对编译和解释的深入考察

或许没有什么比看到拼图碎片拼凑在一起更令人满足的了。对于真正的拼图来说,情况就是这样。我不太擅长拼拼图,因为我总是把碎片丢在沙发底下。对于一些比喻性的拼图,我通常更擅长,因为这类拼图不会在陌生的地方丢失碎片。
学习之谜无疑是最复杂的谜题之一。学习新事物之所以困难,是因为你需要不断地拼凑想法、构建概念,却并不一定知道这些部分是如何融入整体的。当你不断地思考新事物与你早已熟悉的整体图景有何关联时,你很难理解它。这有点像你随机找到一块拼图,然后试图找到与之相配的其他碎片,却不一定知道这些碎片是如何融入整体的。
学习特定主题(例如计算机科学)也是如此。很多时候,你会感觉自己只是掌握了一点点信息——这里一个数据结构,那里一个算法——却并不总是知道各个部分是如何联系在一起的。我倾向于认为这就是学习计算机科学如此困难的原因:没有太多资源能够将这些知识完美地串联起来,构建出一个完整的领域图景。
然而,偶尔,如果你真的坚持一个主题足够长的时间,你会发现一些碎片会逐渐拼凑起来。随着我们一起完成这个系列,是时候让这一切最终实现了!
我们熟悉和喜爱的翻译
大约一年前,我们刚开始撰写这个系列文章时,探索的第一个主题是通常被认为是计算机科学“基石”的东西:二进制。我们了解到,二进制的核心是每台计算机都能使用和理解的语言。归根结底,我们的机器都是基于 1 和 0 运行的。
从那时起,我们探索了各种数据结构,例如树、图和链表,以及排序算法、遍历或搜索算法。现在是时候将它们最终整合在一起了——或者更确切地说,将它们全部回归到二进制。

我们已经在计算和计算机科学的核心概念方面走遍了世界。但有一个问题我们至今仍未真正解答,尽管我们可能已经思考了整整一年:我们究竟如何从代码中转化为计算机的“1”和“0”?
在我们深入探讨我们编写的代码如何转换成二进制之前,让我们先澄清一下我们在这里使用“二进制”一词的真正含义。计算机读取和理解的“二进制”代码通常被称为机器语言或机器代码,它是一组发送给机器并由其中央处理器(或CPU)运行的指令。
需要注意的是,机器码有很多种,有些实际上是 0 和 1,有些则是十进制或十六进制(我们已经很了解了!)。无论机器语言的具体格式是什么,它都必须相当简陋,因为它需要被计算机理解。这就是为什么机器语言被称为低级语言,因为它们需要足够简化才能被我们机器的 CPU 处理,而我们都知道,CPU 内部只是一堆开关而已。
