抓取一切!用 Python 和 Go 构建 Web 爬虫
目录
介绍
我们熟知并喜爱的网络是一个庞大的非结构化数据池,通常以网页的形式呈现,可以通过网络浏览器访问。网络爬虫旨在利用这些数据的力量,通过使用精心挑选的工具自动提取数据,从而节省我们的时间和精力。在本文中,我将指导您完成编写网络爬虫来驯服这头“野兽”所需的一些步骤。所解释的概念与语言无关,但由于我正在从动态类型的 Python 语法过渡到严格的静态 Go 语法,因此本文将结合两种语言的示例进行讲解。最后,本文将简要介绍分别用Python和Go编写的两个项目。这两个项目实现了截然不同的目标,但都建立在“网络爬虫”这一令人赞叹的概念之上。
您将学习以下内容:
- 识别网络抓取机会
- 抓取项目的关键组成部分
- 打包并部署爬虫
🚩本文中展示的许多代码片段无法自行编译,因为大多数时候我会引用前一个代码片段中声明的变量或使用示例 URL 等
识别网络抓取机会
网上有大量以网页形式存在的数据。这些数据可以从非结构化数据转换为结构化数据,以存储在数据库中,用于支持仪表板等。
识别网页抓取机会的技巧很简单,只要有一个项目需要网页上可用的数据,但这些数据无法通过标准化库或Web API轻松访问。
另一个指标是数据的波动性,即要抓取的数据在网站上更新或更改的频率。
一个强大的网页抓取机会通常是整合。 整合是指两个或多个实体的组合。在我们的案例中,整合是指将从不同来源获得的数据合并到一个端点。例如,一个项目旨在构建一个用于显示西非主要疾病统计数据的仪表板。这个项目是一项重大任务,通常涉及多个流程,包括但不限于手动数据收集。然而,让我们假设我们可以访问多个网站,每个网站都包含我们需要的一小部分数据。我们可以抓取所有相关网站并将数据整合到一个仪表板中,同时节省时间和精力。 然而,也存在一些需要注意的地方,例如,有些网站设有禁止抓取数据的条款和条件,尤其禁止用于商业用途的数据抓取。有些网站会将发送过多、过快请求的可疑 IP 地址列入黑名单,因为这可能会破坏其服务器。
抓取项目的关键组成部分
每个网络抓取项目中都有一些持久组件:
- 人工检查
- Web 请求
- 响应解析
- 数据清理和转换
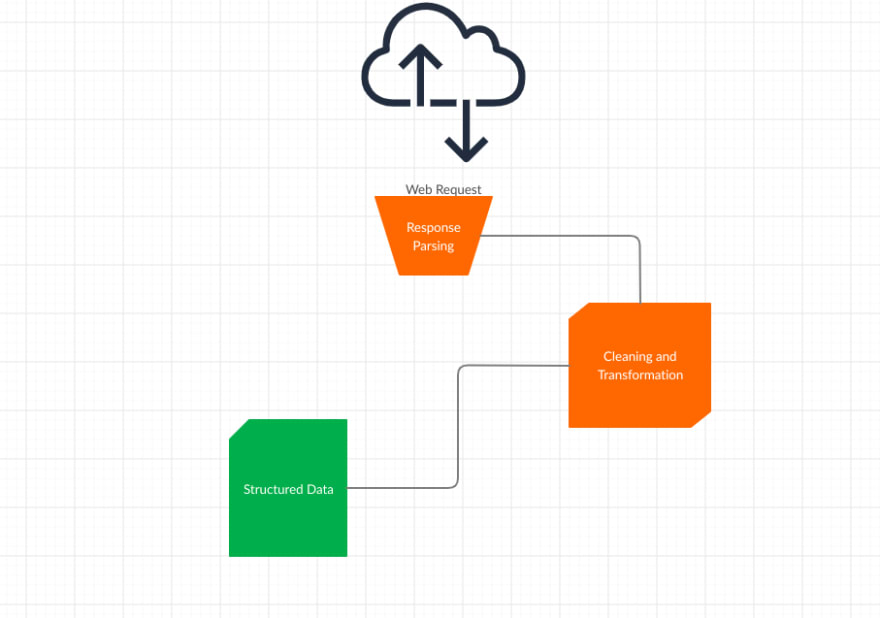
人工检查
要成功创建网页抓取工具,理解HTML页面的概念至关重要。网站就像一个由多个动态代码组成的“汤”。为了提取相关信息,我们必须检查网页中是否存在相关内容。手动检查通常用于大致了解页面信息。
要手动检查页面,请右键单击网页,然后选择“检查”。这样您就可以窥探网站的灵魂或源代码。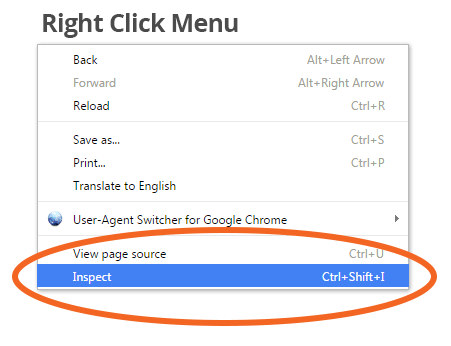
点击“检查”后,会弹出一个控制台。该控制台可让您导航并查看页面上显示的每条信息对应的 HTML 标签。

Web 请求
这涉及向网站发送请求并接收响应。请求可以配置为接收 HTML 页面、获取文件、设置重试策略等。收到的相应响应包含许多我们可能需要的信息,例如状态码、内容长度、内容类型和响应正文。这些都是我们在响应解析阶段需要解析的重要信息。Python(例如,requests)和 Go(例如,http)中有一些库可以实现此过程。
这是 Python 中的实现
"""
Web Requests using Python Requests
"""
import requests
from requests.adapters import HTTPAdapter
# simple get request
resp = requests.get("http://example.com/")
# posting form data
payload = {'username':'niceusername','password':'123456'}
session = requests.Session()
resp = session.post("http://example.com/form",data=payload)
# setting retry policy to 5 max retries
session.mount("http://stackoverflow.com", HTTPAdapter(max_retries=5))
这是 Go 中的相应实现
/**
Web Requests using Go net/http
**/
package main
import "net/http"
func main(){
// simple get request
resp, err := http.Get("http://example.com/")
// posting form data
resp, err := http.PostForm("http://example.com/form",
url.Values{"key": {"Value"}, "id": {"123"}})
}
不幸的是,net/http 不提供重试,但我们可以使用第三方库,例如pester
/** Retry Policy with pester **/
package main
import "github.com/BoseCorp/pester"
func main() {
