AWS Lambda 剖析
AWS Lambda 是一项著名的服务,它普及了云计算中无服务器的理念。它并非同类服务中的第一个,也不会是最后一个,但毫无疑问,它曾经是、并且现在仍然是最受欢迎、使用最广泛的服务。在本文中,我们将深入剖析 AWS Lambda 函数的构成以及其背后的流程。
这篇文章很长,但希望您觉得有趣。如果您只想查看某个特定主题,请使用下面的目录。
什么是无服务器?
讨论 Lambda 时,不能不讨论无服务器架构,因为两者之间相互驱动。无服务器架构有很多定义,但简而言之:无服务器架构允许您完全专注于应用程序的业务逻辑。您无需考虑服务器、预置的基础设施、网络、虚拟机等。所有这些工作都由云提供商(例如 AWS,Lambda 就是其中之一)为您处理。通常,这意味着您的应用程序严重依赖于由云提供商维护的托管服务(例如 Lambda、DynamoDB 和 API 网关),这些服务允许您将服务器抽象出来。
无服务器服务通常具备以下能力:
- 无需服务器管理– 您无需配置或维护任何服务器。无需安装、维护或管理任何软件或运行时
- 灵活扩展——您可以自动扩展应用程序,或通过切换消耗单位(例如,吞吐量、内存)而不是单个服务器的单位来调整其容量
- 高可用性——无服务器应用程序具有内置的可用性和容错能力。您无需为这些功能进行架构设计,因为运行应用程序的服务默认提供了这些功能。
- 无闲置容量– 您无需为闲置容量付费。无需为计算和存储等资源预先配置或过度配置容量。代码未运行时无需付费。
AWS 为我们提供了许多无服务器服务:DynamoDB、SNS、S3、API Gateway,以及相当新颖且极具吸引力的 AWS Fargate。但这次我们将只关注 AWS Lambda,它是无服务器革命的核心服务。
Lambda——没有服务器,只有代码
Lambda 可以描述为函数即服务 (FaaS),其中函数是主要的构建块和执行单元。无需管理服务器,无需虚拟机、集群或容器,只需使用受支持的语言之一创建函数即可。与任何其他托管服务一样,AWS 自动处理配置、扩展和可靠性。这使我们能够在非常高的抽象级别上工作,完全专注于业务逻辑,而(几乎)无需考虑底层资源。

基本 Lambda 示例
让我们看一个简单的 lambda 示例。
exports.handler = async function(event, context) {
console.log('Hello Lambda!');
}
您可以看到,我们定义了所谓的handler,即每次事件发生时 Lambda 服务都会执行的函数。Handler 接受两个参数: anEvent object和 a Context。稍后我们将仔细研究它们。
你可能已经注意到,我们将处理程序定义为一个async函数,这允许我们在 Lambda 内部执行异步操作handler。通过在处理程序调用后返回一个 Promise,我们不仅能够返回异步操作的结果,还能确保 Lambda 会“等待”所有已启动的操作完成。
您根本不必使用asyn/await语法或承诺,如果您更喜欢“老式”回调方法,则可以使用第三个处理程序参数:
exports.handler = function(event, context, callback) {
/// ... async operations here
callback(asyncOperationResult);
}
Lambda 是一种事件驱动服务,每次 lambda 执行都由某个事件触发,通常由另一个 AWS 服务创建。