我们可以将低级语言视为我们计算机的“母语”;机器代码应该可以被我们的机器直接读取,而不需要由它们翻译。
但是,我们如何将我们的代码转换为机器友好的版本(机器码)呢?嗯,我们程序员编写的代码和计算机处理器读取的机器码只不过是两种不同类型的语言。仔细想想,我们真正需要做的就是在这两种语言之间进行翻译。
现在又有一个问题:我们不知道如何在我们的代码和机器码之间进行转换!好吧,开个玩笑——这其实不是什么问题。因为我们有两个好心的朋友可以帮我们。
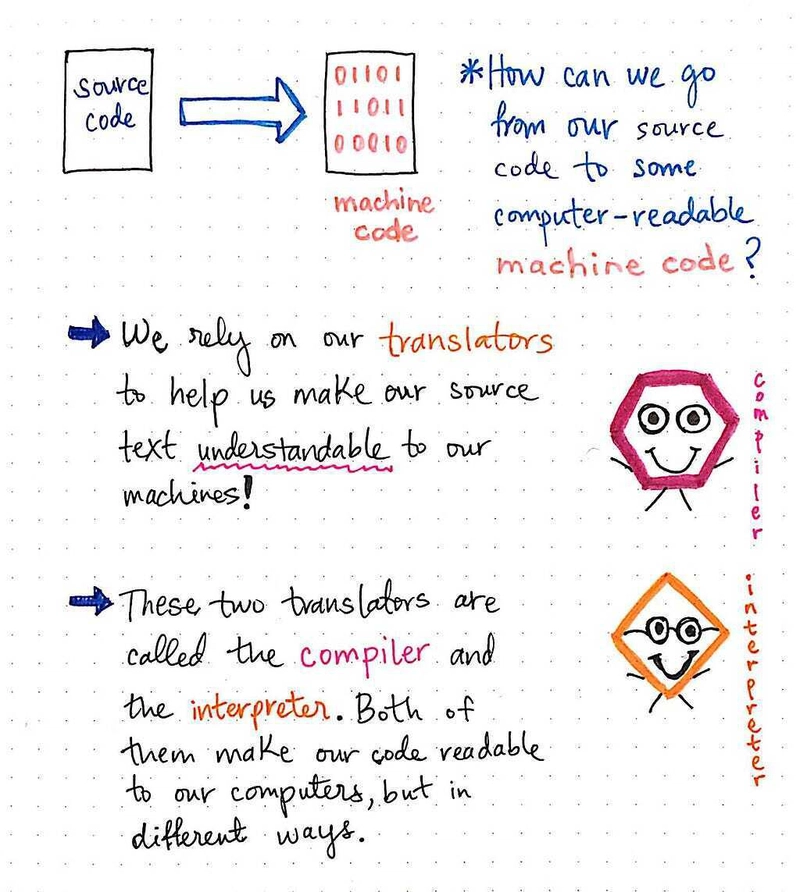
为了将源代码转换为二进制格式的计算机可读机器代码,我们需要依靠翻译器来帮助我们使机器能够理解源文本。
翻译器,有时也称为编程语言处理器,只不过是一个将源语言翻译成目标语言的程序,同时保持其所翻译代码的逻辑结构。
我们已经对一种翻译器有了些许了解,尽管我们可能还不完全了解它。在本系列的前文中,我们探讨了编译器的词法和语法分析阶段(前端),以及该过程中涉及的不同数据结构。
原来,编译器也是一种翻译器!还有另一种翻译器,它的名字经常和编译器联系在一起,叫做解释器。编译器和解释器都让我们的代码可以被计算机读取,但实现方式却截然不同。
但是让我们首先从我们已经知道的开始:编译器。

编译器只不过是一个程序,它接受高级语言(我们编写代码的语言)并将其转换为机器码。编译器内部包含许多组件(或者更确切地说,是内部组件),可能包括扫描器、词法分析器/标记器和解析器。但归根结底,即使它很复杂,它也只是一个将我们的代码转换为机器可读代码的程序。
然而,尽管我们这样说的话它的工作可能看起来很简单,但编译器执行这一重要任务的方式还是值得强调的。

大多数情况下,编译器会一次性将我们的代码翻译成机器码。换句话说,编译器会在源代码被执行或运行之前翻译程序员的所有源代码。它会将我们的源代码转换成一个用机器码编写的文件。正是这个机器码文件(称为可执行文件,通常以 .exe 为扩展名)允许我们运行我们编写的原始代码。
编译器最重要的特性在于,它能够一次性将源文本翻译成机器码二进制文件。编译器将翻译和编译后的文件返回给程序员,程序员可以通过输出的可执行文件运行他们的代码。
编译器返回的可执行文件一旦翻译完成就可以反复运行;编译器不需要在任何后续重新运行中存在!
