C# 中的基本数据结构和算法
算法复杂度的重要性在于它能告诉我们代码是否可扩展。大多数基础数据结构和算法已经在.NET Framework中实现,因此了解这些数据结构如何工作以及它们在执行基本操作(访问元素、查找元素、删除元素、添加元素)时的时间和内存复杂度至关重要。
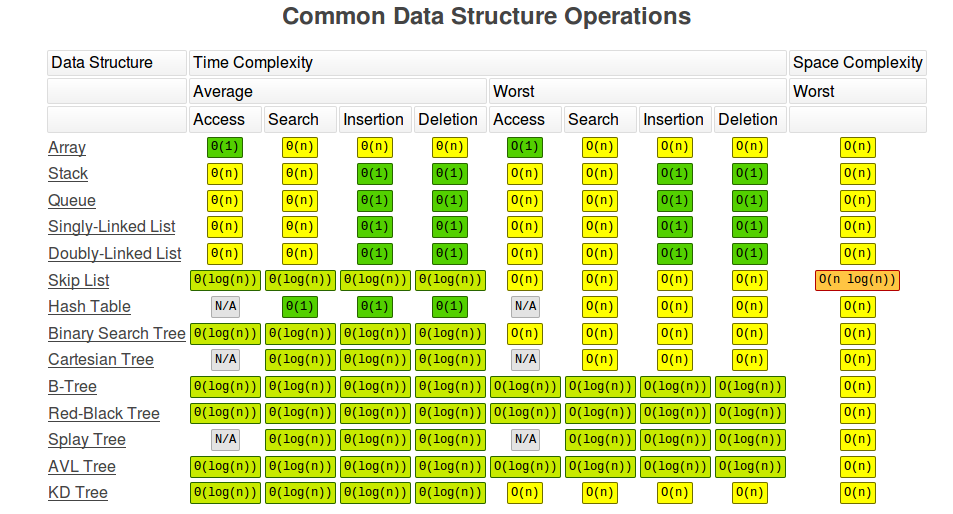
为了了解好的复杂性和不太好的复杂性的含义,我们给出了以下图表:
在.NET Framework中,我们实现了以下数据结构:数组、堆栈、队列、链表和二分查找算法。其余在.NET Framework中找不到的数据结构可以在NuGet 包或GitHub上找到。数组是最常用、最知名的数据结构之一,我不会详细介绍其工作原理。
堆
堆栈是.NET Framework中实现的一种数据结构,有两种实现方式,一种是System.Collections命名空间中的简单堆栈,另一种是System.Collections.Generic命名空间中的作为通用数据结构的堆栈,堆栈结构操作的原则是 LIFO(后进先出),即最后进入的元素先出。
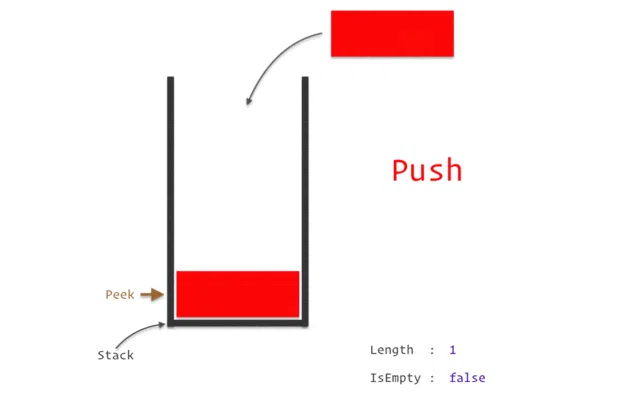
使用命名空间System.Collections中的简单堆栈 的示例:
using System;
using System.Collections;
public class SamplesStack {
public static void Main() {
// Creates and initializes a new Stack.
Stack myStack = new Stack();
myStack.Push("Hello");
myStack.Push("World");
myStack.Push("!");
// Displays the properties and values of the Stack.
Console.WriteLine( "myStack" );
Console.WriteLine( "\tCount: {0}", myStack.Count );
Console.Write( "\tValues:" );
PrintValues( myStack );
}
public static void PrintValues( IEnumerable myCollection ) {
foreach ( Object obj in myCollection )
Console.Write( " {0}", obj );
Console.WriteLine();
}
}
/*
This code produces the following output.
myStack
Count: 3
Values: ! World Hello
*/
使用命名空间System.Collections.Generic中的通用堆栈的示例:
using System;
using System.Collections.Generic;
class Example
{
public static void Main()
{
Stack<string> numbers = new Stack<string>();
numbers.Push("one");
numbers.Push("two");
numbers.Push("three");
numbers.Push("four");
numbers.Push("five");
// A stack can be enumerated without disturbing its contents.
foreach( string number in numbers )
{
Console.WriteLine(number);
}
Console.WriteLine("\nPopping '{0}'", numbers.Pop());
Console.WriteLine("Peek at next item to destack: {0}",
numbers.Peek());
Console.WriteLine("Popping '{0}'", numbers.Pop());
// Create a copy of the stack, using the ToArray method and the
// constructor that accepts an IEnumerable<T>.
Stack<string> stack2 = new Stack<string>(numbers.ToArray());
Console.WriteLine("\nContents of the first copy:");
foreach( string number in stack2 )
{
Console.WriteLine(number);
}
// Create an array twice the size of the stack and copy the
// elements of the stack, starting at the middle of the
// array.
string[] array2 = new string[numbers.Count * 2];
numbers.CopyTo(array2, numbers.Count);
// Create a second stack, using the constructor that accepts an
// IEnumerable(Of T).