client := pester.New()
// set retry policy to 5 max retries
client.MaxRetries = 5
resp, _ := client.Get("http://stackoverflow.com")
}
响应解析
这涉及从网页中提取信息,并且仍然与前面提到的手动检查密切相关。顾名思义,我们利用响应提供的属性(例如响应主体、状态码、内容长度等)来解析响应。其中,响应主体中包含的 HTML 通常是最难解析的(假设我们自己解析)。值得庆幸的是,有一些结构化且稳定的库可以帮助我们轻松地解析 HTML。
<!--- Assume this is our html -->
<html>
<body>
<p>
This is some
<b>
regular
<i>HTML</i>
</b>
</p>
<table id="important-data">
<tr>
<th>Name</th>
<th>Country</th>
<th>Weight(kg)</th>
<th>Height(cm)</th>
</tr>
<tr>
<td>Smith</td>
<td>Nigeria</td>
<td>42</td>
<td>160</td>
</tr>
<tr>
<td>Eve</td>
<td>Nigeria</td>
<td>49</td>
<td>180</td>
</tr>
<tr>
<td>Tunde</td>
<td>Nigeria</td>
<td>65</td>
<td>175</td>
</tr>
<tr>
<td>Koffi</td>
<td>Ghana</td>
<td>79</td>
<td>154</td>
</tr>
</table>
</body>
</html>
对于 Python 来说, BeautifulSoup4无疑是解析器之王
import requests
from collections import namedtuple
from bs4 import BeautifulSoup
TableElement = namedtuple('TableElement', 'Name Country Weight Height')
request_body = requests.get('http://www.example.com').text
# using beautiful soup with the 'lxml' parser
soup = BeautifulSoup(request_body, "lxml")
# extract the table
tb = soup.find("table", {"id": "important-data"})
# find each row
rows = tb.find_all("tr")
table = []
for i in rows:
tds = i.find_all("td")
# tds would be empty for the row with only table heads (tr)
if tds:
tds = [i.text for i in tds]
table_element = TableElement(*tds)
table.append(table_element)
# print first person name
print(table[0].Name)
在我看来,Go 语言没有绝对的解析之王,但我最喜欢的是Colly。Colly将 net/http 的功能整合到其库中,因此它既可以执行 Web 请求,也可以进行解析。
package main
import (
"strconv"
"fmt"
"github.com/gocolly/colly"
)
type TableElement struct {
Name string
Country string
Weight float64
Height float64
}
func main() {
// table array to hold data
table := []TableElement{}
// instantiate collector
c := colly.NewCollector()
// set up rule for table with important-data id
c.OnHTML("table[id=important-data]", func(tab *colly.HTMLElement) {
tab.ForEach("tr", func(_ int, tr *colly.HTMLElement) {
tds := tr.ChildTexts("td")
new_row := TableElement{
Name: tds[0],
Country: tds[1],
Weight: strconv.ParseFloat(tds[2], 64),
Height: strconv.ParseFloat(tds[3], 64),
}
// append every row to table
table = append(table, new_row)
})
})
