如何在 node.js 中构建高可用/容错服务
如何在 node.js 中构建高可用/容错服务
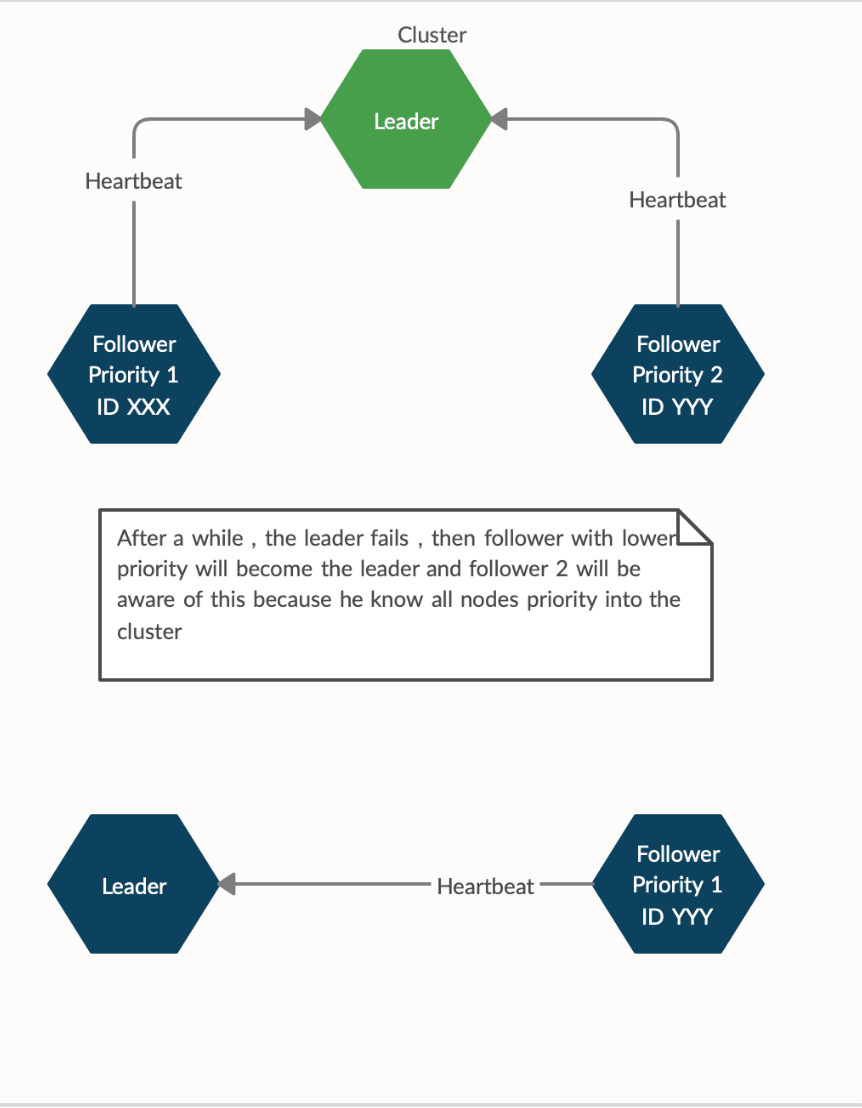
领导者失败
如何在 node.js 中构建高可用/容错服务
在为一位重要客户工作期间,我考虑了高可用性和恢复 NFR。我们的技术栈包括 Cassandra 和 Kafka,我研究了这两个分布式系统的内部行为。Kafka使用 Zookeeper来
跟踪分配给每个消费者的分区,Cassandra在节点之间使用Gossip算法,并按分区范围划分数据。 因此,我开始思考是否有任何库(不是像 Zookeeper 这样的外部服务)实现了 Gossip 算法,以便人们可以更轻松地构建一些新的分布式系统。但是那个库并不存在,然后我创建了Ring-election。 您可以将 Ring-election 集成到您的节点进程中,这样您就拥有了一些已经构建的重要 NFR!
环选驱动程序为您提供什么?
- 对象的默认分区器返回该对象被分配到的分区。
- Leader 选举机制
- 节点之间的故障检测。
- 节点之间的分区分配和重新平衡
- 自动重新选举领导者
- 监听新分配/撤销的分区
您可以使用这个驱动程序解决哪些问题?
- 可扩展性
- 高可用性
- 集群中节点之间的并发
- 自动故障转移
其工作原理
术语
- Leader,负责处理集群且没有分配分区的节点
- 追随者,一个将分配分区并对其进行处理的节点
- 心跳,跟随者节点定期向领导节点发送消息,以跟踪其是否处于活动状态。
- Heartcheck,在领导者上运行的一个进程,用于检查每个追随者收到的最后一个心跳
- 优先级是根据每个跟随者加入集群的时间分配的。当一个节点死亡时,优先级会降低1。如果领导者死亡,优先级较低的节点将成为领导者。
- 节点 ID,每个跟随节点都有一个分配的 ID,该 ID 在集群中是唯一的
启动阶段描述

检测跟随者故障(心跳/心跳检查)
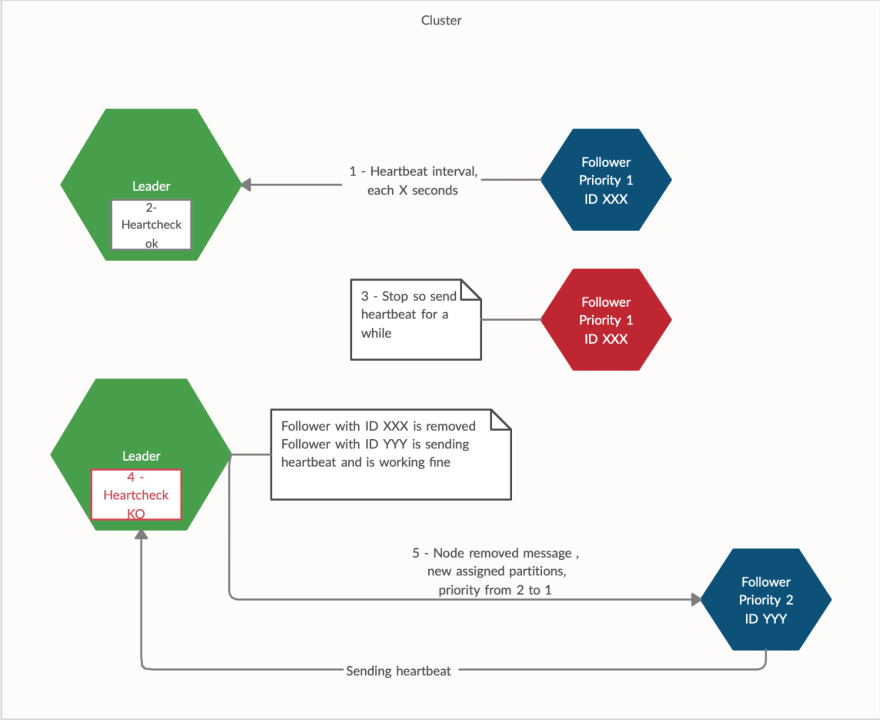
领导者失败
如何整合它?
访问https://github.com/pioardi/ring-election获取更多信息。
如果您想建议新功能,或者需要帮助集成 ring-election,请在 GitHub 上提交一个问题,我很乐意为您提供帮助。