一旦编译器将所有源代码翻译成机器码,编译器的工作就完成了。程序员可以根据需要多次运行编译后的代码,并使用他们想要的输入。他们还可以与他人共享编译后的代码,而无需共享原始源代码。

这种特定翻译器背后的概念——以及“编译器”一词本身——是由杰出的格蕾丝·霍珀 (Grace Hopper)于 1952 年在最有趣的情况下创造的。
当时,霍珀在埃克特-莫奇利计算机公司工作,作为团队中的数学家,参与开发 UNIVAC I 计算机。实际上,她致力于将数学代码转化为自己的语言(A-0 系统语言)。
然而,她有更大的想法。她想编写一种全新的编程语言,用英语而不是有限的数学符号来表达。然而,当她与同事分享这个想法时,他们却拒绝了她,并告诉她,她的想法不可能实现,因为“计算机不懂英语”。但她并没有因此却步。
在这个团队工作了三年之后,霍珀终于开发出了她的第一个可以运行的编译器。但当时没有人相信她真的做到了!在她的传记《格蕾丝·霍珀:海军上将和计算机先驱》中,她解释道:
我有一个正在运行的编译器,但没人愿意碰它。……他们小心翼翼地告诉我,计算机只能做算术运算,不能编写程序。
幸好格蕾丝·霍珀没有听信那些不信者,因为她最终继续了自己的工作,并开发出了最早的高级编程语言之一——COBOL。她还获得了总统自由勋章,以及许多其他成就。
事实上,如果她听信了所有这些人的意见,她很可能永远不会凭借早期构建和设计第一个编译器的工作,将计算提升到一个全新的高度。格蕾丝·霍珀在第一个编译器上的工作,为几年后出现的另一个翻译器——解释器——奠定了基础。
逐步翻译
1958年,格蕾丝·霍珀(Grace Hopper)完成编译器几年后,麻省理工学院(MIT)的一些学生在实验室里,使用一台IBM 704计算机。这台计算机是四年前才推出的一项相当新的技术。其中一位名叫史蒂夫·拉塞尔(Steve Russell)的学生,正与他的教授约翰·麦卡锡(John McCarthy)合作开展一个名为“麻省理工学院人工智能项目”的项目。
当时,拉塞尔正在研究 Lisp 编程语言,并读到了教授撰写的一篇关于该主题的论文。他萌生了将 Lisp 中的 eval 函数转换为机器码的想法,这让他走上了创建第一个 Lisp 解释器的道路。该解释器用于计算 Lisp 语言中的表达式——相当于在当时用 Lisp 运行一个程序。

事实上,Hopper 的工作直接影响了 Russell 的发明。Lisp 解释器的第一个版本是手工编译的。在 2008 年接受计算机历史博物馆采访时,Russell解释了编译器如何影响他在麻省理工学院的工作:
我记得有一天,大概是九月底或十月左右,约翰 [麦卡锡] 带着通用的 M 表达式来了,那是用 M 表达式写出来的 Lisp 解释器,我们看了看,说:“哦,是的,那可以行。”我看了看,说:“哦,那只是需要再多做些手动编译,就像我一直在做的那样。我能做到。”>……我在圣诞节前得到了一些可以运行的东西,它是一个可用的解释器;没有垃圾收集器,但还没有任何大型程序。
Russell 和他的同事们继续手工编译了Lisp 解释器的最初两个版本。如今,大多数程序员甚至做梦都不会想到要手工编译他们的任何代码!事实上,我们中的许多人在应用程序开发中都会多次与解释器交互——只是我们可能并不总是意识到它的存在。
那么,解释器到底是什么?是时候给出正式的定义了!

