REST API 指南
总结
本指南旨在帮助您了解构建 REST API 所需的基础知识。涵盖以下主题:
- REST 约束
- 理查森成熟度模型
- REST 实践(一些实用指南)
- 示例项目(使用 .Net Core 3.1 以 C# 编写)名为Ranker
关于 REST,我想总结以下要点:
- REST是一种用于描述 Web 架构的架构风格
- REST与协议无关
- REST是关于 Web 架构的(REST != API)
- REST不是一种设计模式
- REST并非一个标准。然而,标准可以用来实现 REST。
1. REST基础知识
本节涵盖 REST 的基本知识。本部分旨在帮助读者轻松理解 REST 的概念,并提供开始讨论 REST 以及构建采用 REST 架构风格的 HTTP 服务所需的最基本理论知识。
介绍
REST(表述性状态转移)是一种架构风格,由Roy Thomas Fielding在其博士论文“架构风格和基于网络的软件架构的设计”中定义。
据菲尔丁说,
“表述性状态转移”这个名称旨在唤起人们对精心设计的 Web 应用程序行为的想象:一个网页网络(虚拟状态机),用户通过选择链接(状态转换)来浏览应用程序,从而将下一页(代表应用程序的下一个状态)传输给用户并呈现给他们使用。
(Fielding,2000)第 109 页
为什么要 REST?
如果您是为分布式系统构建 HTTP 服务的人,那么理解和应用 REST 原则将帮助您构建更具以下特点的服务:
- 可扩展
- 可靠的
- 灵活的
- 便携的
通过基于 REST 原则构建服务,可以有效地构建更加 Web 友好的服务。这是因为 REST 是一种描述 Web 架构的架构风格。
REST 架构约束
Fielding将 REST 描述为一种混合风格,它源自几种基于网络的架构风格(第三章),并结合了一些额外的约束。本节将讨论 REST 的六种架构约束。关键在于,这些约束鼓励我们进行设计,从而打造出易于扩展、速度更快、更可靠的应用程序。
6 个架构 REST 约束如下:
1. 客户端-服务器
客户端-服务器架构的指导原则之一是关注点分离。其核心在于实现高内聚和松耦合,以提高可移植性和灵活性。此外,它还允许系统彼此独立地发展。如下图所示,客户端发送请求,服务器接收请求。

2. 无国籍
服务器在通信期间不得存储任何状态。理解请求所需的所有信息都必须包含在请求中。因此,每个请求都应该能够独立执行并且自成一体。此外,客户端也必须维护自己的状态。这种方法的好处如下:
- 可见性 - 理解请求所需的一切都在请求内部。这使得监控请求更加容易。
- 可靠性 - 故障恢复更容易,因为服务器无需跟踪/回滚/提交状态,所有状态基本上都包含在消息中。如果请求失败,只需重新发送该请求即可。
- 可扩展性——由于不需要管理请求之间的状态和资源,并且所有请求都是隔离的,因此可扩展性得到了提高和简化。
- 与网络架构保持一致(互联网就是这样设计的)

这种方法的缺点是它会降低网络效率,因为请求需要包含该交互所需的所有信息。信息越多,请求大小就越大,因此占用的带宽也就越多。这也会对延迟产生负面影响。
3.缓存
缓存约束的主要原因是为了提高网络效率。如上文无状态约束中所述,由于需要更多带宽,请求的大小可能会降低网络效率。通过缓存,可以减少甚至消除客户端与服务器交互的需要。换句话说,可以减少和/或消除对请求的需求。因此,缓存约束规定服务器必须在响应中包含其他数据,以指示客户端该请求是否可缓存以及可缓存多长时间。然后,网络客户端可以根据响应中提供的缓存信息来决定适当的操作。