Stack<string> stack3 = new Stack<string>(array2);
Console.WriteLine("\nContents of the second copy, with duplicates and nulls:");
foreach( string number in stack3 )
{
Console.WriteLine(number);
}
Console.WriteLine("\nstack2.Contains(\"four\") = {0}",
stack2.Contains("four"));
Console.WriteLine("\nstack2.Clear()");
stack2.Clear();
Console.WriteLine("\nstack2.Count = {0}", stack2.Count);
}
}
/* This code example produces the following output:
five
four
three
two
one
Popping 'five'
Peek at next item to destack: four
Popping 'four'
Contents of the first copy:
one
two
three
Contents of the second copy, with duplicates and nulls:
one
two
three
stack2.Contains("four") = False
stack2.Clear()
stack2.Count = 0
*/
堆栈应用程序:
- 撤消/重做功能
- 词语反转
- 在浏览器上堆叠后退/前进
- 回溯算法
- 支架验证
队列
队列是.NET Framework中实现的一种数据结构,有两种实现方式,一种是System.Collections命名空间中的简单队列,另一种是System.Collections.Generic命名空间中的通用数据结构队列,队列结构的工作原理是FIFO(先进先出),即最先进入的元素先出。
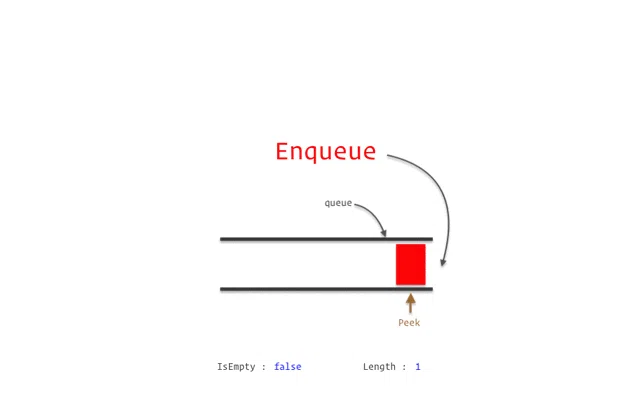
使用命名空间System.Collections中的简单队列 的示例:
using System;
using System.Collections;
public class SamplesQueue {
public static void Main() {
// Creates and initializes a new Queue.
Queue myQ = new Queue();
myQ.Enqueue("Hello");
myQ.Enqueue("World");
myQ.Enqueue("!");
// Displays the properties and values of the Queue.
Console.WriteLine( "myQ" );
Console.WriteLine( "\tCount: {0}", myQ.Count );
Console.Write( "\tValues:" );
PrintValues( myQ );
}
public static void PrintValues( IEnumerable myCollection ) {
foreach ( Object obj in myCollection )
Console.Write( " {0}", obj );
Console.WriteLine();
}
}
/*
This code produces the following output.
myQ
Count: 3
Values: Hello World !
*/
使用命名空间System.Collections.Generic中的通用队列的示例:
using System;
using System.Collections.Generic;
class Example
{
public static void Main()
{
Queue<string> numbers = new Queue<string>();
numbers.Enqueue("one");
numbers.Enqueue("two");
numbers.Enqueue("three");
numbers.Enqueue("four");
numbers.Enqueue("five");
// A queue can be enumerated without disturbing its contents.
foreach( string number in numbers )
{
Console.WriteLine(number);
}
Console.WriteLine("\nDequeuing '{0}'", numbers.Dequeue());
Console.WriteLine("Peek at next item to dequeue: {0}",
numbers.Peek());
Console.WriteLine("Dequeuing '{0}'", numbers.Dequeue());
// Create a copy of the queue, using the ToArray method and the
// constructor that accepts an IEnumerable<T>.
Queue<string> queueCopy = new Queue<string>(numbers.ToArray());
Console.WriteLine("\nContents of the first copy:");
foreach( string number in queueCopy )
{
Console.WriteLine(number);
}
// Create an array twice the size of the queue and copy the
// elements of the queue, starting at the middle of the
// array.
string[] array2 = new string[numbers.Count * 2];
numbers.CopyTo(array2, numbers.Count);
// Create a second queue, using the constructor that accepts an
// IEnumerable(Of T).