// assuming the same html as above
c.Visit("http://example.com")
// print first individual name
fmt.Println(table[0].Name)
}
数据清理和转换
如果抓取 HTML 标签后,你最终能得到想要的数据,那么🎉,你的工作就基本完成了。如果没有,那么接下来的部分通常非常重要,需要你撸起袖子,做一些清理和转换工作。标签内的文本通常比较杂乱,空格不必要,可能需要一些正则表达式技巧才能进一步提取合理的数据。
"""
Extracting Content Filename from Content-Disposition using Python regex
"""
import re
# assume we have a response already
content_disp = response["Header"]["Content-Disposition"][0]
filename_re = re.compile('filename="(.*)"')
filename = re.match(filename_re, content_disp)[0]
print(filename)
# Avengers (2019).mp4
/**
Extracting Content Filename from Content-Disposition using Go regex
**/
package main
import (
"regexp"
"fmt"
)
func main() {
re := regexp.MustCompile(`filename="(.*)"`)
content := response.Header["Content-Disposition"][0]
filename := re.FindStringSubmatch(content)[1]
fmt.Println(filename)
// Avengers (2019).mp4
}
此外,为了清理数据,同时轻松地融化、旋转和操作其行和列,可以使用Python 中的Pandas及其 Go 等效的Gota
import pandas as pd
# using the previous tables variable which is a list of TableElement namedtuples
df = pd.DataFrame(data=tables)
print(df.head())
""" Console output
Name Country Weight Height
0 Smith Nigeria 42 160
1 Eve Nigeria 49 180
2 Tunde Nigeria 65 175
3 Koffi Ghana 79 154
"""
package main
import (
"github.com/go-gota/gota"
"fmt"
)
func main(){
// using the previous tables variable which is a slice of TableElement structs
df := dataframe.LoadStructs(tables)
fmt.Println(df.head())
}
/** Console output
Name Country Weight Height
0 Smith Nigeria 42 160
1 Eve Nigeria 49 180
2 Tunde Nigeria 65 175
3 Koffi Ghana 79 154
**/
请参阅这篇关于使用 Pandas 进行数据清理的精彩文章。
打包并部署爬虫
包装
这完全取决于你的爬虫的用例。你可以通过以下问题来确定你的用例:
- 抓取工具是否应将数据传输到另一个端点,还是应保持休眠状态直到轮询?
- 您是否存储数据以供以后使用?
他们会指导你为你的爬虫选择合适的打包方式。
第一个问题可以帮助你将爬虫视为 Web 服务还是实用程序。如果它不是流式爬虫,你应该考虑将其用作库或命令行界面 (CLI)。如果你喜欢图形用户界面 (GUI),也可以选择构建图形用户界面 (GUI)。对于 CLI,我建议使用 Python 的argparse和Golang 的ishell。对于创建跨平台桌面 GUI,Python 的PyQt5和 Golang 的Fyne应该足够了。
注意📝:如果您要特别设置流式抓取工具,则可能需要应用一些技巧,例如速率限制、IP 和标头旋转等,以免抓取工具被列入黑名单。
第二个问题有助于决定是否添加数据库。查看 Python psycopg和 Go pq以连接到PostgresQL数据库
我已经能够依靠Flask来生成简单的 Python 服务器,并且使用它们来部署抓取工具也不是很麻烦。
from flask import Flask
from flask import request, jsonify
app = Flask(__name__)
def scraping_function(resp):
""" scraping function to extract data """
...