缓存可以提高性能。然而,它也存在一些影响系统可靠性的缺点。例如:
- 数据完整性——由于数据陈旧或过期,响应数据可能不准确
- 复杂性——缓存机制的实现和使用在计算机科学领域以其复杂性而闻名
4.统一接口
这一约束的核心是通用性原则,它与预期原则密切相关。它源于这样一个事实:我们不可能为服务器服务的所有网络客户端构建完全相同的所需接口。因此,通过提供通用接口,我们可以提供更简化、更易于理解的接口,从而满足更多客户端的需求。这种方法的缺点是,由于接口过于通用,我们无法满足特定客户端的需求。换句话说,提供通用接口可能会导致许多客户端无法获得最佳的接口。
统一接口有四个附加约束,具体如下:
-
资源识别
REST 的一个关键抽象是资源。根据Fielding(《资源和资源标识符》)的说法,资源是任何可以命名的信息。此外,我个人更喜欢将资源视为“名词”。
名词——用于识别一类人、地点或事物(普通名词)或用于命名其中特定的一个(专有名词)的词(代词除外)。
最好将单个资源视为资源的集合。例如,如果我们提供一个 API 允许客户端提交或检索“评分”,则通常会按以下方式标识该资源:
GET /ratings一般来说,访问资源应该只有一种方式。但这更像是一种指导原则,而非规则。
-
通过表述来操纵资源
此约束规定客户端应持有包含足够信息以创建、修改或删除资源的资源表示形式。重要的是,资源表示形式应与资源的标识方式分离。资源可以采用多种格式或表示形式,例如 JSON、XML、HTML、PNG 等。客户端应该能够为与服务器的任何交互指定所需的资源表示形式。因此,客户端可以指定以JSON格式接收资源,但以XML格式发送资源作为输入。
例如:
为了检索员工资源,我们
通过指定“Accept: application/xml”标头使用 XML 格式。GET /ratings Accept: application/xml <ratings> <rating> <id>7337</id> <userId>98765</userId> <movieId>12345</movieId> <score>6</score> </rating> </ratings>为了创建员工资源,我们
通过指定“Content-Type: application/json”标头来使用 JSON 格式POST /ratings Content-Type: application/json { "userId": 98765, "movieId": 12345, "score": 6 }如果某种格式不受支持,服务器必须提供适当的响应来表明该格式不受支持。例如:
- 返回406 Not Acceptable状态码,表示客户端指定的请求带有服务器无法满足的Accept标头格式。[更多信息请参见此处]
- 如果响应中指定了不受支持的内容类型,则返回415 不支持的媒体类型。[更多信息请参见此处]
-
自我描述信息
自描述消息允许中间组件转换消息内容,从而实现中间通信。换句话说,消息的语义暴露给中间组件。这种约束的含义是:交互是无状态的,使用标准方法和媒体类型来暴露消息的语义,并且响应指示可缓存性。
-
超媒体作为应用程序状态的引擎(HATEOAS)
关于 HATEOAS 的一个关键概念是,它意味着从服务器发送的响应应该包含告知客户端如何与服务器交互的信息。
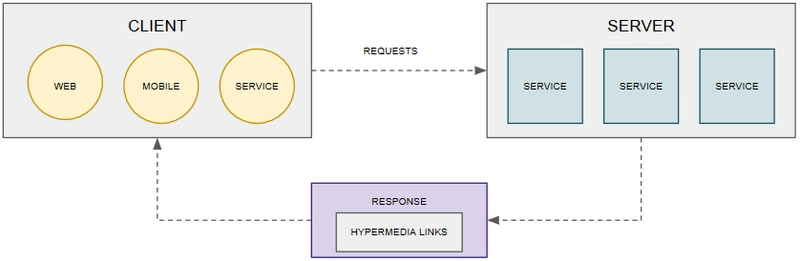
HATEOAS的优势如下:
- 通过发布的链接集(提供响应)提高资源的可发现性