兼容事件源的一个示例是API Gateway,它可以在每次收到请求时调用 Lambda 函数。另一个示例是Amazon SNS,它可以在每次向 SNS 主题发布新消息时调用 Lambda 函数。有许多事件源可以触发您的 Lambda,请务必查看 AWS 文档以获取完整的列表。
事件与背景
每个 Lambda 函数都会接收两个参数:Event和Context。而 Event 则为函数提供了触发执行的事件的详细信息(例如,来自 API Gateway 的事件可用于检索请求详细信息,如查询参数、标头甚至请求正文)。
exports.handler = async function(event, context) {
console.log('Requested path ', event.path);
console.log('HashMap with request headers ', event.headers);
}
另一方面,上下文包含提供有关调用、函数和执行环境(例如分配的内存限制或即将到来的执行超时)的信息的方法和属性。
exports.handler = async function(event, context) {
console.log('Remaining time: ', context.getRemainingTimeInMillis());
console.log('Function name: ', context.functionName);
}
Lambda 执行细节
您可能已经注意到,我们的 lambda 代码可以分为两部分:处理程序函数内部的代码和处理程序外部的代码。
// "Outside" of handler
const randomValue = Math.random();
exports.handler = function (event, context) {
// inside handler
console.log(`Random value is ${randomValue}`);
}
// this is still outside
虽然这仍然是典型的 JavaScript 文件,但这两部分代码的调用方式有所不同,具体取决于 Lambda 函数的用法。在深入探讨这个主题之前,我们必须先了解 Lambda 函数的一个关键概念:冷启动和热启动。
为了理解冷启动和热启动背后的含义,我们必须了解我们的功能即服务是如何工作的。
冷启动
在空闲状态下,即没有触发任何事件且没有执行任何代码时,您的 Lambda 函数代码将以 zip 文件(即 Lambda 代码包)的形式存储在 S3 存储桶中。对于 JavaScript,此 zip 文件通常包含一个 js 文件,其中包含您的函数代码以及其他所需文件。
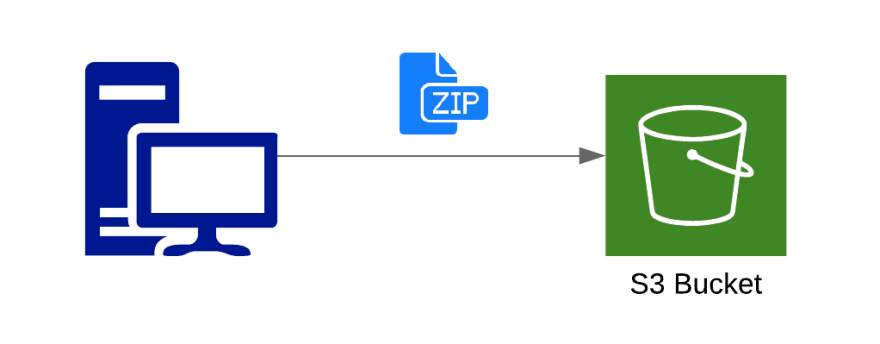
一旦事件发生,Lambda 必须下载您的代码并设置运行时环境,以及 Lambda 配置中指定的资源。只有完成此步骤后,您的 Lambda 代码才能执行。
这个过程就是所谓的 Lambda 函数冷启动,它发生在你的 Lambda 第一次执行时,或者闲置了较长时间的时候。
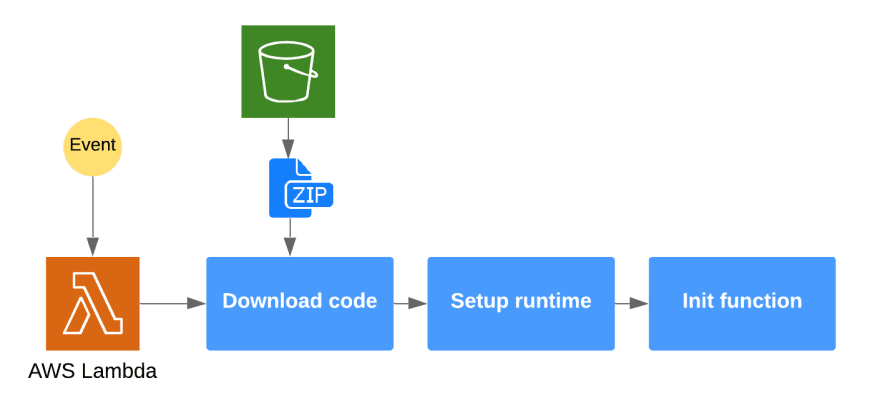
只有在初始设置完成后,才可以执行处理程序,并将触发事件作为参数传递。
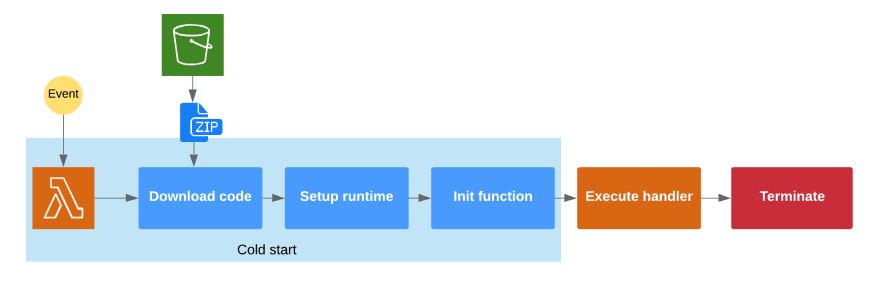
冷启动的具体时长取决于您的代码包大小和 Lambda 函数的设置(在私有 VPC 内创建的函数通常冷启动时间更长)。如果长时间冷启动会影响您服务的用户,您应该注意这一点。因此,明智的做法是尽可能减小代码包大小(注意 node_modules 的大小!),并选择能够提供更快冷启动速度的运行时。
好的,那么热启动怎么样?