解释器也是一种翻译器,就像编译器一样,它将高级语言(我们的源文本)转换成机器码。然而,它做的事情略有不同:它实际上在翻译过程中立即(内联)运行并执行它翻译的代码。
我们可以将解释器视为“家族”中更“有条理”的翻译器。它的工作方式比一次性将代码翻译成机器语言更加系统化。
翻译器的工作是逐段进行的。它每次会翻译一部分原文,而不是一次性翻译所有内容。
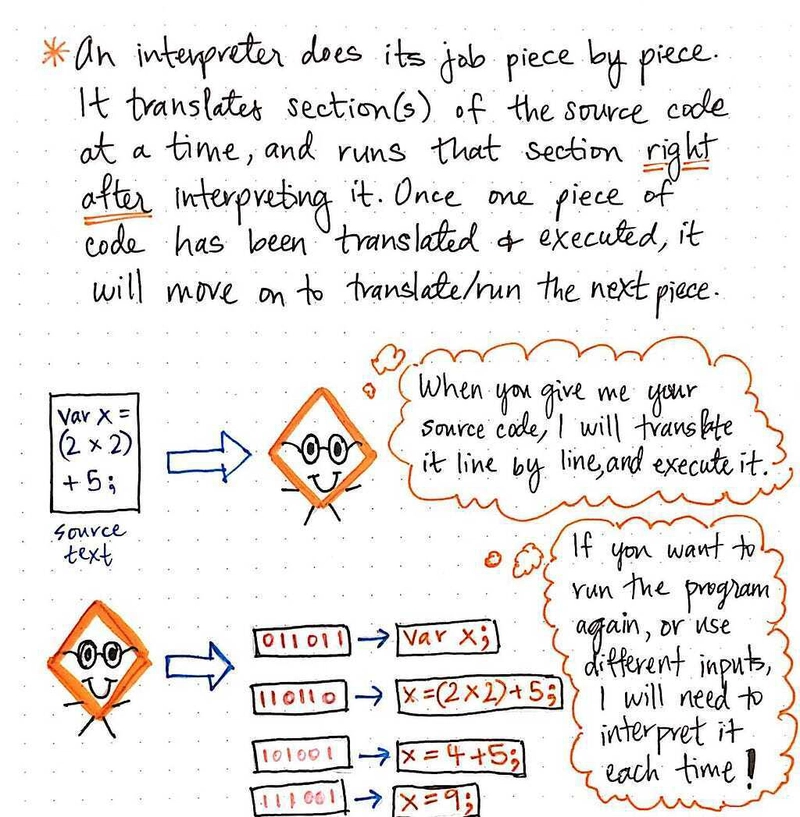
与编译器不同,它不会翻译所有内容,然后将文件交给我们程序员执行。相反,解释器每次只会翻译一行/一段代码。翻译完一行后,它会获取该行代码的机器码版本,并立即运行。
另一种思考方式是,一段代码只有在解释器翻译之后才能运行。乍一看,这似乎相当直观,因为解释器怎么可能在不知道一行代码的二进制/机器码含义的情况下运行它呢?但是,如果我们更深入地思考,就会发现还有其他含义。只有解释器成功运行完一行代码后,它才会真正转到下一行。我们可以想象,这可能是好事,也可能不是,这取决于我们想要做什么。
例如,假设我们要用 10 个不同的输入来运行程序。我们的解释器必须针对每个输入逐行解释运行程序 10 次。但是,如果我们的代码中出现了致命错误,解释器可以在错误发生的瞬间就发现它,因为它实际上只是在翻译完错误代码后尝试运行它而已!