Queue<string> queueCopy2 = new Queue<string>(array2);
Console.WriteLine("\nContents of the second copy, with duplicates and nulls:");
foreach( string number in queueCopy2 )
{
Console.WriteLine(number);
}
Console.WriteLine("\nqueueCopy.Contains(\"four\") = {0}",
queueCopy.Contains("four"));
Console.WriteLine("\nqueueCopy.Clear()");
queueCopy.Clear();
Console.WriteLine("\nqueueCopy.Count = {0}", queueCopy.Count);
}
}
/* This code example produces the following output:
one
two
three
four
five
Dequeuing 'one'
Peek at next item to dequeue: two
Dequeuing 'two'
Contents of the copy:
three
four
five
Contents of the second copy, with duplicates and nulls:
three
four
five
queueCopy.Contains("four") = True
queueCopy.Clear()
queueCopy.Count = 0
*/
现实生活中的排队示例:
餐厅销售点的系统。
链表
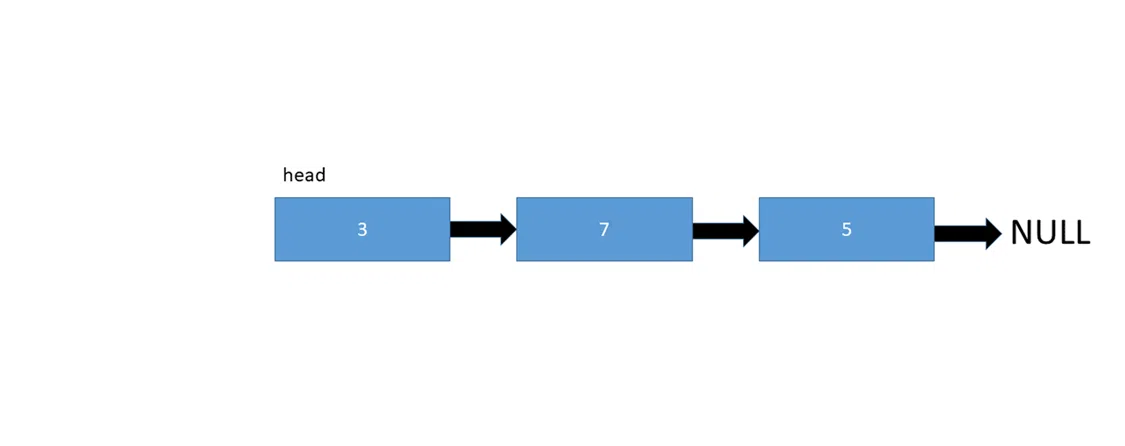
链表是.NET Framework中实现的一种数据结构,在System.Collections.Generic命名空间中作为通用数据结构实现,链表结构的功能原理是列表中的每个节点都引用下一个节点,但列表的尾部除外,它没有对下一个节点的引用。
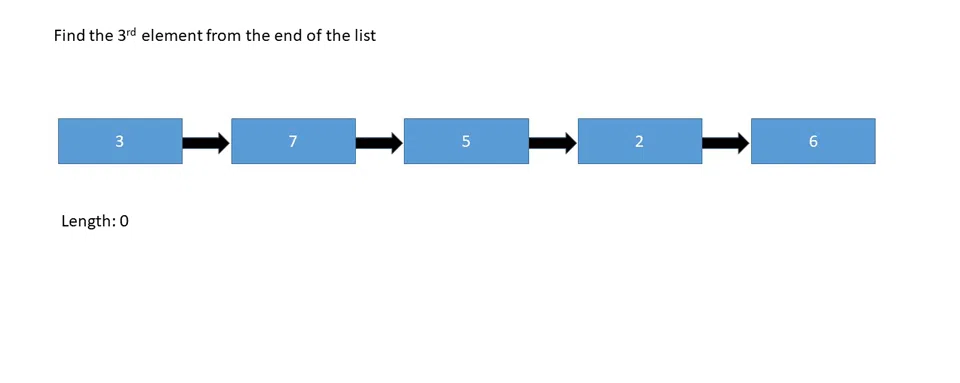
在链表中从末尾开始搜索第三项的示例:
使用命名空间System.Collections.Generic中的通用链接列表 的示例:
using System;
using System.Text;
using System.Collections.Generic;
public class Example
{
public static void Main()
{
// Create the link list.
string[] words =
{ "the", "fox", "jumps", "over", "the", "dog" };
LinkedList<string> sentence = new LinkedList<string>(words);
Display(sentence, "The linked list values:");
Console.WriteLine("sentence.Contains(\"jumps\") = {0}",
sentence.Contains("jumps"));
// Add the word 'today' to the beginning of the linked list.
sentence.AddFirst("today");
Display(sentence, "Test 1: Add 'today' to beginning of the list:");
// Move the first node to be the last node.
LinkedListNode<string> mark1 = sentence.First;
sentence.RemoveFirst();
sentence.AddLast(mark1);
Display(sentence, "Test 2: Move first node to be last node:");
// Change the last node to 'yesterday'.
sentence.RemoveLast();
sentence.AddLast("yesterday");
Display(sentence, "Test 3: Change the last node to 'yesterday':");
// Move the last node to be the first node.
mark1 = sentence.Last;
sentence.RemoveLast();
sentence.AddFirst(mark1);
Display(sentence, "Test 4: Move last node to be first node:");
// Indicate the last occurence of 'the'.
sentence.RemoveFirst();
LinkedListNode<string> current = sentence.FindLast("the");
IndicateNode(current, "Test 5: Indicate last occurence of 'the':");
// Add 'lazy' and 'old' after 'the' (the LinkedListNode named current).
sentence.AddAfter(current, "old");
sentence.AddAfter(current, "lazy");
IndicateNode(current, "Test 6: Add 'lazy' and 'old' after 'the':");
// Indicate 'fox' node.
current = sentence.Find("fox");
IndicateNode(current, "Test 7: Indicate the 'fox' node:");
// Add 'quick' and 'brown' before 'fox':
sentence.AddBefore(current, "quick");
sentence.AddBefore(current, "brown");
IndicateNode(current, "Test 8: Add 'quick' and 'brown' before 'fox':");
// Keep a reference to the current node, 'fox',
// and to the previous node in the list. Indicate the 'dog' node.
mark1 = current;
LinkedListNode<string> mark2 = current.Previous;
current = sentence.Find("dog");
IndicateNode(current, "Test 9: Indicate the 'dog' node:");
// The AddBefore method throws an InvalidOperationException
// if you try to add a node that already belongs to a list.
Console.WriteLine("Test 10: Throw exception by adding node (fox) already in the list:");
try
{
sentence.AddBefore(current, mark1);
}
catch (InvalidOperationException ex)
{
Console.WriteLine("Exception message: {0}", ex.Message);
}
Console.WriteLine();
// Remove the node referred to by mark1, and then add it
// before the node referred to by current.