热启动
上述运行时不会在处理程序执行后立即终止。在一段时间内,运行时仍保持活动状态并可以接收新事件。如果发生此类事件,暖运行时无需再次初始化,它可以立即执行处理程序。

热执行当然比冷执行快得多。然而,问题在于我们无法假设函数在冷启动或热启动时会被调用或不会被调用。函数保持热启动的时间在文档中并没有精确定义,实际上取决于您的配置和实际的 Lambda 使用情况。此外,如果您允许 Lambda 并发,新创建的 Lambda 实例也会以冷启动的方式启动。
这意味着您必须注意上述过程,并尝试同时优化冷启动和热启动。
初始化与处理程序
这对我们的代码有什么影响?还记得我们之前提到的处理函数的例子吗?
// "Outside" of handler
const randomValue = Math.random();
exports.handler = function (event, context) {
// inside handler
console.log(`Random value is ${randomValue}`);
}
// this is still outside
处理函数之外的代码仅在冷启动期间执行。另一方面,处理函数则会在每个事件发生时执行。
// This will be executed only during cold start
const randomValue = Math.random();
exports.handler = function (event, context) {
// Handler will be executed for every request
// So, what will be displayed here?
console.log(`Random value is ${randomValue}`);
}
Handler 仍然可以使用初始化期间创建的所有变量,因为这些变量存储在内存中(直到运行时终止)。这意味着,在上面的代码片段中,randomValue每次调用 Handler 时,这些变量都是相同的。虽然这可能不是我们想要实现的,但使用冷启动/热启动阶段,我们可以在代码中应用一些优化。
通常,建议将所有初始化代码放在处理函数之外。所有初始化操作(例如创建数据库连接)都应该在处理函数之外完成,并且只在处理函数内部使用。
const config = SomeConfigService.loadAndParseConfig();
const db = SomeDBService.connectToDB(config.dbName);
exports.handler = async (event, context) => {
const results = await db.loadDataFromTable(config.tableName);
return results;
}
这样,我们不仅可以大大提高处理程序的执行时间,而且还可以确保不会因为每次 lambda 调用都创建新的连接而对数据库造成影响。
我们可以对 lambda 函数应用许多高级优化技术。不过,了解冷启动和热启动,并基于这些过程进行代码优化是一种简单且非常有效的方法,您应该默认将其应用于所有 lambda 函数。
并发
即使是最优化的服务也需要扩展,才能处理繁重的工作负载。在“经典”应用程序中,这由自动扩展组处理,该组负责跟踪服务器利用率,并在需要时适当地配置额外的服务器(或终止未使用的服务器)。但是,在使用 Lambda 时,我们不需要服务器,那么我们如何扩展我们的函数呢?