现在,我们或许能够开始理解解释器和编译器各自的优缺点。在本系列文章中,我们已经多次介绍了不同工具的优缺点,这或许是计算机科学领域的一个标志性特征。接下来,让我们来探讨一下解释器和编译作为翻译技术之间的根本区别。
两位翻译,同样尊贵
解释型、编译型以及它们各自的翻译器之间的差异,在很大程度上揭示了这两个程序的实现方式。如果我们比较这两种方法,就会发现它们虽然完成了相同的任务,但本质上却截然不同。
下图更明显地说明了这一点。
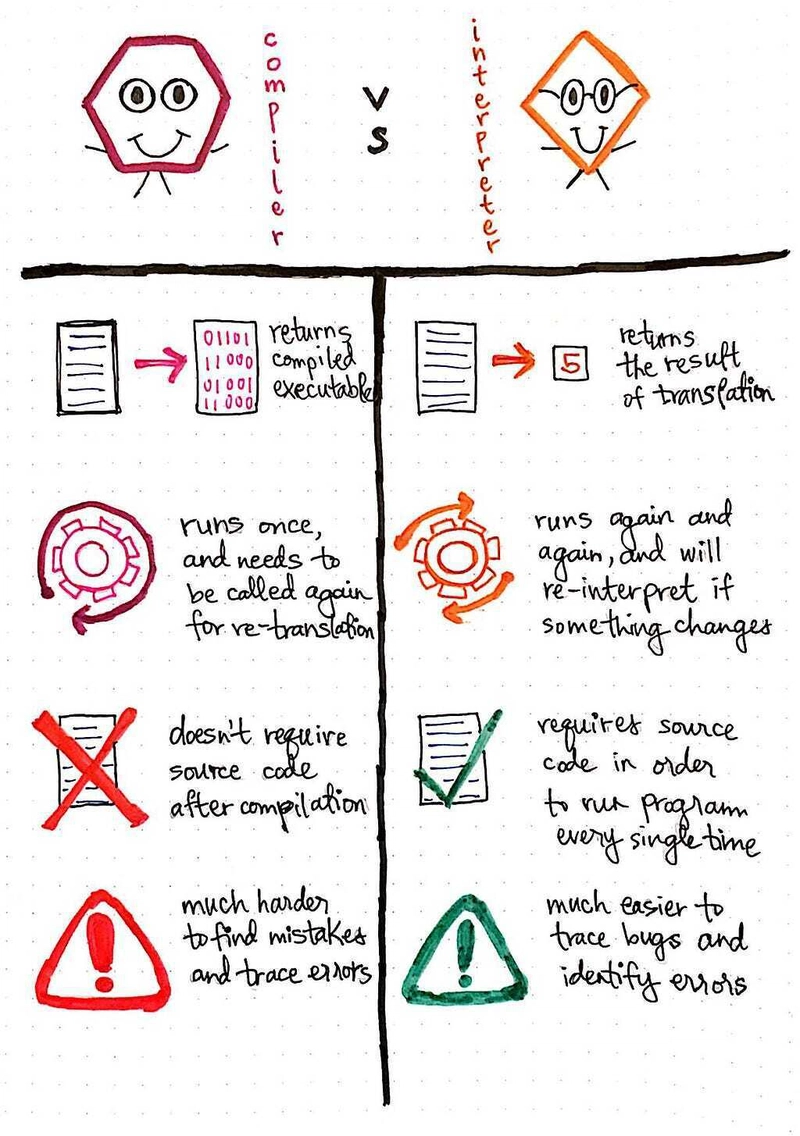
- 返回结果。编译器会获取一些源代码并返回已编译的可执行文件,而解释器实际上会翻译并执行源代码本身,并直接返回翻译结果。
- 运行频率。编译器只会运行一次,如果源代码发生变化,则需要再次调用编译器重新翻译。而解释器则会在源代码发生变化时再次运行并重新解释;解释器会“持续运行”并持续进行翻译。
- 灵活性。编译器一次性翻译源代码,这意味着编译后无需再次引用源代码。然而,解释器每次运行程序时都需要引用源代码来翻译和执行。
- 调试。编译器通常会使确定源代码中错误发生的位置变得更加困难,因为整个程序都已经被翻译过了,错误的位置在机器码中可能不容易识别。然而,使用解释器可以更容易地识别错误,因为它可以保存错误或缺陷的位置,并将该问题告知编写代码的程序员。
由于这些主要差异,编译代码(使用编译过程翻译并运行的代码)的运行速度往往比解释代码快一些。这是因为在代码执行之前,将源文本翻译成机器码的工作就已经完成了。

另一方面,解释代码更加灵活,因为解释器在翻译“过程”期间一直存在,以读取和处理我们的代码。
