INT 表示整数。
- VARCHAR 表示数据库需要文本。255 表示不超过 255 个字符。
表上的约束
表的规范,以防止数据冲突。

将数据插入表中
INSERT INTO product (product_code, product_name, unit_price)
VALUES (101, "melon", 800);
INSERT INTO product VALUES (101, "melon", 800);
这两个语句的作用相同。你按照类型和定义的顺序插入数据。记住约束(例如主键)。
更新行
允许您修改表内的数据。
UPDATE product
SET product_name="cantaloupe" /*New value*/
WHERE product_name="melon"; /*Specific value to overwrite*/
删除行
从表中删除数据。
DELETE FROM product
WHERE product_name="apple"; /*Row to delete*/
创建视图
您可以创建一个虚拟表,该表仅在用户查看时存在。这就是视图。视图派生自的表称为基表。
CREATE VIEW expensive_product /*The view name is "expensive_product"*/
(product_code, product_name, unit_price)
AS SELECT *
FROM product
WHERE unit_price>=200;
要使用该视图:
SELECT *
FROM expensive_product
WHERE unit_price>=500;
当你想公开表中的部分数据时,创建视图会很方便。
降低
允许您删除:
/*A view:*/
DROP VIEW expensive_product;
/*A base table:*/
DROP TABLE product;
/*A database:*/
DROP DATABASE name;
操作数据库
交易
数据操作的单位称为事务。例如:读取数据、写入数据。事务总是以提交或回滚操作结束。
确保多个事务能够顺利处理且数据不冲突至关重要。此外,在事务处理过程中发生故障时,保护数据免受不一致的影响也至关重要。为此,下表列出了事务所需的属性,这些属性恰好就是 ACID。
交易所需的属性

犯罪
当每个事务都正确处理后,数据库中的操作就完成了。这种完成操作称为提交操作。
锁
为了控制多个用户的操作,避免他们并发访问数据库时出错,我们使用了一种名为Lock
的方法。 锁定数据可以防止其被错误处理。
如果我对数据库执行某些操作,数据将被锁定,直到我的操作完成,然后解锁以供另一个用户使用,数据再次被锁定,并在该用户完成时解锁。
虽然锁在数据库中有其自身的作用,但不应过度使用,因为它会妨碍其与多人共享数据的目的。因此,我们会根据具体情况使用不同类型的锁。
共享锁
例如,当只需要执行读操作时,可以对读操作使用共享锁。其他用户可以读取数据,但不能对其进行写操作。
独占锁
当执行写入操作时,用户会应用排他锁。应用该锁后,其他用户将无法读取或写入数据。
并发控制
当使用锁来控制两个或多个事务时,并发允许尽可能多的用户同时使用数据库,同时防止发生数据冲突。
双相锁定
为了确保调度可序列化,我们需要遵循设置和释放锁的特定规则。其中一条规则是两阶段锁定,每个事务应使用两个阶段:一个阶段用于设置锁,另一个阶段用于释放锁。
锁定粒度
可以锁定的资源有很多。资源锁定的程度称为粒度。粗粒度是指一次锁定大量资源,而细粒度是指一次锁定少量资源。粒度较粗(或较高)时,每个事务所需的锁数量会减少,从而减少所需的处理量。
其他并发控制
当事务数量较少或读取操作数量较多时,可以使用更简单的方法。
-
时间戳控制:事务期间访问的数据会被分配一个包含访问时间(时间戳)的标签。如果另一个时间戳更晚的事务已经更新了该数据,则该操作将不被允许。当读取或写入操作不被允许时,事务将被回滚。
-
乐观控制:此方法允许读取操作。当尝试写入操作时,将检查数据是否已发生其他事务。如果其他事务已更新数据,则回滚该事务。
隔离级别
您可以设置可并发处理的事务级别,这称为隔离级别。SET TRANSACTION 语句可用于指定以下事务的隔离级别:
- 未提交的阅读
- 已提交读取
- 可重复读取
- 可序列化
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
根据隔离级别设置,可能会发生以下任一操作:
- 脏读:当事务 2 读取事务 1 之前的一行时。
- 不可重复读:当一个事务两次读取相同的数据并得到不同的值时。
- 幻读:当一个事务搜索符合特定条件的行,但由于另一个事务的更改而找到错误的行。
僵局
两个用户在两个表上使用了排他锁。然后,他们都试图对另一个表应用相同的锁。由于他们都必须等待对方用户申请的锁被释放,因此双方都无法继续执行任何操作。这种情况称为死锁,除非其中一个锁被释放,否则无法解决。
回滚
发生死锁时,您可以查找已排队一定时间的事务并将其取消。取消事务(其中的每个操作)称为回滚。例如,如果您想对所有价格为 150 或以上的水果应用折扣,但其中一个操作失败,则您可以取消所有操作,数据库的行为就像未执行任何操作一样。
数据库安全
如果数据库安全不力,数据可能会在未经授权的情况下被删除或修改。一个好的解决方案可能是强制使用用户名和密码来限制用户,并将操作限制在特定用户范围内(例如,只有管理员才能删除表)。
授予
您可以使用 GRANT 授予用户访问权限。
GRANT SELECT, UPDATE ON product TO Overseas_business_department;
数据库权限