- 指示客户端下一步可以采取哪些操作。换句话说,如果没有HATEOAS,客户端只能访问数据,但不知道可以对这些数据采取哪些操作。

5.分层系统
此约束的关键原则是,客户端不能假设它正在与服务器直接通信。此约束与客户端-服务器约束(如上所述)相关,其原理是客户端和服务器解耦。因此,客户端不会假设任何隐藏的依赖关系,这使我们能够在客户端和服务器之间插入组件和整个子系统。这使我们能够在客户端和服务器之间添加负载均衡器、DNS、缓存服务器和安全机制(身份验证和授权),而不会中断交互。
分层允许人们发展和改进架构,以提高系统的可扩展性和可靠性。
6.按需编码
这是一个可选约束。此约束的关键概念是,当客户端向服务器上的资源发出请求时,它将接收该资源以及针对该资源执行的代码。客户端对代码的组成一无所知,只需要知道如何执行它。JavaScript 就是一个实现此约束的示例。
理查森成熟度模型
理查森成熟度模型是一种启发式成熟度模型,可以用来更好地了解服务在 REST 架构风格方面的成熟度。

- 0级
此级别的服务被描述为具有单个 URI,并使用单个 HTTP 动词(通常是 POST)。这与大多数 Web 服务 (WS-*) 的特点非常相似,因为它们都具有单个 URI,用于接受包含 XML 有效负载的 HTTP POST 请求。
- 1级
此级别的服务被描述为具有多个 URI,但使用单个 HTTP 动词。0 级和 1 级之间的主要区别在于,1 级服务公开多个逻辑资源,而不是单个资源。
- 2级
此级别的服务被描述为具有许多可通过 URI 寻址的资源。每个可寻址资源都支持多个 HTTP 动词和 HTTP 状态代码。
- 3级
此级别的服务类似于2 级服务,但额外支持超媒体作为应用状态引擎 (HATEOAS)。因此,资源的表示形式还将包含指向其他资源的链接(即与当前资源相关的可执行操作)。
在考虑将RMM应用于您的 API 时,请不要考虑拥有2 级或3 级REST API。根据此模型,除非 API 至少满足RMM的 3 级,否则它不能称为 REST API 。因此,最好将 API 视为满足RMM的1、2 或 3 级的HTTP API 。
2. REST实践
我开发了一个简单的 Http Api 来演示我在本指南第 1 部分中讨论的一些概念。
使用 .Net Core 3.1 以 C# 编写的 REST API 指南和示例项目
我还启动了另一个项目,计划用它来演示各种技术概念,例如 REST API。
用于演示架构、设计、dotnet core、typescript、react、数据库和docker等概念的游乐场
2. 定义合同
在此示例中,我们将为 3 种类型的资源定义合同:
- 用户
- 电影
- 评分
定义合同有5个重要方面:
- 命名资源
- 用于与资源交互的 Http 方法
- 用于描述交互状态的状态代码
- 内容协商
- 保持一致
2.1 命名准则
- 资源应该具有由名词而不是动作(行为)表示的名称
# Incorrect naming
/getUsers
/getUserById/{userId}
# Correct Naming
/users
/users/{userId}
- 资源应使用复数形式命名
# Incorrect naming
/user
/movie
/rating
# Correct naming
/users
/movies
/ratings
- 将 RPC 样式方法映射到资源
命名准则似乎非常适合命名资源。但是,当需要命名一个更像行为而非资源的东西时,该怎么办呢?例如,假设我们要计算一部电影的平均评分。我们应该如何组织命名呢?
