如果说 TDD 是禅宗,那么添加无服务器则带来涅槃
如果说 TDD 是禅宗,那么添加无服务器则带来涅槃
如果说 TDD 是禅宗,那么添加无服务器则带来涅槃
今天,我们将使用 TDD 和无服务器为您的初创公司构建梦想的后端。
传统的 API 服务器已经取得了长足的进步,但当今快速发展的项目需要认真考虑无服务器,越早越好。
作为尽快交付的首要要求,常见的副作用是,一旦产品和团队发展壮大,代码库和基础设施就会变得更难维护。
无服务器架构可以通过多种方式缓解这种情况:
-
Lambda 函数鼓励编写细粒度、干净和具体的 API 操作。
-
他们还强制将代码与本地架构(url、端口等)分离。
-
结合 TDD,您可以更快、更精简地进行开发。
-
没有服务器就意味着没有系统管理员。您可以将更多时间投入到项目上。
简而言之,我们要探讨的是:
-
一个干净的无服务器 API 项目
-
准备进行测试驱动开发
-
连接到云数据库(MongoDB Atlas)
-
使用秘密管理
-
具有自动化部署
-
使用暂存环境
那么让我们开始吧!
开始吧!
首先,确保您的系统上有NodeJS并安装无服务器框架:
npm i -g serverless (Windows)
sudo npm i -g serverless (Linux and MacOS)
云帐户
在Amazon Web Services上创建一个帐户,完成后打开IAM 管理控制台。您需要添加一个新用户。

给它一个有意义的名字并为其启用“程序访问”。

现在,我们还处于开发阶段,因此我们将附加AdministratorAccess策略并继续开展项目。
重要提示:当项目准备好投入生产时,请返回 lambda IAM 用户并查看此文章,了解如何应用最小特权原则。

我们的 AWS 用户现已准备就绪。复制屏幕上显示的密钥并在控制台中运行:
serverless config credentials --provider aws --key <the-access-key-id> --secret <the-secret-access-key>
完成了!您的无服务器环境已准备好连接到 Amazon 并发挥其魔力。现在我们来连接一个数据库。
选择特定数据库超出了本文的讨论范围。由于 MongoDB 是最流行的 NoSQL 数据库之一,我们将在MongoDB Atlas上开设一个帐户。
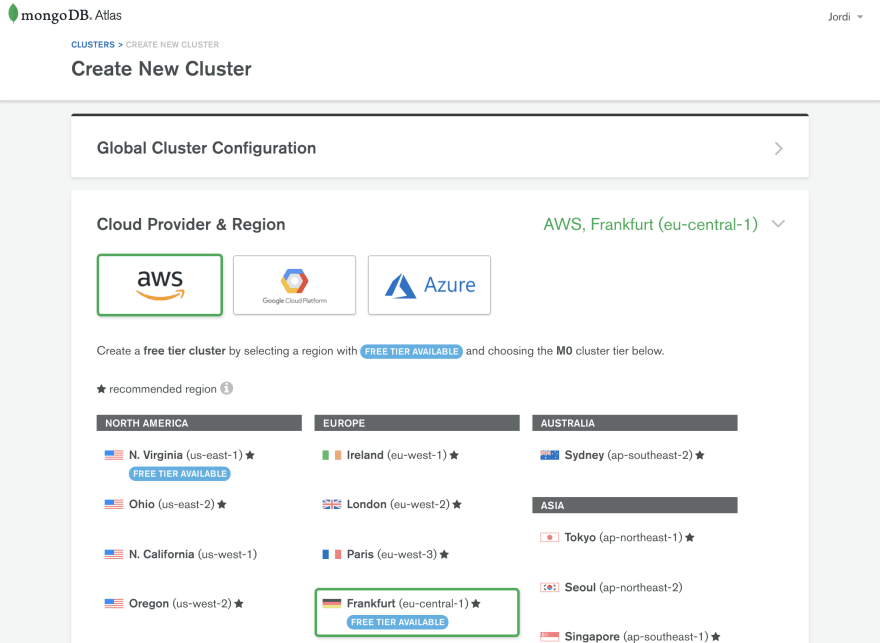
选择符合您需求的提供商和区域。由于我们的代码将在 AWS Lambda 上运行,因此选择AWS作为提供商,并选择与部署 Lambda 相同的区域是合理的。
检查所有附加设置,并为集群选择一个名称。等待几分钟完成配置。
准备就绪后,打开集群的“安全”选项卡并添加新用户。