Lambda 中的扩展逻辑
正如我们所料,Lambda 函数的自动扩展由 Lambda 服务自动处理。
默认情况下,Lambda 会尝试通过重用现有的热运行时来处理传入的调用请求。如果函数执行时间短于即将到来的请求之间的时间间隔,则此方法有效。
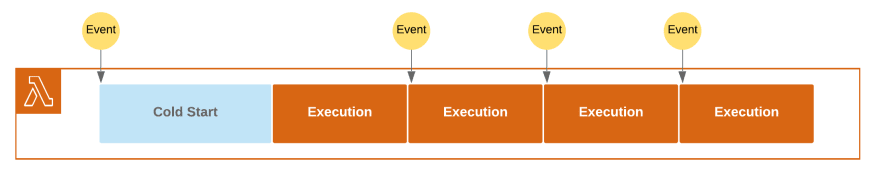
无论从我们的角度来看(热运行时意味着更快的执行时间和重用资源和连接的能力),还是对于 AWS 而言(服务不必提供额外的运行时),这都是一种非常合理的方法。
但是,如果事件之间的时间间隔短于函数执行时间,单个函数实例将无法处理这些调用请求。在这种情况下,为了处理工作负载,Lambda 必须进行扩展。

如果当前所有运行时都处于繁忙状态,Lambda 会收到新的调用请求,并创建另一个运行时。这个新的运行时将处理即将到来的调用请求并执行函数代码。之后,运行时会保持一段时间的“热”状态,并可以接收新的请求。如果该运行时长时间处于空闲状态,Lambda 会终止它以释放资源。
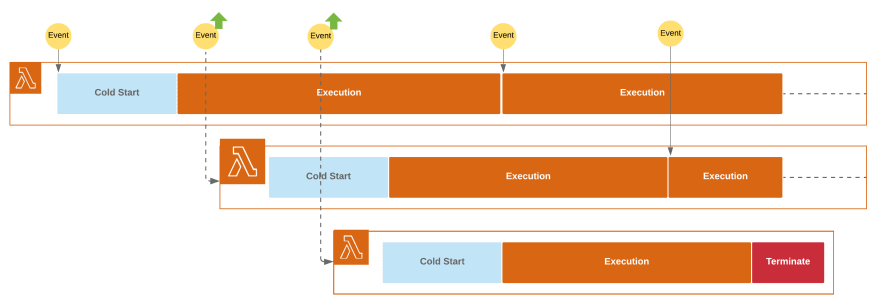
并发限制
每个 Lambda 函数都应用了并发限制,它指定了同时创建的运行时的最大数量。如果您的函数开始超出此限制,则即将到来的调用请求将受到限制。在大多数情况下,触发 Lambda 的 AWS 服务能够检测到这种情况,并在一段时间后重试请求。
那么,既然我们可以修改 Lambda 的并发限制,那么我们是否有理由设置较低的并发限制?
是的,这实际上是一个相当棘手的用例。请记住,每个 Lambda 运行时都是独立的,这意味着资源不会在它们之间共享。如果您的 Lambda 连接到某个数据库,则每个运行时都必须创建一个独立的数据库连接。
如果并发限制过高,情况会非常危险,因为你的数据库可能在很短的时间内被 1000 个连接轻易地攻击。在这种情况下,最好设置较低的并发限制(或者干脆将数据库更改为能够处理这种负载的数据库)。
现在,让我们更详细地了解不同的 Lambda 调用方法。
调用方法
推与拉
Lambda 可以通过两种不同的方式调用:
- 推送调用模型- 当 AWS 服务中发生指定事件时,Lambda 函数会被执行。这些事件可能是新的 SNS 通知、添加到 S3 bucket 的新对象,或者 API 网关请求。
- 拉取调用模型- Lambda 定期拉取数据源(可能是 SQS 队列,即所谓的事件源映射),并调用 lambda 函数,将拉取的一批记录传递到事件对象中
上述调用模型对函数代码的影响不大,但在计算 Lambda 成本或构建数据流时,您应该注意这一点。尤其是第二种模型,即拉取调用,可能会造成一些混淆。您可能希望在新消息发布到 SQS 时立即调用 Lambda,但实际上,SQS 会定期拉取消息,您的函数将收到一整批最近添加的消息。
同步与异步
此外,可以使用两种不同的调用类型来调用该函数:
- RequestResponse - 函数以同步方式调用,调用者等待函数完成并返回结果。例如,APi Gateway 就使用这种调用方式,它允许它从 Lambda 中检索请求响应对象。

- 事件- 函数被异步调用,调用者无需等待函数返回值。事件被推送到执行队列,等待函数执行。如果函数返回错误,此调用类型可以自动重试执行。

在现实世界中,调用类型通常由创建事件并调用 lambda 函数的服务定义。
角色和权限
Lambda 的最大优势之一是它与 AWS IAM 集成——AWS IAM 是一项负责管理 AWS 资源权限的服务。与所有与 IAM 相关的功能一样,AWS Lambda 的详细权限管理是一个相当复杂的过程,但在大多数情况下,它围绕执行角色进行解决。
执行角色
执行角色是你的 lambda 函数在执行时承担的角色。但它究竟意味着什么呢?