/movies/{movieId}/averageRating
我认为,对于像这样的场景,正确的命名策略尚无 100% 的共识。然而,当需要为某种更关乎行为而非资源的事物定义契约时,我喜欢根据这些行为的结果来定义契约。因此,对于上面的例子:
/averageMovieRatings
/averageMovieRatings/{movieId}
但是,如果我们尝试为计算器定义契约呢?这显然是一个围绕行为定义契约非常困难且对 REST 来说“不自然”的例子。之所以感觉不自然,是因为 REST 是一种描述 Web 架构的架构风格。因此,如果你把每个端点都想象成一个网页,那么显然计算器的行为就无法很好地映射。我的建议是,如果你正在构建的 API 更侧重于行为而非资源,那么可以使用 gRPC 之类的替代技术。
- 表示层次结构
/users/{userId}
/users/{userId}/ratings
/users/{userId}/ratings/{ratingId}
/movies/{movieId}
/movies/{movieId}/ratings
/movies/{movieId}/ratings/{ratingId}
- 过滤、搜索和排序不属于命名的一部分
对于过滤:
# Incorrect
/users/firstName/{firstName}
# Correct
/users?firstName={firstName}
搜索:
# Incorrect
/users/search/{query}
# Correct
/users?q={query}
订购方式:
# Incorrect
/users/orderBy/{firstName}
# Correct
/users?order={firstName}
2.2 Http 方法
| Http 方法 | 请求正文 | 乌里 | 回复 |
|---|---|---|---|
| 得到 | - | /用户 | 用户列表 |
| 得到 | - | /用户/{用户ID} | 单个用户 |
| 邮政 | 单个用户 | /用户 | 单个用户 |
| 放 | 单个用户 | /用户/{用户ID} | - |
| 修补 | 用户的 Json 补丁文档 | /用户/{用户ID} | - |
| 删除 | - | /用户/{用户ID} | - |
| 头 | - | /用户 | - |
| 头 | - | /用户/{用户ID} | - |
| 选项 | - | /用户 | - |
2.3 状态码
本节列出了常用的状态码。状态码有助于在客户端/服务器交互中传达含义,也有助于在定义契约方面实现一致性。
第 200 级 - 成功
级别 300 - 重定向响应
- 301 永久移动- 请求资源的 URL 已永久更改。新的 URL 将在响应中提供
- 302 Found - 表示请求资源的 URI 已更改,因此可以在将来的请求中使用相同的 URI
- 304 未修改- 用于缓存。表示资源未发生改变,可以使用相同的缓存版本。
400 级 - 客户端错误
- 400 Bad Request - 由于语法错误,服务器无法理解该请求。客户端不应重复该请求。
- 401 未授权- 由于身份验证失败,请求失败
- 403 Forbidden - 由于授权失败,请求失败
- 404 Not Found - 找不到请求的资源
- 405 方法不允许- 服务器理解但不支持该请求方法。换句话说,服务器没有支持请求方法的端点。
- 406 不可接受- 当使用 Accept 标头指定了不受支持的内容类型时
- 409 冲突- 表示请求的资源状态存在冲突。对于 POST 请求,这可能意味着资源已存在。对于 PUT 请求,这可能意味着资源状态发生变化,从而导致当前请求数据过时。
- 415 不支持的媒体类型- 当响应中指定了不支持的内容类型时
- 422 无法处理的实体- 表示请求正确且服务器理解,但请求中包含的数据无效。
级别 500 - 服务器错误
- 500 内部服务器错误- 表示服务器出现问题,导致服务器无法满足请求。
- 503 服务不可用- 表示服务器正常运行,但无法提供请求的资源。这通常是由于服务器过载、服务器正在维护或客户端与 DNS 服务器相关的问题(DND 服务器可能不可用)。
- 504 网关超时- 表示代理服务器未从源(上游)服务器收到及时响应。
2.4 内容协商
暗示将用于请求和响应的表示类型(媒体类型)。媒体类型在请求标头中指定。Http API 使用的两种常见媒体类型格式是:
- 应用程序/json
- 应用程序/xml
通常情况下,我会至少支持上述两种格式。对于任何不支持的媒体类型格式,API 应该返回406 Not Acceptable状态码。
例子:
# Send POST request to create a a new user.
# The request will use 'application/json' as input, but XML in return (application/xml)
POST /users
Accept: application/xml
Content-Type: application/json
{
"firstName": "Bob",
"lastName": "TheBuilder"
}
# The response is returned as XML
<User>
<Id>112233</Id>
<FirstName>Bob</FirstName>
<LastName>TheBuilder</LastName>
</User>
3.示例项目
为了说明一些已经讨论过的话题,我创建了一个名为Ranker的示例项目。
Ranker是一个以 REST 为指导设计的 API。根据Richardson 成熟度模型,我已将所有端点实现为至少2 级。但是,我已将部分端点实现为3 级(使用 HATEOAS)。从概念上讲, Ranker提供以下功能:
- 管理用户的界面(使用 HATEOAS)
- 电影管理界面
- 管理评级的界面
在以下部分中,我将提供有关该项目及其如何开始的更多详细信息。
建筑学
虽然这个示例项目的重点是说明 REST 的实现,但我决定提供一个基本架构来说明良好的关注点分离,以便 Api 层(控制器)保持非常干净。
我选择了一种基于洋葱架构的架构。下面,我将提供两种不同的视角来解释完全相同的架构。
分层架构

洋葱架构

- API
主要职责:提供访问应用程序功能的分布式接口
此 API 已基于 REST 准则实现为一系列 HTTP 服务。API 本身基于 MVC(模型、视图和控制器)架构。控制器本质上是面向公众的 API 契约。
- 基础设施
主要职责:为系统核心提供面向“世界”的接口。
该层主要定义和配置外部依赖项,例如:
- 数据库访问
- 其他 API 的代理
- 日志记录
- 监控
-
依赖注入
- 应用
主要职责:应用逻辑。
这一层通常是您可以找到“应用程序”服务的地方。
- 领域
主要职责:企业领域逻辑。
所有与领域模型和领域服务相关的领域逻辑都在此层处理。
API 合同
该 API 已根据开放 API 规范 (OAS) 实现。API 启动并运行后,您可以浏览以下 URL 来访问 OAS Swagger 文档。
http://localhost:5000
Swagger 文档如下所示:



分页
对于此项目,任何返回项目集合的端点都已实现分页。请使用以下查询参数来控制分页:
- page - 页码
- 限制——每页的项目数
对于此示例项目,分页已通过两种方式实现。
- 页眉中的分页
GET http://localhost:5000/v1/movies?page=2&limit=5
Header: X-Pagination
{
"CurrentPageNumber": 2,
"ItemCount": 9742,
"PageSize": 5,
"PageCount": 1949,
"FirstPageUrl": "http://localhost:5000/v1/movies?page=1&limit=5",
"LastPageUrl": "http://localhost:5000/v1/movies?page=1949&limit=5",
"NextPageUrl": "http://localhost:5000/v1/movies?page=3&limit=5",
"PreviousPageUrl": "http://localhost:5000/v1/movies?page=1&limit=5",
"CurrentPageUrl": "http://localhost:5000/v1/movies?page=2&limit=5"
}
- 分页作为链接(HATEOAS)
GET http://localhost:5000/v1/users?page=1&limit=1
{
.
.
.
"links": [
{
"href": "http://localhost:5000/v1/users?page=1&limit=1",
"method": "GET",
"rel": "current-page"
},
{
"href": "http://localhost:5000/v1/users?page=2&limit=1",
"method": "GET",
"rel": "next-page"
},
{
"href": "",
"method": "GET",
"rel": "previous-page"
},
{
"href": "http://localhost:5000/v1/users?page=1&limit=1",
"method": "GET",
"rel": "first-page"
},
{
"href": "http://localhost:5000/v1/users?page=610&limit=1",
"method": "GET",
"rel": "last-page"
}
]
}
过滤
在实际可行的情况下,我尝试为每个资源属性提供一个过滤器。我使用了三种技术来实现过滤:
1. 基础
// filter users by last name and age
GET http://localhost:5000/v1/users?last-name=doe&gender=male
2. 范围
对于数字资源(和日期)属性,我实现了范围过滤器,如下所示:
// Possible input for age could be:
// age=gt:30
// age=gte:30
// age=eq:30
// age=lt:30
// age=lte:30
GET http://localhost:5000/v1/users?age=gte:30
3. 多个(逗号分隔的值)
// get a list of movies for the genres animation and sci-fi
GET http://localhost:5000/v1/movies?genres=animation,sci-fi
订购
我选择将排序参数保持得非常简洁。因此,资源集合的排序可以通过以下方式执行:
- 按单个资源属性升序排序
// order by last name ascending
GET http://localhost:5000/v1/users?order=last-name
- 按单个资源属性降序排列