由于我们只是测试,请输入您选择的用户名/密码并选择“读取和写入任何数据库”。
重要提示:当您准备投入生产环境时,您应该再次应用最小权限原则,并将权限限制在应用的数据库范围内。您还应该为生产环境和预发布环境创建不同的用户。

保留用户名和密码,然后返回集群概览。点击“连接”按钮。接下来,我们需要将允许连接到数据库的 IP 地址列入白名单。遗憾的是,在 AWS Lambda 上,我们无法确定连接到 MongoDB Atlas 的 IP 地址。因此,唯一的选择是选择“允许从任何地方访问”。

最后,点击“连接您的应用程序”,选择版本 3.6 并复制 URL 字符串以供日后使用。

让我们开始编码吧!
帐户设置好了,现在开始动手吧。打开控制台,在文件夹 上创建一个 NodeJS 项目my-api:
serverless create --template aws-nodejs --path my-api
cd my-api
让我们调用默认函数:
serverless invoke local -f hello
(output)
{
"statusCode": 200,
"body": "{\"message\":\"Go Serverless v1.0! Your function executed successfully!\",\"input\":\"\"}"
}
好的,正在运行。让我们创建package.json并添加一些依赖项:
npm init -y
npm i mongodb
npm i -D serverless-offline serverless-mocha-plugin
接下来,我们来定义环境。Serverless CLI 已经为我们创建了 serverless.yml 文件。清理它并编辑 serverless.yml 文件,如下所示:
这里有几点需要注意:
-
我们正在使用 NodeJS 8.10 来获取现代 Javascript 的优点。
-
我们定义了之前在 MongoDB Atlas 上选择的相同区域。
-
默认情况下,hello函数被添加到
handlers.js -
我们在底部添加了两个插件(来自之前安装的依赖项)。以 Daft Punk 的风格,它们将帮助我们开发得更好、更快、更强大。
现在我们可以开始在本地计算机上监听传入的 HTTP 请求:
serverless offline start

因此,如果我们打开浏览器并访问http://localhost:3000,我们将获得 hello 函数的输出,该输出/默认附加到路径。除了函数获取的 HTTP 标头和参数之外,输出是一条消息。

更酷的是,如果我们编辑 handlers.js,让 hello 返回不同的内容,你会发现刷新浏览器会显示更新后的内容。开箱即用的实时刷新 API !
在进入 TDD 环境之前,让我们先整理一下我们的项目并安排好我们的文件和路线。
mkdir handlers test
rm handler.js
touch handlers/users.js
我们将支持的路线是:
GET /users
GET /users/<id>
POST /users
PUT /users/<id>
DELETE /users/<id>
那么让我们编辑serverless.yml并定义它们。编辑functions:代码块以包含以下行:
如您所见,函数块中的每个键都是一个 Lambda 函数的名称。请注意,这handler: handlers/users.list将转换为:
使用list其中的 JS 函数handlers/user.js。
是时候进行 TDD 了!
无服务器 CLI 提供了一个命令来为每个函数添加新的测试。我们来检查一下:
serverless create test -f listUsers
serverless create test -f getUser
serverless create test -f addUser
serverless create test -f updateUser
serverless create test -f removeUser
测试文件夹现在包含每个 Lambda 函数的虚拟规范文件。由于所有与用户相关的函数都指向同一个文件,handlers/users.js因此规范最好保持相同的结构。
因此,让我们丢弃孤立的规范rm test/*,将它们合并为一个文件,并在其中编写完整的用户规范test/users.spec.js。
如您所见,我们不是只导入一个函数包装器,而是导入所有函数包装器并为整个集合定义测试用例。
您可能还注意到,我们并没有执行 HTTP 请求。而是必须像函数接收参数那样传递它们。如果您有兴趣像 HTTP 客户端那样进行规范,请查看这个库。
如果我们运行测试套件,现在会发生什么?
serverless invoke test
你猜对了!轰!那是因为……我们还没写处理程序!不过你也知道:在 TDD 中,规范是在应用逻辑之前编写的。
因此,由于我们的运行时是 NodeJS 8,我们可以利用 ES6/ES7 的特性在 lambda 函数中编写更简洁的代码。让我们在 中实现(仍然未定义的)函数handlers/users.js:
请注意,与传统的 NodeJS 服务器不同,无服务器服务器每次执行时都需要打开和关闭与数据库的连接。这是由于无服务器工作方式的本质:没有进程始终在运行。相反,实例会在外部事件发生时创建和销毁。
另请注意,所有路由务必始终关闭数据库连接。否则,NodeJS 内部事件循环会保持进程处于活动状态,直到超时为止,这可能会产生更高的费用。
最后,请注意,由于使用了 NodeJS v8,我们可以返回响应,而不是使用带有错误优先参数的回调。
现在,我们的规范已经准备好了,实现也已经完成了。关键时刻到了:

太棒了!这是我们的第一个无服务器 API。正如你所见,本地执行时间并不令人印象深刻,但请记住以下几点:
-
我们的目标并非单一请求的速度,而是并发的大规模可扩展性、易于维护性和面向未来的代码。
-
延迟主要源于本地计算机连接到远程数据库所花费的时间。包含 3~4 个数据库请求的测试会比代码在数据中心内运行时的延迟高得多。
-
我们正在使用尽可能轻的实现(
mongodb而不是,以及在 Serverless 之上mongoose使用纯 JS 而不是 Express/Connect )。 -
如果切换到本地 MongoDB 服务器,运行测试将需要大约 80 毫秒。
当我们的代码部署时,我们将检查性能。
秘密管理
我们几乎已做好部署准备,但在此之前我们需要处理一个重要方面:将凭据保留在代码库之外。
幸运的是,Serverless 从 1.22 版本开始支持Simple Systems Manager (SSM)。这意味着我们可以将键/值数据存储到 IAM 用户,并在 Serverless 需要解析机密信息时自动检索这些数据。
因此,首先让我们回到我们的handlers/users.js文件,复制当前的 URL 字符串并替换:
const uri = "mongodb+srv://lambda:lambda@myapp...."
和:
const uri = process.env.MONGODB_URL
接下来,让我们在 serverless.yml 中向提供程序添加一个环境块:
provider:
name: aws
runtime: nodejs8.10
stage: prod
region: eu-central-1
environment:
MONGODB_URL: ${ssm:MY_API_MONGODB_URL~true}
这将在部署时MONGODB_URL将环境变量绑定到MY_API_MONGODB_URLSSM 密钥,并使用默认 IAM 用户的密钥解密内容。~true
最后,让我们获取刚刚复制的字符串并将凭证存储在我们的 SSM 中:
pip install awscli # install the AWS CLI if necessary
aws configure # confirm the key/secret, define your region
aws ssm put-parameter --name MY_API_MONGODB_URL --type SecureString --value "mongodb+srv://lambda:xxxxxx@myapp-.....mongodb.net/my-app?retryWrites=true"
如果您是更大团队的一员,请阅读此处。
部署
别急,我们快完成了!让我们把代码部署到云端。serverless.yml之前我们会更新。然后:
serverless deploy