IAM 角色是权限的集合,例如,您可以拥有一个角色,该角色被允许读取数据并将其保存到某个特定的 DynamoDB 实例。当您将此角色分配给 Lambda 函数时,该函数在调用时将承担此角色。因此,在执行过程中,Lambda 将使用角色中定义的一组权限运行。
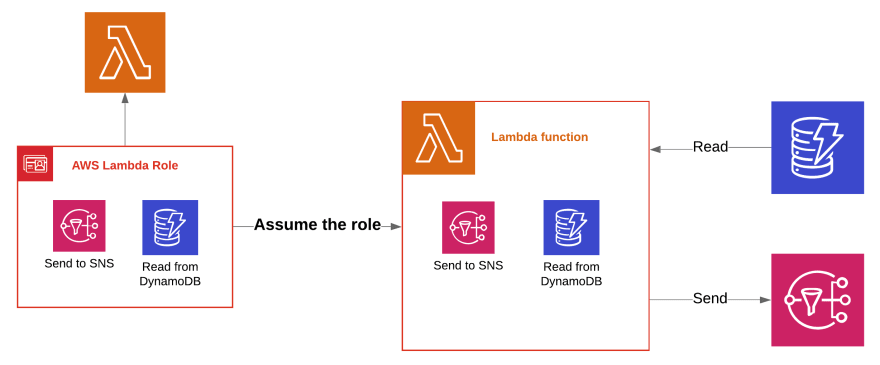
一个角色可以分配给多个 Lambda,如果它们需要相同的权限集,这很方便。但请记住,您应该始终只授予 Lambda 正常运行所需的最小权限集,因此,让一个角色拥有所有 Lambda 共享的所有权限并不是一个好主意。
至少,您的函数需要访问 Amazon CloudWatch Logs 以进行日志流式传输,但是,如果您的函数使用拉取调用模型,则它需要额外的权限来读取数据源(例如,从 SQS 队列读取消息)。
简单角色的示例
假设我们要创建一个 Lambda 函数,该函数读取 SQS 队列,处理数据并将结果保存到 DynamoDB 表中。该函数的执行角色应该如何定义?
首先,该服务需要有权限将日志发送到 CloudWatch,这使我们能够在需要时监控和调试我们的应用程序。

由于它将数据写入 DynamoDB,因此我们还必须添加适当的写入权限
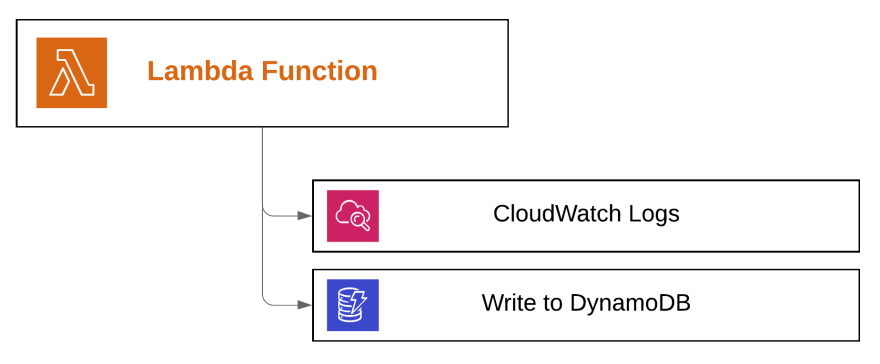
我们也应该添加读取权限吗?假设我们的 lambda 只将数据写入数据库,那么不需要。这就是“最低要求权限”规则,如果不是绝对需要该权限,就不要使用它。
最后一步,我们必须添加一个权限,允许我们的 Lambda 读取 SQS 队列。如上所述,Lambda 需要能够读取等待的消息,以便在执行期间将这些消息提供给我们的 Lambda 函数。
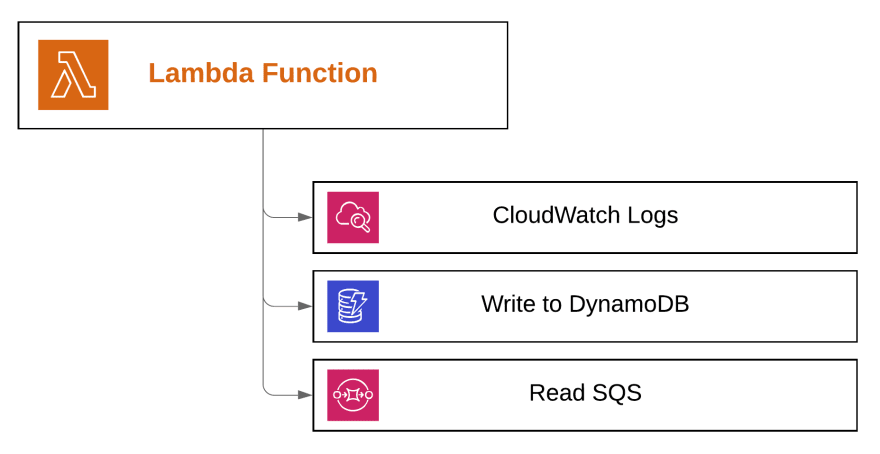
这组权限将使我们的 Lambda 能够成功执行其设计的任务……仅此而已。这正是我们想要实现的。
引擎盖下有什么?
Lambda 为我们提供了一系列令人惊叹的功能,这项服务最大的优势在于我们无需考虑服务器以及所有支持它的底层技术。但我们都是好奇心很强的生物,对吧?那么,当我们的函数执行时,幕后究竟发生了什么呢?
Lambda 技术的细节需要一篇单独的文章(或一本书……),但总的来说,我们至少可以尝试在这里触及表面。
Lambda 调用流程
Lambda 服务实际上是一整套相互协作以提供全方位 Lambda 功能的服务。