// order by age descending
GET http://localhost:5000/v1/users?order=-age
- 使用混合排序顺序按多个资源属性排序
请注意,我们使用逗号分隔值来表示顺序。
// order by last-name ascending then by age descending
GET http://localhost:5000/v1/users?order=last-name,-age
缓存
我已经实现了一些基本的客户端缓存行为。
例如:
以下端点使用响应缓存,其中缓存在 10 秒后过期。
GET http://localhost:5000/v1/users
GET http://localhost:5000/v1/movies
GET http://localhost:5000/v1/movies/{movieId}
GET http://localhost:5000/v1/ratings
GET http://localhost:5000/v1/ratings/{ratingId}
以下端点使用带有 ETag 的缓存。
GET http://localhost:5000/v1/users/{userId}
仇恨
已实现以下端点以返回链接作为响应的一部分。
// Get links available from root
GET http://localhost:5000/v1
[
{
"href": "http://localhost:5000/v1",
"method": "GET",
"rel": "self"
},
{
"href": "http://localhost:5000/v1/movies",
"method": "GET",
"rel": "movies"
},
{
"href": "http://localhost:5000/v1/movies",
"method": "POST",
"rel": "create-movie"
},
{
"href": "http://localhost:5000/v1/ratings",
"method": "GET",
"rel": "ratings"
},
{
"href": "http://localhost:5000/v1/ratings",
"method": "POST",
"rel": "create-rating"
},
{
"href": "http://localhost:5000/v1/users",
"method": "GET",
"rel": "users"
},
{
"href": "http://localhost:5000/v1/users",
"method": "POST",
"rel": "create-user"
}
]
// Get as single user, including a list of navigational links
GET http://localhost:5000/v1/users
{
"userId": 10,
"age": 30,
"firstName": "Durham",
"lastName": "Franks",
"gender": "male",
"email": "durhamfranks@kog.com",
"links": [
{
"href": "http://localhost:5000/v1/users/10",
"method": "DELETE",
"rel": "delete-user"
},
{
"href": "http://localhost:5000/v1/users/10",
"method": "GET",
"rel": "self"
},
{
"href": "http://localhost:5000/v1/users?Page=1&Limit=10",
"method": "GET",
"rel": "users"
},
{
"href": "http://localhost:5000/v1/users",
"method": "OPTIONS",
"rel": "options"
},
{
"href": "http://localhost:5000/v1/users/10",
"method": "PATCH",
"rel": "patch-user"
},
{
"href": "http://localhost:5000/v1/users",
"method": "POST",
"rel": "create-user"
},
{
"href": "http://localhost:5000/v1/users/10",
"method": "PUT",
"rel": "update-user"
},
{
"href": "http://localhost:5000/v1/users/10/ratings",
"method": "GET",
"rel": "ratings"
}
]
}
对于包含链接的用户集合,我们可以使用以下请求。请注意响应中返回的分页信息
// Get list of users (with links), and paging links
GET http://localhost:5000/v1/users
{
"users": [
{
"userId": 23,
"age": 40,
"firstName": "Michele",
"lastName": "Jacobs",
"gender": "female",
"email": "michelejacobs@kineticut.com",
"links": [
{
"href": "http://localhost:5000/v1/users/23",
"method": "DELETE",
"rel": "delete-user"
},
{
"href": "http://localhost:5000/v1/users/23",
"method": "GET",
"rel": "self"
},
{
"href": "http://localhost:5000/v1/users?Page=1&Limit=10",
"method": "GET",
"rel": "users"
},
{
"href": "http://localhost:5000/v1/users",
"method": "OPTIONS",
"rel": "options"
},
{
"href": "http://localhost:5000/v1/users/23",
"method": "PATCH",
"rel": "patch-user"
},
{
"href": "http://localhost:5000/v1/users",