// Indicate the node referred to by current.
sentence.Remove(mark1);
sentence.AddBefore(current, mark1);
IndicateNode(current, "Test 11: Move a referenced node (fox) before the current node (dog):");
// Remove the node referred to by current.
sentence.Remove(current);
IndicateNode(current, "Test 12: Remove current node (dog) and attempt to indicate it:");
// Add the node after the node referred to by mark2.
sentence.AddAfter(mark2, current);
IndicateNode(current, "Test 13: Add node removed in test 11 after a referenced node (brown):");
// The Remove method finds and removes the
// first node that that has the specified value.
sentence.Remove("old");
Display(sentence, "Test 14: Remove node that has the value 'old':");
// When the linked list is cast to ICollection(Of String),
// the Add method adds a node to the end of the list.
sentence.RemoveLast();
ICollection<string> icoll = sentence;
icoll.Add("rhinoceros");
Display(sentence, "Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':");
Console.WriteLine("Test 16: Copy the list to an array:");
// Create an array with the same number of
// elements as the linked list.
string[] sArray = new string[sentence.Count];
sentence.CopyTo(sArray, 0);
foreach (string s in sArray)
{
Console.WriteLine(s);
}
// Release all the nodes.
sentence.Clear();
Console.WriteLine();
Console.WriteLine("Test 17: Clear linked list. Contains 'jumps' = {0}",
sentence.Contains("jumps"));
Console.ReadLine();
}
private static void Display(LinkedList<string> words, string test)
{
Console.WriteLine(test);
foreach (string word in words)
{
Console.Write(word + " ");
}
Console.WriteLine();
Console.WriteLine();
}
private static void IndicateNode(LinkedListNode<string> node, string test)
{
Console.WriteLine(test);
if (node.List == null)
{
Console.WriteLine("Node '{0}' is not in the list.\n",
node.Value);
return;
}
StringBuilder result = new StringBuilder("(" + node.Value + ")");
LinkedListNode<string> nodeP = node.Previous;
while (nodeP != null)
{
result.Insert(0, nodeP.Value + " ");
nodeP = nodeP.Previous;
}
node = node.Next;
while (node != null)
{
result.Append(" " + node.Value);
node = node.Next;