这里所说的灵活性意味着能够修改代码并立即运行。修改后无需重新编译;解释器会抓住机会重新解释代码,使其成为一种更具交互性的翻译形式。使用解释器可以更轻松地测试源文件中的细微(或重大)更改。

然而,在解释执行时,我们实际上需要源代码才能执行任何操作。虽然解释执行确实更容易测试更改和调试问题,但首先,源文本必须是可访问的。而编译执行则并非如此。一旦我们将代码编译成可执行文件,我们就再也不用担心源代码了——当然,除非我们需要重新编译。
这通常可以使编译器成为“更安全”的选择,因为我们的源代码没有暴露;相反,唯一的输出是可执行文件本身,它只是 1 和 0,并且不会向任何人展示我们是如何编写代码的或者它实际上说了什么,因为那时它都是机器语言。
编译和解释不仅扮演着我们作为软件开发者的角色,也扮演着我们作为软件消费者的角色。
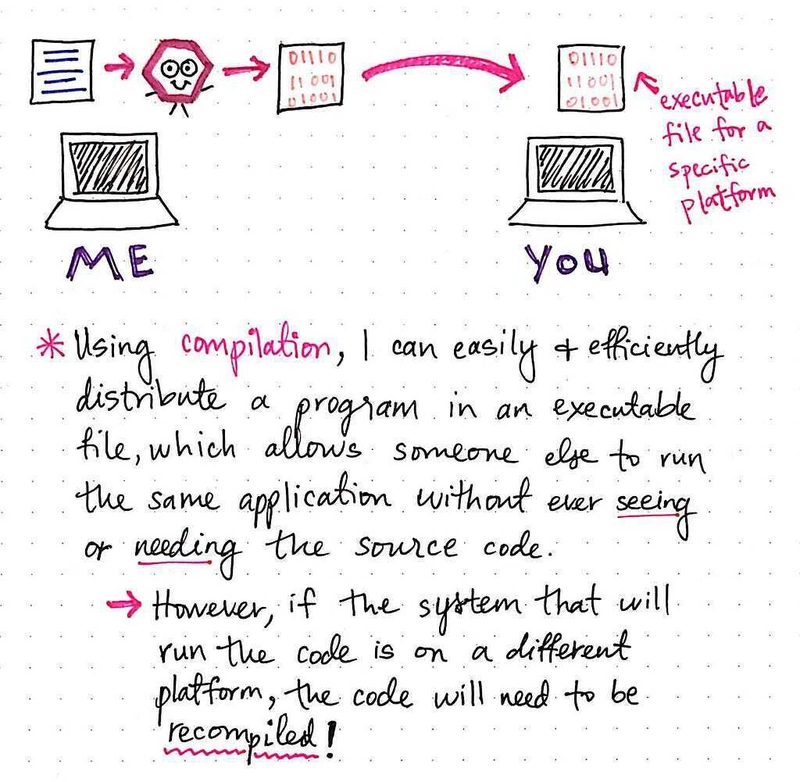
例如,每当我们下载文件或从 .exe 文件运行程序时,我们都依赖某些软件的创建者为我们编译可执行文件。
使用编译,我们可以轻松地将程序以可执行文件的形式分发。这将允许其他人运行与我们完全相同的代码,而无需实际向他们展示或提供我们的代码本身。编译文件的使用者无需查看源文本,因为他们只需获得一个可执行文件,即可在自己的本地机器上运行。
然而,分发已编译文件的问题在于,如何创建兼容不同平台(例如 Windows 操作系统与 OS X)的文件。作为程序员,我们的工作是确保编译后的可执行文件能够在各种平台上成功运行,有时,这意味着需要重新编译代码!