- 负载均衡器负责将调用请求分发到不同可用区中的多个前端调用器。它还能够检测特定可用区中的问题,并将请求路由到剩余可用区
- Frontend Invoker是一种接收调用请求、验证请求并将其传递给 Worker Manager 的服务
- Worker Manager是一种管理 Workers 的服务,它跟踪 Workers 中资源和沙箱的使用情况,并将请求分配给合适的 Workers
- Worker为客户代码执行提供安全的环境,此服务负责下载您的代码包并在创建的沙箱中运行它。
- 此外,还有一个计数器服务,负责跟踪和管理并发限制,以及一个放置服务,用于管理工作者的沙箱,以最大限度地提高打包密度。
总结一下,调用请求由负载均衡器 (Load Balancer)传递给选定的前端调用器 (Frontend Invoker)。前端调用器 (Frontend Invoker) 检查请求,并向工作器管理器 (Worker Manager) 请求一个沙盒函数来处理调用。工作器管理器 (Worker Manager)要么找到合适的工作器 (Worker)和沙盒,要么创建一个沙盒。沙盒准备就绪后,代码将由工作器 (Worker)执行。

隔离
Worker 通常是在云中运行的某个 EC2 实例。同一个 Worker 实例上可以运行来自不同用户的多个不同函数。为了保证安全性和隔离性,每个函数都运行在一个安全的沙盒中。单个沙盒可以重复用于同一函数的另一次调用(暖运行时!),但它永远不会在不同的 Lambda 函数之间共享。

驱动这一流程的技术是Firecracker。它是一个开源(链接)项目,允许 AWS 在单个 Worker 上跨越数百甚至数千个轻量级沙箱。
由于可以轻松快速地创建和终止沙箱,同时仍然提供功能的安全隔离,因此可以在多个 Lambda 甚至帐户之间重复使用 Workers,这使得Placement Service可以组织工作以创建和应用尽可能性能最高的使用模式。
以上是对 Lambda 内部的一个非常简短和简化的概述,如果你想了解更多有趣的细节,请查看re:Invent 上的这个演讲
结论
感谢您读完这篇文章。文章已经很长了 :) 不过,希望这篇文章能让您对 Lambda 的概念以及如何使用它有一个有趣的了解。如果您有兴趣了解更多详情,请联系我!
查看sosnowski.dev了解更多文章!
文章来源:https://dev.to/sosnowski/anatomy-of-aws-lambda-1i1e