}
Console.WriteLine(result);
Console.WriteLine();
}
}
//This code example produces the following output:
//
//The linked list values:
//the fox jumps over the dog
//Test 1: Add 'today' to beginning of the list:
//today the fox jumps over the dog
//Test 2: Move first node to be last node:
//the fox jumps over the dog today
//Test 3: Change the last node to 'yesterday':
//the fox jumps over the dog yesterday
//Test 4: Move last node to be first node:
//yesterday the fox jumps over the dog
//Test 5: Indicate last occurence of 'the':
//the fox jumps over (the) dog
//Test 6: Add 'lazy' and 'old' after 'the':
//the fox jumps over (the) lazy old dog
//Test 7: Indicate the 'fox' node:
//the (fox) jumps over the lazy old dog
//Test 8: Add 'quick' and 'brown' before 'fox':
//the quick brown (fox) jumps over the lazy old dog
//Test 9: Indicate the 'dog' node:
//the quick brown fox jumps over the lazy old (dog)
//Test 10: Throw exception by adding node (fox) already in the list:
//Exception message: The LinkedList node belongs a LinkedList.
//Test 11: Move a referenced node (fox) before the current node (dog):
//the quick brown jumps over the lazy old fox (dog)
//Test 12: Remove current node (dog) and attempt to indicate it:
//Node 'dog' is not in the list.
//Test 13: Add node removed in test 11 after a referenced node (brown):
//the quick brown (dog) jumps over the lazy old fox
//Test 14: Remove node that has the value 'old':
//the quick brown dog jumps over the lazy fox
//Test 15: Remove last node, cast to ICollection, and add 'rhinoceros':
//the quick brown dog jumps over the lazy rhinoceros
//Test 16: Copy the list to an array:
//the
//quick
//brown
//dog
//jumps
//over
//the
//lazy
//rhinoceros
//Test 17: Clear linked list. Contains 'jumps' = False
//
哈希表
Hashtable是.NET Framework中一种数据结构,在 .NET Framework 中以两种方式实现:一种是位于命名空间System.Collections中的简单Hashtable ,另一种是位于命名空间System.Collections.Generic中的通用数据结构Dictionary。建议使用 Dictionary 代替 Hashtable。Hashtable 和 Dictionary 的工作原理是构造一个哈希表,该哈希表通常使用多项式作为数组的索引。在 Hashtable 和 Dictionary 中查找的时间复杂度为O(1)。