准备好了!您也可以在这里管理它们(选择合适的区域)。
如果您调用与 listUsers 函数对应的 URL,您将看到延迟时间不到我们计算机延迟时间的三分之一。

发生这种情况是因为现在 lambda 函数和数据库服务器位于同一区域(即数据中心),因此它们之间的连接延迟显著降低。我们与亚马逊的往返行程将始终存在,但现在数据库连接将不再存在。
生产
正如文章中已经评论的那样,当您的 API 准备好发布时:
-
从您的 IAM 用户中删除管理权限,并参考此页面了解如何授予细粒度权限。
-
将数据库用户的权限限制为仅限应用程序的数据库,而不仅仅是任何数据库。
部署应仅由项目维护人员进行。其余开发人员无需配置任何 IAM Lambda 凭证。
打扫
部署 Lambda 函数至少需要 Amazon 的三种不同服务。如果您打算擦除现有的 Lambda 函数,则需要执行以下操作:
-
从 AWS Lambda 中删除该函数
-
从S3中删除相应的bucket
-
从 CloudFormation 中删除相应的堆栈
包起来
希望你喜欢阅读这篇文章,就像我喜欢写这篇文章一样。如果你想了解更多,请点赞、评论、分享,然后微笑 🙂!
如果您想尝试本文的代码,请随时从 GitHub 克隆入门代码库:https://github.com/ledfusion/serverless-tdd-starter/tree/part-1
顺便说一句:我随时可以帮助您扩展项目。
欢迎访问https://jordi-moraleda.github.io/联系我。
附加曲目 #1:Staging
如果您和我们大多数人一样,那么您的项目至少需要 3 个环境:开发、登台和生产。
对于数据库,开发人员可以使用 MongoDB 的本地实例来加快连接速度,但对于暂存和生产,我们需要提供完全独立的数据库环境。
返回 MongoDB Atlas 并创建两个不同的用户帐户(my-app-prod 和 my-app-staging),以访问两个不同的数据库(分别为 my-app-prod 和 my-app-staging)。
让我们删除之前创建的密钥:
aws ssm delete-parameter --name MY_API_MONGODB_URL
并创建两个用于生产和登台:
# PROD
aws ssm put-parameter --name MY_API_MONGODB_URL_prod --type SecureString --value "mongodb+srv://my-app-prod:xxxxxx@myapp-.....mongodb.net/my-app-prod?retryWrites=true"
# STAGING
aws ssm put-parameter --name MY_API_MONGODB_URL_staging --type SecureString --value "mongodb+srv://my-app-staging:xxxxxx@myapp-.....mongodb.net/my-app-staging?retryWrites=true"

现在让我们编辑serverless.yml>provider并做一些魔术:
首先,stage 字段告诉 Serverless 在哪里部署 lambda。如果你像下面这样部署:
serverless deploy --stage prod
那么,provider.stage将是"prod"。如果我们直接运行,serverless deploy那么provider.stage将默认为"dev"。
其次,根据环境, 的值MONGODB_URL分两步评估。如果我们启用了"prod"或"staging",Serverless 将分别从 SSM 获取MY_API_MONGODB_URL_prod或MY_API_MONGODB_URL_staging并使用该值。如果我们的 IAM 用户没有该键,MONGODB_URL则默认为"mongodb://localhost:27017"。
太棒了!这使得我们的开发团队可以从本地数据库进行编码和测试,而在 AWS 上运行的代码将获取远程 URL 连接字符串。

它们就在这里,所以准备和制作已经准备就绪!

附加功能 #2:自动化任务
正如标题所示,我们追求的是涅槃,而非禅宗。输入重复的命令可能会有点繁琐,所以让我们用一组简洁的命令来结束我们的演示,以便更好地完成这个项目。
总结一下,我们在项目生命周期中可能执行的操作包括:
-
在本地运行应用程序
-
运行测试套件
-
运行测试套件,如果成功则部署到暂存区
-
运行测试套件,如果成功则部署到生产环境
因此,让我们在 package.json 上定义这些操作:
...
"scripts": {
"deploy": "npm test && sls deploy --stage staging",
"deploy:prod": "npm test && sls deploy --stage prod",
"start": "serverless offline start",
"test": "serverless invoke test"
},
现在,团队可以使用 运行 APInpm start并使用 进行测试npm test,而项目维护人员可以使用 部署到暂存区npm run deploy并使用 部署到生产环境npm run deploy:prod。没有人会干扰非预期的设置、数据或环境。
完成这一系列集成工作后,您应该拥有一个易于编码、测试、升级和维护的后端。它应该能够很好地适应敏捷团队和快速发展的公司,我希望它也能满足您的需求!
感谢您的阅读。
如果您喜欢它,请不要错过本文的第二部分。
这篇文章最初发布在medium.com上。
鏂囩珷鏉ユ簮锛�https://dev.to/ledfusion/if-tdd-is-zen-adding-serverless-brings-nirvana-545c