Apache Kafka 如何工作?Kafka 为什么这么快?
披露:本帖包含附属链接;如果您通过本文提供的不同链接购买产品或服务,我可能会收到报酬。

image_credit - Exponent
大家好,开发人员,今天,在之前的几篇文章中,我讨论了基本的软件架构组件和系统设计概念,例如API 网关与负载均衡器、水平扩展与垂直扩展、正向代理与反向代理,今天,我将讨论一个有趣的话题和一项热门技能,Apache Kafka。
我曾在不同的消息传递平台上工作过,从 TIBCO RV 到 JMS、MQ Services、ActiveMQ、RabbitMQ,现在正在研究 Apache Kafka。
在最近的一次采访中,我被问到Apache Kafka 如何工作以及为什么它被认为是一个快速消息传递平台,我无法令人信服地回答这个问题,所以我研究并了解了更多关于 Kafka 内部工作原理的知识,今天,我将与大家分享这一经验。
如果您从事软件开发,特别是应用程序开发,那么您可能知道 Apache Kafka 已经成为分布式数据流领域的标准技术,以其卓越的速度和可扩展性而闻名。
从科技巨头(LinkedIn)到金融机构等各行各业的组织都依赖 Kafka 实时处理大量数据。
之前,我谈到了Kafka、RabbitMQ 和 ActiveMQ 之间的区别,在本文中,我们将深入探讨使 Kafka 如此快速的因素,并研究有助于其速度的底层原理。
顺便说一句,如果你正在准备系统设计面试,并且想要深入学习系统设计,那么你也可以查看ByteByteGo、Design Guru、Exponent、Educative和Udemy等网站,它们有很多很棒的系统设计课程
Apache Kafka 为何如此之快?
在数据流领域,速度往往至关重要。无论是追踪网站上的用户活动、处理金融交易,还是监控物联网设备,组织都需要一个能够以最小延迟处理连续数据流的系统。
Kafka 在这方面表现出色,其速度可归因于几个关键因素。
1.分布式架构
Kafka 速度快的核心在于其分布式架构。与传统的消息队列系统不同,Kafka 不依赖单个集中式服务器来处理所有数据。
相反,它将数据分布在多个节点或代理之间。
这种并行处理能力使得 Kafka 能够水平扩展,这意味着它可以通过向集群添加更多机器来处理不断增加的数据量。
在分布式 Kafka 设置中,每个代理负责一部分数据并且可以独立运行。
这种并行性确保了系统的整体吞吐量随着更多代理的添加而增加,从而使 Kafka 具有高度的可扩展性。
有效分配工作负载的能力是 Kafka 速度快的根本原因,使其能够实时处理大量数据。
但是,如果您是 Kafka 的完全初学者,那么参加初级 Kafka 课程(例如Apache Kafka 系列 - 初学者学习 Apache Kafka V2)将帮助您更好地理解 Kafka 架构。
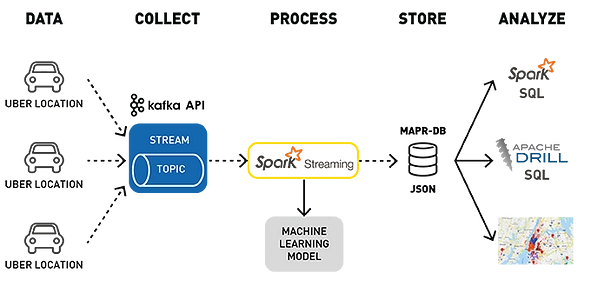
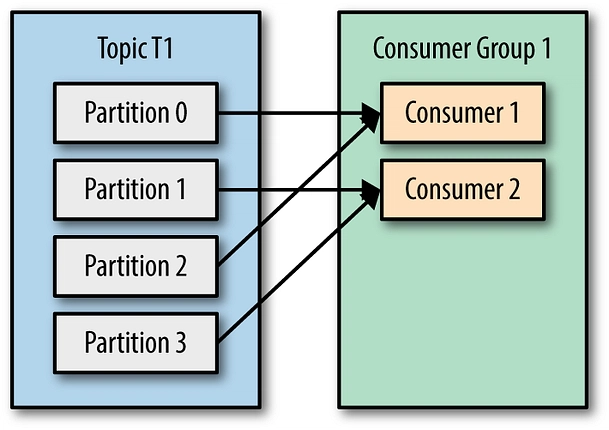
2.分区
分区是 Kafka 的核心概念,它极大地提升了 Kafka 的速度。数据被划分到不同的分区,每个分区分配给特定的 Broker。
这种数据划分使得 Kafka 可以并行处理消息。
在消息生成和使用过程中,Kafka 确保每个分区在任何给定时间都由单个消费者处理。
分区的使用使 Kafka 能够同时实现并行性和顺序性。在分区内,消息按顺序处理,从而确保事件的顺序得到维护。
但是,由于不同的分区可以由不同的代理或消费者独立处理,因此 Kafka 可以实现高度的并行性。
下面是一张展示 Apache Kafka 分区的图表:
3. 写入和读取优化
Kafka 针对写入和读取操作进行了优化,这有助于其处理数据的速度极快。
在写入方面,Kafka 受益于其仅追加存储机制。消息被追加到分区的末尾,这种顺序写入操作效率很高。
磁盘 I/O 最小化,写入吞吐量最大化,使得 Kafka 能够以低延迟摄取大量数据。