"method": "POST",
"rel": "create-user"
},
{
"href": "http://localhost:5000/v1/users/23",
"method": "PUT",
"rel": "update-user"
},
{
"href": "http://localhost:5000/v1/users/23/ratings",
"method": "GET",
"rel": "ratings"
}
]
},
{
"userId": 33,
"age": 40,
"firstName": "Barnett",
"lastName": "Griffith",
"gender": "male",
"email": "barnettgriffith@corpulse.com",
"links": [
{
"href": "http://localhost:5000/v1/users/33",
"method": "DELETE",
"rel": "delete-user"
},
{
"href": "http://localhost:5000/v1/users/33",
"method": "GET",
"rel": "self"
},
{
"href": "http://localhost:5000/v1/users?Page=1&Limit=10",
"method": "GET",
"rel": "users"
},
{
"href": "http://localhost:5000/v1/users",
"method": "OPTIONS",
"rel": "options"
},
{
"href": "http://localhost:5000/v1/users/33",
"method": "PATCH",
"rel": "patch-user"
},
{
"href": "http://localhost:5000/v1/users",
"method": "POST",
"rel": "create-user"
},
{
"href": "http://localhost:5000/v1/users/33",
"method": "PUT",
"rel": "update-user"
},
{
"href": "http://localhost:5000/v1/users/33/ratings",
"method": "GET",
"rel": "ratings"
}
]
}
],
"links": [
{
"href": "http://localhost:5000/v1/users?order=-age&page=1&limit=2",
"method": "GET",
"rel": "current-page"
},
{
"href": "http://localhost:5000/v1/users?order=-age&page=2&limit=2",
"method": "GET",
"rel": "next-page"
},
{
"href": "",
"method": "GET",
"rel": "previous-page"
},
{
"href": "http://localhost:5000/v1/users?order=-age&page=1&limit=2",
"method": "GET",
"rel": "first-page"
},
{
"href": "http://localhost:5000/v1/users?order=-age&page=305&limit=2",
"method": "GET",
"rel": "last-page"
}
]
}
4. 使用的技术
操作系统
我已经在以下操作系统上开发并测试了Ranker 。
Ubuntu 是一个开源软件操作系统,可在桌面、云端以及所有连接互联网的设备上运行。
- Windows 10 专业版
除了在 Windows 10 上开发Ranker之外,我还尝试使用Windows Subsystem For Linux测试了Ranker。具体来说,我使用了 [WSL-Ubuntu](此处似有缺失)。有关WSL 的更多信息,请参阅下文。
-
Windows 的 Linux 子系统允许开发人员直接在 Windows 上运行 GNU/Linux 环境(包括大多数命令行工具、实用程序和应用程序),无需修改,也无需虚拟机的开销。
-
注意:我还没有在WSL2上测试过Ranker。我在这里提到这一点是因为我想明确说明我只在WSL上测试过。
WSL 2 是 WSL 架构的新版本,它改变了 Linux 发行版与 Windows 的交互方式。WSL 2 的主要目标是提升文件系统性能并增加完整的系统调用兼容性。每个 Linux 发行版都可以作为 WSL 1 或 WSL 2 发行版运行,并且可以随时切换。WSL 2 对底层架构进行了重大改进,并使用虚拟化技术和 Linux 内核来实现其新功能。
代码
Visual Studio Code 是微软为 Windows、Linux 和 macOS 开发的源代码编辑器。它支持调试、嵌入式 Git 控制、语法高亮、智能代码补全、代码片段和代码重构。
功能齐全、可扩展、免费的IDE,用于为 Android、iOS、Windows 以及 Web 应用程序和云服务创建现代应用程序。
数据库
- 保持简单,仅使用内存数据库
5.入门
在开始之前,必须在您的机器上安装以下框架:
- Dotnet Core 3.1
获取代码
从 GitHub 克隆“ranker”存储库
# using https
git clone https://github.com/drminnaar/ranker.git
# or using ssh
git clone git@github.com:drminnaar/ranker.git
构建代码
# change to project root
cd ./ranker
# build solution
dotnet build
运行 API
从命令行运行 API,如下所示:
# change to project root
cd ./ranker/Ranker.Api
# To run 'Ranker Api' (http://localhost:5000)
dotnet watch run
开放邮递员收藏
我已为Ranker API提供了一个 Postman 集合。请在解决方案的根目录中找到 Postman 集合“Ranker.postman_collection”。

文章来源:https://dev.to/drminnaar/rest-api-guide-14n2