使用 WITH GRANT OPTION 授予权限使用户能够向其他用户授予权限。
GRANT SELECT, UPDATE ON product TO overseas_business_department WITH GRANT OPTION;
撤销
要剥夺用户的特权,请使用REVOKE。
REVOKE SELECT, UPDATE ON product FROM overseas_business_department;
某些数据库产品可以将多个权限分组,并一次性授予多个用户。分组使权限管理更加便捷。使用视图可以提高安全性,不仅允许特定用户访问视图,还能保护视图中选定的数据。
灾难恢复
数据库需要一种机制,能够在发生故障时保护系统中的数据。为了确保事务的持久性,必须确保任何故障都不会产生不正确或错误的数据。为了保护自身免受故障影响,数据库会执行各种操作,包括创建备份和事务日志。
每次执行数据操作时,都会保留名为日志的记录。当系统出现问题时,首先需要重新启动系统,然后利用日志恢复数据库。恢复方法取决于事务是否已提交。
故障类型
- 交易失败:由于交易本身的错误,导致交易无法完成。交易失败后,交易将被回滚。
- 系统故障:系统因电源故障或其他中断而宕机。如果问题发生在事务提交之后,您可以通过重新将操作应用于数据库来恢复数据。此方法称为前滚。如果事务尚未提交,则会发生回滚。系统会引用更新之前的值来取消事务。
- 介质故障:当包含数据库的硬盘损坏时。
检查点
为了提高数据库写入操作的效率,通常会使用缓冲区(用于临时保存数据的内存段)进行短期数据写入。缓冲区的内容与数据库同步,然后写入检查点。数据库写入检查点时,无需对检查点之前提交的事务执行任何故障恢复。检查点之前未提交的事务必须进行恢复。
索引
随着数据库规模不断扩大,越来越多的人开始使用它,一些问题可能会出现。数据量越大,搜索操作就越慢。
索引就像一本书一样。在书中盲目搜索信息会耗费时间,因此您可以查看索引来加快搜索速度。搜索某些数据时,浏览所有行非常耗时。如果您为产品代码创建索引,则可以立即了解指定产品的产品数据存储位置。它会告诉您产品数据存储在磁盘上的位置,从而减少磁盘访问次数,从而加快未来的搜索速度。
是否添加索引由数据库管理员决定。创建过多的索引可能会导致效率低下(想象一下,一本书中有大量索引,这不会有什么好处)。
存储程序
类型

数据库服务器内部的程序逻辑(基本上是服务器内部的查询)。它们有助于减轻网络负载,因为它消除了频繁传输 SQL 查询的需要。
分布式数据库
一种数据库,其中并非所有存储设备都连接到一个公共处理器,而是分布在多台计算机中,这些计算机位于同一物理位置或分散在互连计算机网络中。请记住,它可以作为单个数据库处理。
实践
- W3Schools 有很多基本的 SQL 练习,请练习它们。
- W3Resources 有各种各样的练习可以帮助您提高技能。
- 《数据库漫画指南》包含练习及其答案,不仅包括 SQL,还包括设计阶段的练习。
- 也可以尝试 Google 或 Youtube。
来源
- 封面图片:谷歌。
- 数据库漫画指南:强烈推荐!用一个简单的故事讲解了数据库的方方面面(本文大部分内容基于此)。书中包含更多技术信息和练习,非常实用。
- 我自己高中时的笔记。
- https://www.codecademy.com/articles/what-is-rdbms-sql
- https://basededatosaplicado.blogspot.com/2011/10/v-behaviorurldefaultvmlo.html
- https://wofford-ecs.org/DataAndVisualization/ermodel/material.htm
- https://www.studytonight.com/dbms/database-normalization.php
- https://www.w3schools.com/sql/sql_like.asp
- https://www.w3schools.com/sql/sql_having.asp
- https://www.w3schools.com/sql/sql_join.asp
- https://www.w3schools.com/sql/sql_alias.asp
- https://www.w3resource.com/sql/joins/perform-an-equi-join.php
- https://en.wikipedia.org/wiki/Distributed_database
- http://www.informit.com/articles/article.aspx?p=27785&seqNum=3
- https://germoroney.wordpress.com/2012/11/26/different-types-of-database-keys/
- https://www.quora.com/数据库管理中部分和传递性依赖关系之间有何区别?
- https://medium.com/@jimmyfarillo/the-basics-of-database-indexes-for-relational-databases-bfc634d6bb37
感谢您的阅读。别忘了在 dev.to 和 Twitter 上关注我!
文章来源:https://dev.to/lmolivera/everything-you-need-to-know-about-relational-databases-3ejl