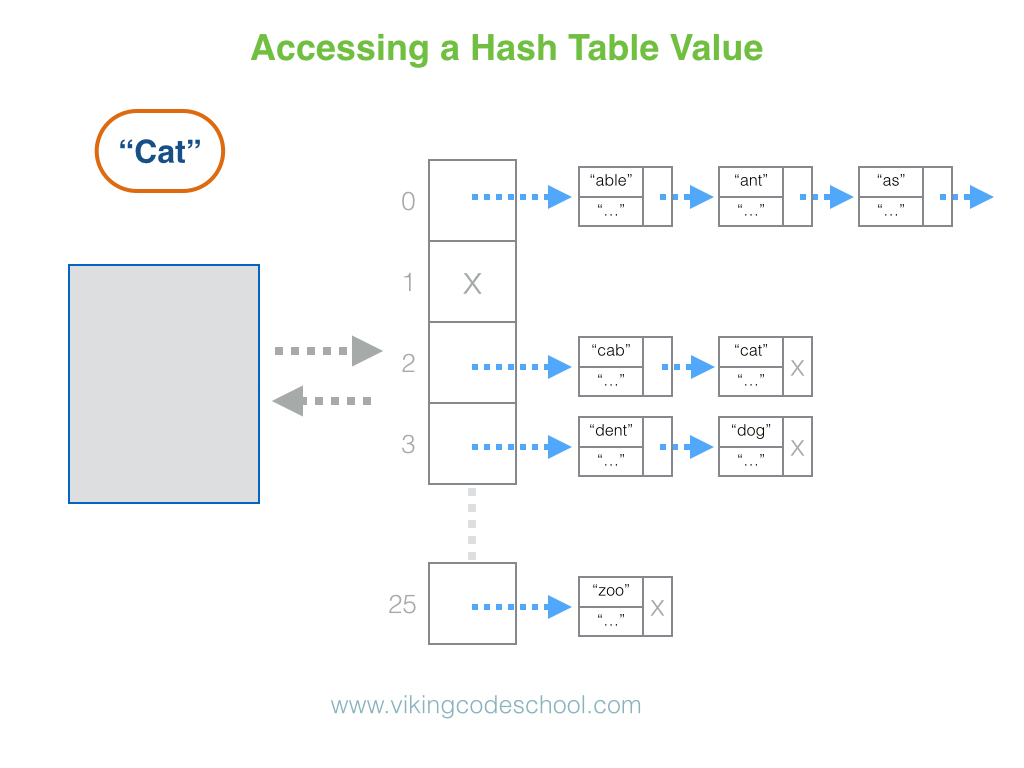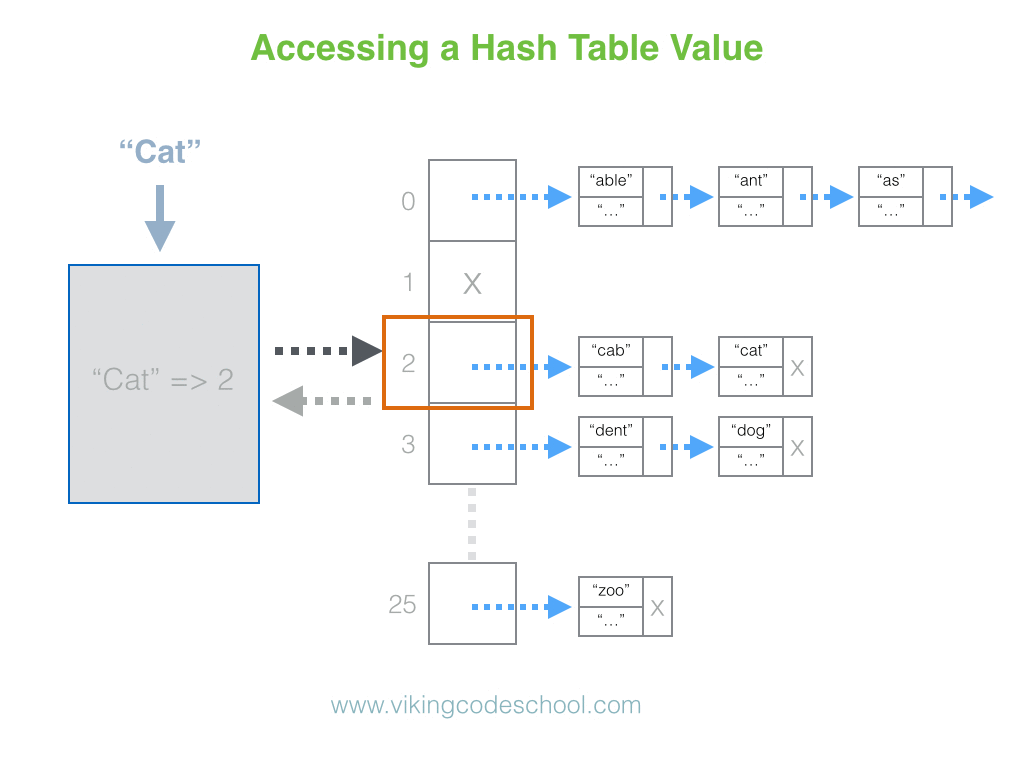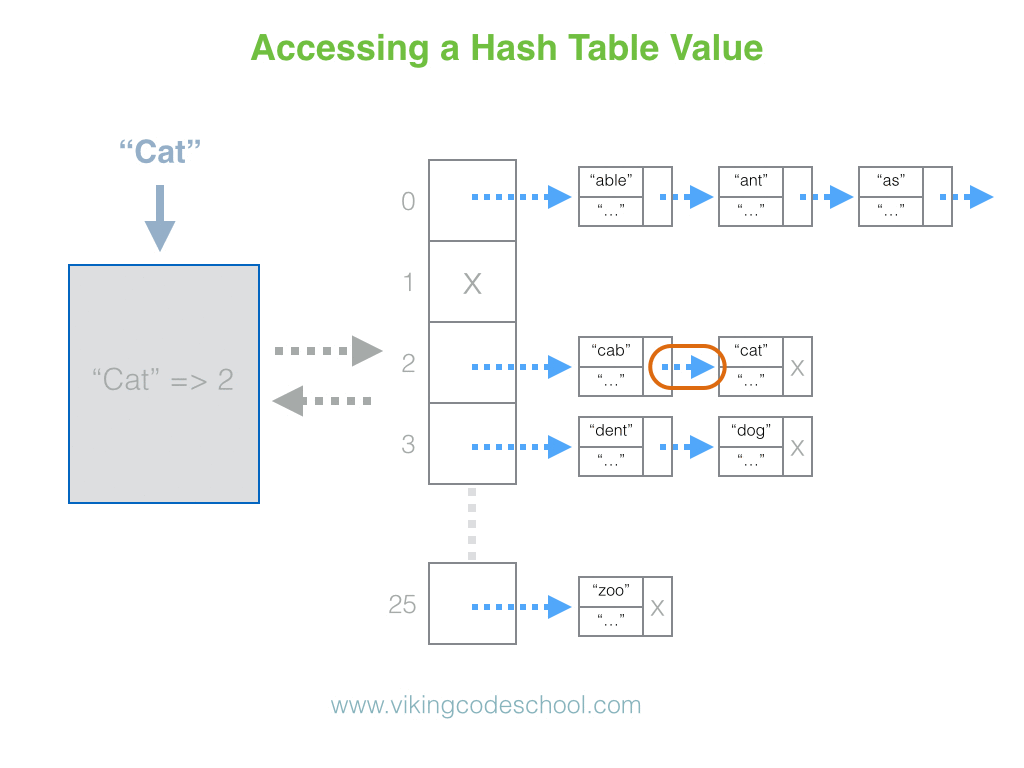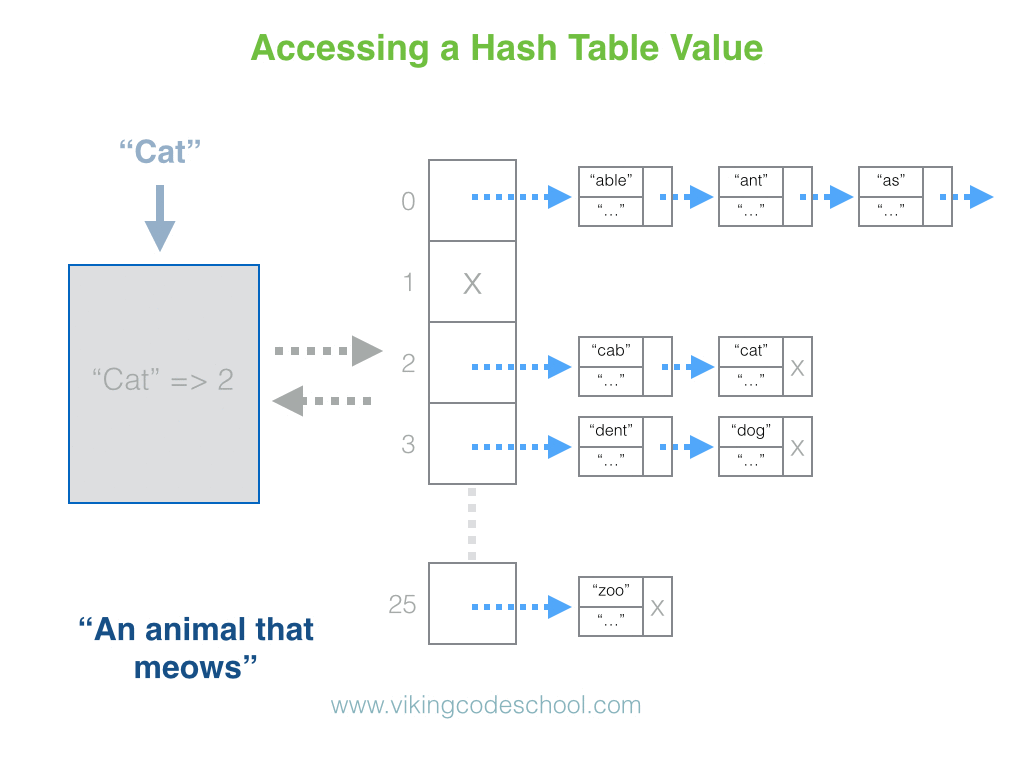
使用来自System.Collections.Generic 命名空间的通用Dictionary 的示例:
// Create a new dictionary of strings, with string keys.
//
Dictionary<string, string> openWith =
new Dictionary<string, string>();
// Add some elements to the dictionary. There are no
// duplicate keys, but some of the values are duplicates.
openWith.Add("txt", "notepad.exe");
openWith.Add("bmp", "paint.exe");
openWith.Add("dib", "paint.exe");
openWith.Add("rtf", "wordpad.exe");
// The Add method throws an exception if the new key is
// already in the dictionary.
try
{
openWith.Add("txt", "winword.exe");
}
catch (ArgumentException)
{
Console.WriteLine("An element with Key = \"txt\" already exists.");
}
// The Item property is another name for the indexer, so you
// can omit its name when accessing elements.
Console.WriteLine("For key = \"rtf\", value = {0}.",
openWith["rtf"]);
// The indexer can be used to change the value associated
// with a key.
openWith["rtf"] = "winword.exe";
Console.WriteLine("For key = \"rtf\", value = {0}.",
openWith["rtf"]);
// If a key does not exist, setting the indexer for that key
// adds a new key/value pair.
openWith["doc"] = "winword.exe";
// The indexer throws an exception if the requested key is
// not in the dictionary.
try
{
Console.WriteLine("For key = \"tif\", value = {0}.",
openWith["tif"]);
}
catch (KeyNotFoundException)
{
Console.WriteLine("Key = \"tif\" is not found.");
}
// When a program often has to try keys that turn out not to
// be in the dictionary, TryGetValue can be a more efficient
// way to retrieve values.
string value = "";
if (openWith.TryGetValue("tif", out value))
{
Console.WriteLine("For key = \"tif\", value = {0}.", value);
}
else
{
Console.WriteLine("Key = \"tif\" is not found.");
}
// ContainsKey can be used to test keys before inserting
// them.
if (!openWith.ContainsKey("ht"))
{
openWith.Add("ht", "hypertrm.exe");
Console.WriteLine("Value added for key = \"ht\": {0}",
openWith["ht"]);
}
// When you use foreach to enumerate dictionary elements,
// the elements are retrieved as KeyValuePair objects.