在读取方面,Kafka 采用内存存储和高效的磁盘存储相结合的方式。频繁访问的数据保存在内存中,减少了磁盘读取的需求,显著提高了读取性能。
此外,Kafka 还采用批处理和压缩等技术来优化生产者和消费者之间的数据传输。
您可以进一步查看系统设计课程,例如DesignGuru.io 上的Grokking 系统设计面试,以更好地了解 Kafka 及其用法。
4.零拷贝技术
Kafka 利用零拷贝技术,这有助于实现高性能。零拷贝是指将数据从一个缓冲区传输到另一个缓冲区,而无需操作系统参与。
在传统系统中,数据通常在用户空间和内核空间之间复制多次,从而产生开销。
Kafka 使用零拷贝技术,消除了大部分此类开销。读取或写入数据时,Kafka 可以高效地在缓冲区之间移动数据,而无需进行不必要的复制。
这使得 CPU 利用率更低、数据传输更快,从而使 Kafka 非常适合高吞吐量场景。
5. 批处理和压缩
Kafka 采用批处理策略来优化消息处理。生产者无需单独发送每条消息,而是将消息分组到批次中,然后再发送给 Broker。
批处理减少了与网络通信相关的开销,因为与传输单个消息相比,传输一批消息所需的网络往返次数更少。
此外,Kafka 还采用了压缩算法来减少传输和存储过程中数据的大小。
通过在消息写入磁盘或通过网络传输之前对其进行压缩,Kafka 最大限度地减少了需要传输的数据量,从而提高了写入和读取性能。
总之,Kafka 的速度源于其分布式架构、有效的分区、对写入和读取操作的优化、零拷贝技术以及批处理和压缩的战略性使用。
这些因素共同使 Kafka 成为一个高性能数据流平台,能够满足现代实时数据处理的需求。
现在,您可以查看更多系统设计面试准备资源
系统设计面试资源:
此外,这里还精选了一些最佳系统设计书籍、在线课程和练习网站,您可以参考这些内容,更好地准备系统设计面试。这些课程中的大多数也解答了我在这里分享的问题。
-
DesignGuru 的 Grokking 系统设计课程:一个交互式学习平台,通过实践练习和真实场景来加强您的系统设计技能。
-
Alex Xu 撰写的《系统设计面试》:本书深入探讨了系统设计的概念、策略和面试准备技巧。
-
Martin Kleppmann 撰写的《设计数据密集型应用程序》:一本涵盖设计可扩展且可靠系统的原则和实践的综合指南。
-
LeetCode 系统设计标签:LeetCode 是一个流行的技术面试准备平台。LeetCode 上的系统设计标签包含各种练习题。
-
GitHub 上的“系统设计入门”:精选资源列表,包括文章、书籍和视频,可帮助您准备系统设计面试。
-
Educative 的系统设计课程:一个交互式学习平台,通过实践练习和真实场景来加强您的系统设计技能。
-
高可扩展性博客:一个以高流量网站和可扩展系统架构的文章和案例研究为特色的博客。
-
YouTube 频道:查看“Gaurav Sen”和“Tech Dummies”等频道,获取有关系统设计概念和面试准备的深刻视频。
-
ByteByteGo:Alex Xu 编写的一本用于系统设计面试准备的在线书籍和课程。它包含《系统设计面试》第一卷和第二卷的所有内容,并将于即将更新第三卷。
-
Exponent:一个专门为亚马逊和谷歌等 FAANG 公司提供面试准备的网站,他们还提供很棒的系统设计课程和许多其他材料,可以帮助您破解 FAAN 面试。
图片来源 - ByteByteGo
记住,要将理论知识与实际应用结合起来,参与实际项目和模拟面试。持续的练习和学习无疑会提升你在系统设计面试中的熟练程度。
如果你喜欢视频,ByteByteGo 也有一个关于同一主题的精彩视频。你可以观看它来进一步巩固你对 Apache Kafka 内部工作原理及其如何提升速度的学习。
学习愉快!!
文章来源:https://dev.to/somadevtoo/how-does-apache-kafka-work-why-is-kafka-so-fast-463i