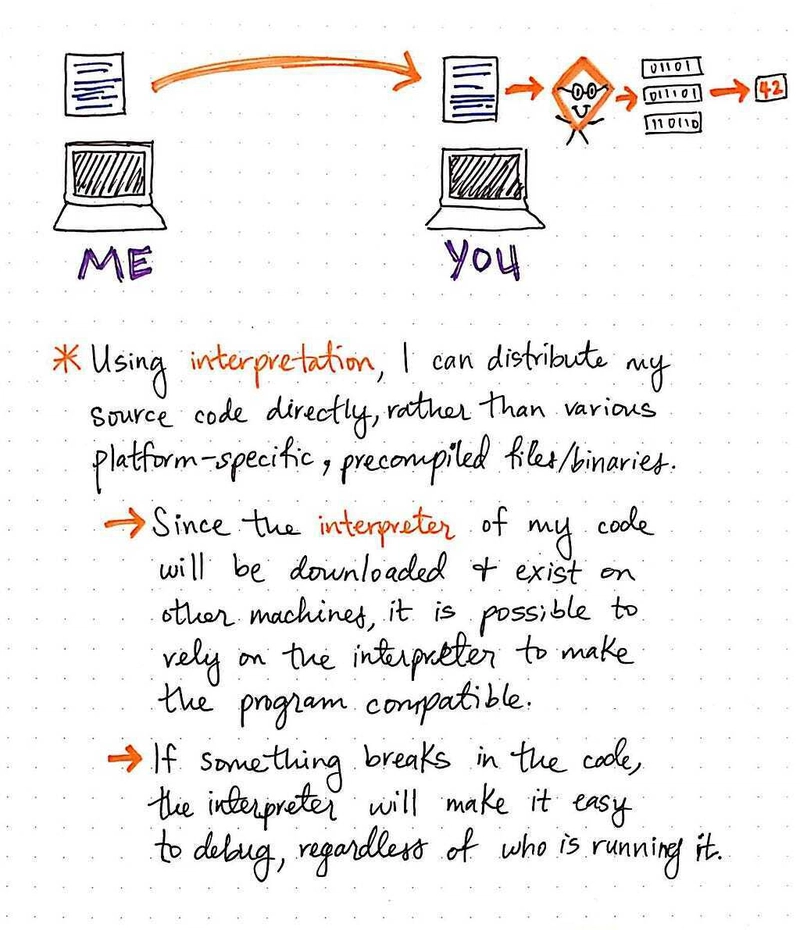
另一方面,当我们使用解释时,我们可以直接分发我们的源代码,而不必担心特定于平台的可执行文件,或者考虑如何编译二进制文件供大家使用。
然而,在这种情况下,我们需要程序的使用者下载一个解释器(通常它实际上会随语言一起提供),并确保该解释器存在于他们的机器上。一旦他们有了解释器,他们就可以看到我们的原始源代码,获取该代码,然后依靠他们自己版本的解释器在本地运行它。
在这种情况下,我们依靠解释器来实现所有平台的兼容,而我们作为程序员和用户,无需考虑这个问题。此外,如果出现问题(无论是我们编写的源代码本身的问题,还是与他们自己的平台相关的问题),我们代码的使用者可以比编译文件更容易地找出问题所在。无论谁在运行我们的代码,解释器都能让调试任何问题变得轻松。
但是,无论我们选择编译型还是解释型,最终目标都是一样的:用一种计算机能理解的语言来表达!事实证明,归根结底,一切都只是二进制而已。
资源
由于解释器和编译器都已存在多年,因此关于这两种类型的翻译器,市面上有大量的资源。从实现的角度来看,编写编译器和解释器的方法有很多种。但是,如果您只是想了解更多信息或进行更深入的挖掘,这些资源是一个不错的起点。
- 解释器和编译器(Bits and Bytes,第 6 集),Bits and Bytes TVO
- 编译器和解释器之间的区别,Gabriele Tomassetti
- 编译 vs 解释,BogeysDevTips
- 使用解释器和编译器的机器代码和高级语言,班科里学院计算机科学
- 《编程过程》,Vern Takebayashi 教授
- 为什么第一个编译器比第一个解释器先被编写?,StackOverflow
鏂囩珷鏉ユ簮锛�https://dev.to/vaidehijoshi/a-deeper-inspection-into-compilation-and-interpretation-8bp