Console.WriteLine();
foreach( KeyValuePair<string, string> kvp in openWith )
{
Console.WriteLine("Key = {0}, Value = {1}",
kvp.Key, kvp.Value);
}
// To get the values alone, use the Values property.
Dictionary<string, string>.ValueCollection valueColl =
openWith.Values;
// The elements of the ValueCollection are strongly typed
// with the type that was specified for dictionary values.
Console.WriteLine();
foreach( string s in valueColl )
{
Console.WriteLine("Value = {0}", s);
}
// To get the keys alone, use the Keys property.
Dictionary<string, string>.KeyCollection keyColl =
openWith.Keys;
// The elements of the KeyCollection are strongly typed
// with the type that was specified for dictionary keys.
Console.WriteLine();
foreach( string s in keyColl )
{
Console.WriteLine("Key = {0}", s);
}
// Use the Remove method to remove a key/value pair.
Console.WriteLine("\nRemove(\"doc\")");
openWith.Remove("doc");
if (!openWith.ContainsKey("doc"))
{
Console.WriteLine("Key \"doc\" is not found.");
}
/* This code example produces the following output:
An element with Key = "txt" already exists.
For key = "rtf", value = wordpad.exe.
For key = "rtf", value = winword.exe.
Key = "tif" is not found.
Key = "tif" is not found.
Value added for key = "ht": hypertrm.exe
Key = txt, Value = notepad.exe
Key = bmp, Value = paint.exe
Key = dib, Value = paint.exe
Key = rtf, Value = winword.exe
Key = doc, Value = winword.exe
Key = ht, Value = hypertrm.exe
Value = notepad.exe
Value = paint.exe
Value = paint.exe
Value = winword.exe
Value = winword.exe
Value = hypertrm.exe
Key = txt