data = {"Name": "", "Description":""}
return jsonify(data)
@app.route('/')
def home():
username = request.args.get('category')
# dynamically set the url to be scraped based on the category received
url = f"https://example.com/?category={category}"
resp = request.Get(url)
json_response = scraping_function(resp)
return json_response
if __name__=='__main__':
app.run(port=9000)
对于 Golang 来说,net/http 仍然是生成小型服务器来与逻辑交互的最佳方式。
package main
import(
"net/http"
"encoding/json"
"os"
)
type Example struct {
Name string
Description string
}
func scraping_function(r http.Response) Example {
// scraping function to extract data
data := Example{}
return data
}
func handler(w http.ResponseWriter, r *http.Request) {
category := r.URL.Query().Get("category")
if category == "" {
http.Error(w, "category argument is missing in url", http.StatusForbidden)
return
} else {
url := "https://example.com/?category=" + category
resp, _ := http.Get(url)
scraping_result = scraping_function(resp)
// dump results
json_output, err := json.Marshal(scraping result)
if err != nil {
log.Println("failed to serialize response:", err)
return
}
w.Header().Add("Content-Type", "application/json")
w.Write(json_output)
}
func main(){
http.HandleFunc("/", handler)
// check if port variable has been set
if os.Getenv("PORT") == "" {
http.ListenAndServe(":9000", nil)
} else { http.ListenAndServe(":"+os.Getenv("PORT")) }
}
要与服务器交互,只需使用curl。如果它在端口 9000 上运行,则测试两个服务器的命令显示为
curl -s 'http://127.0.0.1:9000/?category=cats'
{
"Name": "",
"Description": "",
}
部署
你的爬虫 Web 应用从来就不是在你的系统上运行的。它是为了胜利、征服、繁荣、飞翔而生的(好吧,别再说那句令人尴尬的 Fly 了——Nicki Minaj 的励志绕道)。像Heroku这样的PaaS 平台,只需编写一个简单的 Procfile 即可轻松部署 Python 和 Golang Web 应用。对于 Flask 应用,最好使用像Gunicorn这样的生产就绪服务器。只需将其添加到应用程序根目录的文件中即可。requirements.txt
# Flask Procfile
web: gunicorn scraper:app
烧瓶刮刀的文件布局
|-scraper.py
|
|-requirements.txt
|
|-Procfile
阅读将 Flask 应用程序部署到 Heroku以深入了解部署过程。
对于 Golang 应用程序,请确保在项目根目录下有一个go.modgo.mod文件和一个 Procfile。使用你的,Heroku 会生成一个bin/以你的主包脚本命名的二进制文件。
# Go Procfile
web: ./bin/scraper
net/http 抓取工具的文件布局
|-scraper.go
|
|-go.mod
|
|-Procfile
请参阅Heroku 使用 Go 入门指南,了解更多信息
使用 Python 的示例抓取项目
我当时正在尝试使用Keras 的 ResNet50 和 Imagenet 权重创建一个反向图像搜索引擎,并为其制作了一个小型搜索页面。然而,问题在于,每当我找到所需的图像类别时,都必须重定向到 Google。我当时就想在自己的 Web 应用程序上显示搜索结果,真是太难了。我尝试使用 Google 的 API,但同时又想切换搜索引擎,比如 Bing。相应的脚本发展成为一个独立的开源项目,最终吸引了众多贡献者和众多抓取引擎的关注。它以 Python 库的形式提供,已被超过 600 个其他 GitHub 代码库使用,其中大多数是需要在代码中实现搜索引擎功能的机器人。

在Github上查看搜索引擎解析器
使用 Go 进行爬取的示例项目
我当时正在访问我最喜欢的低流量电影下载网站netnaija,但那天特别烦人。我点击了一下,结果被重定向到一堆色情图片。“我只想要免费电影!”我哭了。于是
我创建了Gophie。这是一个命令行工具,让我可以随心所欲地省钱,而不会感到内疚。我可以在终端上舒适地搜索和下载 netnaija 的电影。抓取 1,Netnaija 0。

在Github上查看 Gophie
结论
在本文中,您了解了一些创建用于数据检索的 Web 爬虫的思路。其中一些信息,如果您再进行一些研究,就能用来创建行业标准的爬虫。我尽量让文章尽可能完整,但这是我第一次尝试撰写技术文章,所以如果您觉得我遗漏了任何关键信息,或者在下方评论区提出问题,欢迎随时提出。现在就去爬取所有内容吧!
附言✏️:我不确定抓取谷歌数据是否合法,但谷歌抓取的是所有人的数据。谢谢
文章来源:https://dev.to/deven96/scrape-everything-building-web-scrapers-with-python-and-go-34i7