Key = bmp
Key = dib
Key = rtf
Key = doc
Key = ht
Remove("doc")
Key "doc" is not found.
*/
哈希表应用:
- 用于快速数据查找——编译器符号表
- 索引数据库
- 缓存
- 独特的数据表示
当然,.NET Framework包含一些针对特定问题进行优化的数据结构,本文的目的不是介绍.NET Framework中的所有数据结构,而只介绍算法和数据结构课程中常见的数据结构。
二分查找
查找算法是算法和数据结构课程中的另一个主题,我们可以使用复杂度为O(n) 的顺序查找,或者如果元素已排序,复杂度为O(log n) 的二分查找。 二分查找的思想是,我们访问中间元素,并将其与被查找元素进行比较,如果中间元素较小,则重复递归过程的前半部分,否则,继续查找后半部分。.NET Framework中的二分查找由Array.BinarySearch实现。以下是使用.NET Framework中的Array.BinarySearch方法进行二分查找 的示例: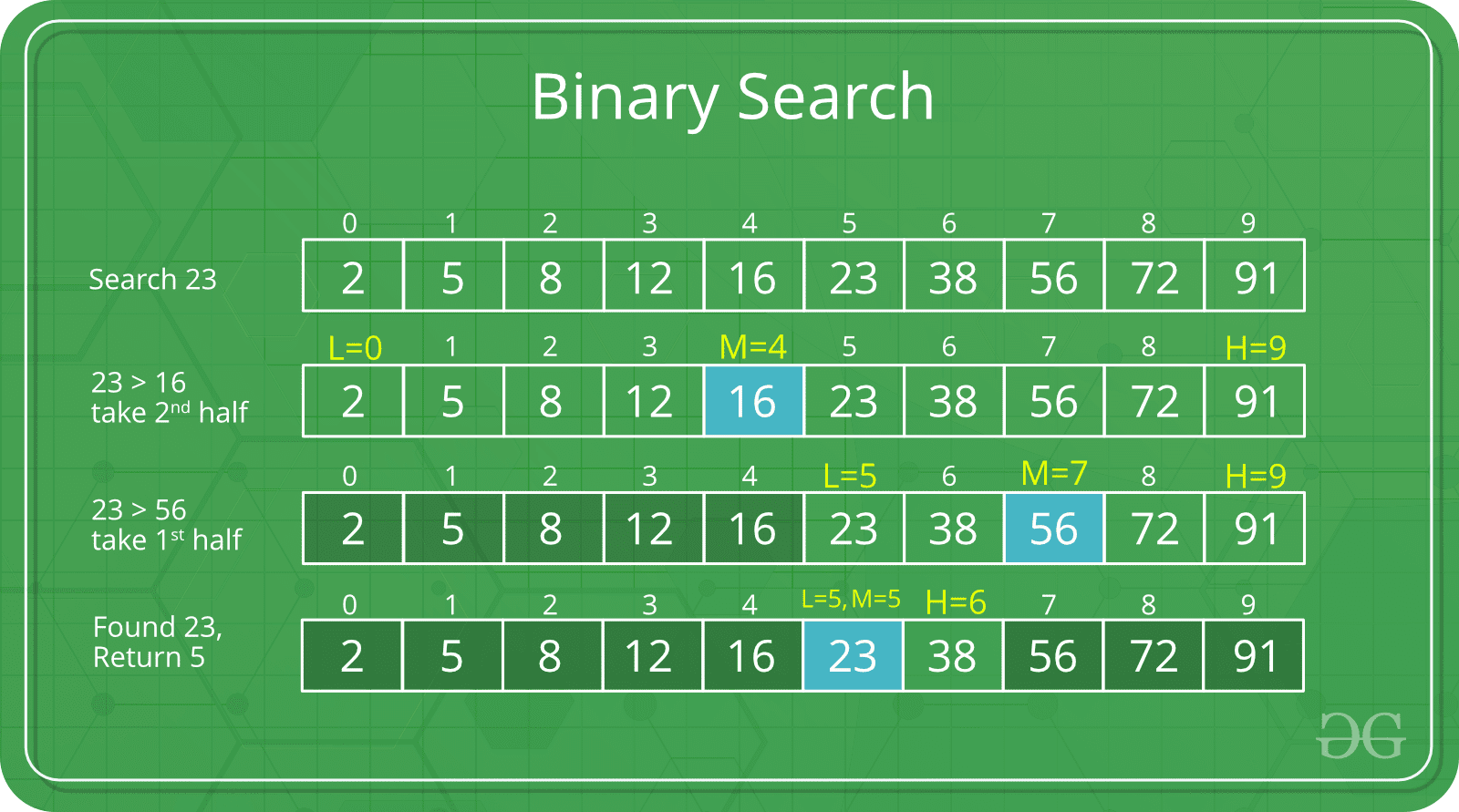
ass Program
{
static void Main(string[] args)
{
// Create an array of 10 elements
int[] IntArray = new int[10] { 1, 3, 5, 7, 11, 13, 17, 19, 23, 31 };
// Value to search for
int target = 17;
int pos = Array.BinarySearch(IntArray, target);
if (pos >= 0)
Console.WriteLine($"Item {IntArray[pos].ToString()} found at position {pos + 1}.");
else
Console.WriteLine("Item not found");
Console.ReadKey();
}
二叉搜索树
GitHub 存储库,其中包含大多数数据结构的自定义实现:https://github.com/aalhour/C-Sharp-Algorithms。
我将继续介绍二叉搜索树。其思想是有一个节点根,每个节点最多有两个子节点,左侧节点小于根,其左子树也小于根,右侧节点大于根,其右子树也大于根。
二叉树构造示例:

二叉搜索树的搜索时间复杂度为O(log n),二叉树搜索示例:
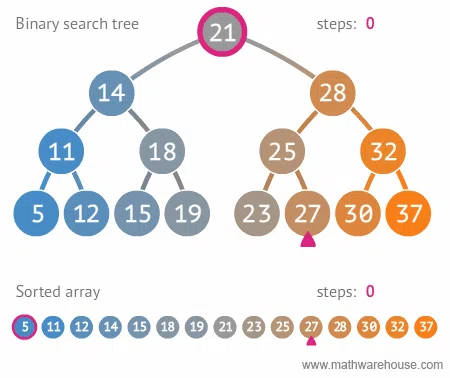
二叉搜索树遍历:
前序
- 根治
- 遍历左子树
- 遍历右子树
为了
- 遍历左子树
- 根治
- 遍历右子树
后序
- 遍历左子树
- 遍历右子树
- 根治
在.NET Framework中,SortedList数据结构内部使用二叉树来保存已排序的元素。
图表
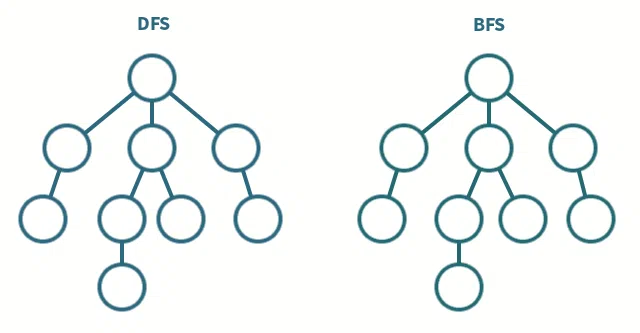
图是一种数据结构,其特征是节点和连接节点的边,通常使用符号G = (V, E)表示,其中 V 表示节点(顶点,顶点)的集合,E 表示边(边)的集合。在编程语言中,图可以用邻接矩阵表示,例如 [i, j] = k,这意味着节点 i 和 j 之间有一条权重为 k 的边,邻接列表也用于表示它们。图和树也可以在广度(广度优先)上用队列交叉,在深度(深度优先)上用堆栈交叉。
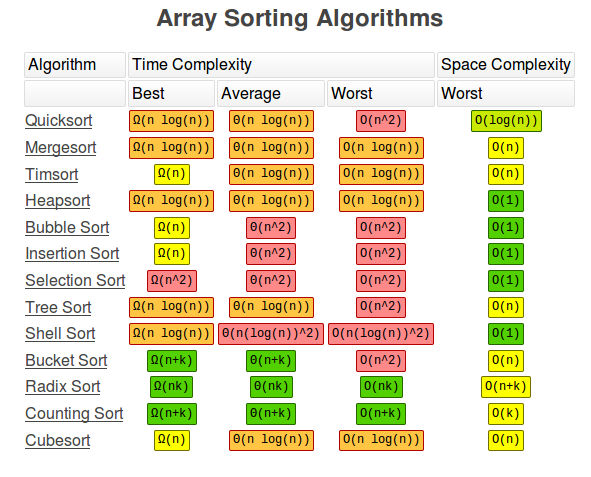
排序算法
排序算法是算法和数据结构课程的另一个主题,其复杂性如下表所示: