每个网站都应该有一名 Service Worker
作者:丹尼·莫尔克克✏️
为什么每个网站都应该离线运行以及这真正意味着什么
您的网站可以离线运行吗?
如果没有,那就应该。正如每个网站都应该响应式,并且能够在桌面和移动设备上运行一样,网站无法离线运行也没有任何借口了。
除了 IE 之外,现在你可以让网站在所有浏览器中离线运行。最棒的是,你可以逐步增强你的网站,这样即使有人使用非常老旧的浏览器访问,它仍然能够完美运行。只是在这种情况下,它无法离线运行。
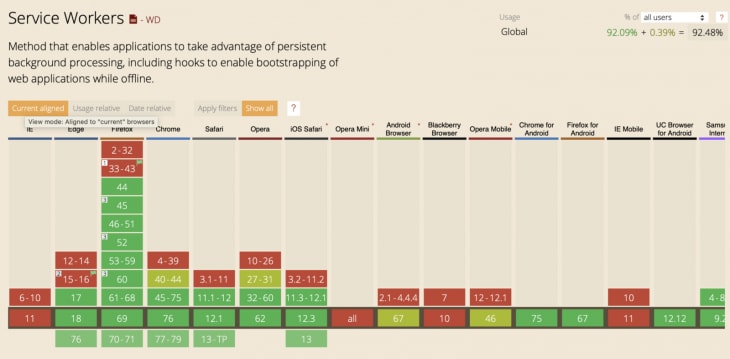
“离线”的真正含义
那么,如何让你的网站离线运行呢?你真的想让它离线运行吗?
比如,如果你的网站只是个聊天框,那可能就没什么意义了。如果你不在线,怎么和别人聊天呢?
但“离线”并不意味着您的用户一直处于离线状态。
这实际上意味着,越来越多的用户通过移动设备访问您的网站。而移动设备的连接往往不稳定、断断续续或速度缓慢。
正是在这些情况下,你的网站应该提供足够好的体验,让用户不想离开你的网站。你的网站不应该崩溃,而应该提供一些吸引用户离开的功能。
如果您确保您的网站资产(CSS、图像、JavaScript)可以从本地缓存中提供,那么您的资产将立即可用,而无需通过网络获取。
如果您确保最常访问的页面也已本地缓存,那么这些页面也将立即可用。
这就是当用户在网速缓慢、断断续续的情况下访问你的网站时,体验会有所不同,而这正是“离线”的真正含义。如果在这种环境下,你的网站仍然能够提供良好的用户体验,你就赢了。
访问一些您最喜欢的网站,关闭您的 wifi 或 4G,刷新页面,看看会发生什么。
大多数都会失败,并向你展示这一点:

没必要这么做。还有更好的办法。

如何让您的网站离线运行
要让您的网站离线运行,您只需添加一个 Service Worker。Service Worker 是一种Web Worker,它充当您的网站、浏览器和网络之间的代理服务器,使您能够拦截请求和响应。
稍微思考一下:通过在你的网站上添加 Service Worker,你现在就可以拦截所有发出的请求和收到的响应。仅凭这一点,就足以成为你添加 Service Worker 的理由了。
现在,您可以拦截请求并提供任何您想要的服务。您可以直接从本地缓存提供静态资源,甚至可以从IndexedDB提供 API 响应和 BLOB 数据。
要注册服务工作者,请创建一个名为service-worker.js(任何名称都可以)的文件并将其放在应用程序的根目录中。
接下来,调用navigator.serviceWorker.register以实际注册服务工作者。
将其包装在检查中以确保旧浏览器不会崩溃:
const cacheName = 'my-cache';
const filestoCache = [
'/index.html',
'/css/styles.css',
'/js/app.js',
'/img/logo.png'
];
self.addEventListener('install', e => {
e.waitUntil(
caches.open(cacheName)
.then(cache => cache.addAll(filesToCache))
);
});
您的网站现在已由 Service Worker 控制。但是,由于该文件仍然为空,它实际上不会执行任何操作。Service Worker 是一个事件驱动的 Web Worker,因此我们需要添加代码来响应这些事件,首先从生命周期事件开始。
Service Worker 生命周期
为了确保 Service Worker 不会破坏网站,它们会经历严格定义的生命周期。这确保只有一个 Service Worker 控制着您的网站(因此您的网站也只有一个版本)。
服务工作者生命周期还确保新的服务工作者不会中断当前正在运行的服务工作者。
安装事件
第一个触发的事件是install事件。当 Service Worker 下载、解析并成功执行时,会触发该事件。
如果在此阶段出现任何问题,则返回的 Promisenavigator.serviceWorker.register将被拒绝,install事件将不会触发,并且 Service Worker 将被丢弃。如果已经有一个 Service Worker 正在运行,它将继续运行。
如果 Service Worker 成功安装,该install事件将会触发。在事件处理程序中,您将缓存静态资源。
缓存是使用[CacheStorage](https://developer.mozilla.org/en-US/docs/Web/API/CacheStorage)位于 中的对象完成的window.caches。
首先,我们打开一个缓存,然后将我们想要缓存的资产路径数组传递给该addAll方法。
该open方法返回一个 Promise,我们将这个 Promise 传递给waitUntilinstall 事件的方法,以便在安装完成时以及安装成功时向浏览器发出信号:
cacheName = 'my-cache';
const filestoCache = [
'/index.html',
'/css/styles.css',
'/js/app.js',
'/img/logo.png'
];
self.addEventListener('install', e => {
e.waitUntil(
caches.open(cacheName)
.then(cache => cache.addAll(filesToCache))
);
});
同样,如果传递给的 Promise 被e.waitUntil拒绝,它将向浏览器发出安装失败的信号,并且新的服务工作者将被丢弃,而现有的服务工作者(如果有)将继续运行。
activate 事件
成功安装新的 Service Worker 后,该activate事件将被触发。Service Worker 现已准备好控制您的网站,但目前还无法控制它。
Service Worker 激活后,仅当您刷新页面时才会控制您的网站。同样,这是为了确保一切正常。
服务工作线程控制的网站窗口称为clients。在 事件的事件处理程序中install,可以clients通过调用 来控制 不受控制的窗口self.clients.claim()。
服务工作线程将立即控制网站,但这仅在服务工作线程首次激活时有效。激活新版本的服务工作线程时,此功能无效:
self.addEventListener('activate', e => self.clients.claim());
拦截请求
服务工作者的杀手级功能是拦截请求和响应的能力。
每当 Service Worker 控制的网站发出请求时,fetch都会触发一个事件。request的属性FetchEvent允许访问发出的请求。
在事件处理程序中,我们可以提供之前在事件处理程序中添加到缓存中的静态资产install:
self.addEventListener('fetch', e => {
e.respondWith(
caches.match(e.request)
.then(response => response ? response : fetch(e.request))
)
});
通过调用respondWith的方法FetchEvent,可以阻止浏览器的默认获取处理。我们调用 ,并Promise解析为Response,然后将其提供给浏览器。
这里,我们调用caches.match()来检查资源是否已被缓存。如果已缓存,则会从缓存中获取。如果没有,我们仍然会通过调用 来从网络获取资源fetch(e.request)。
这确保了静态资产只要之前被缓存过,就始终可以从缓存中提供。
现在,无论何时您的网站用户处于移动网络连接不佳或甚至完全离线状态,缓存的资产仍将被提供,您可以为用户提供良好的用户体验。
如果您的网站仅包含静态 HTML 页面,您也可以缓存所有页面,并且无论用户是否在线都可以查看您的整个网站 - 只要他们至少之前访问过您的网站。
拦截响应
但这还不止于此。例如,如果您的网站从 REST API 获取动态内容,您也可以缓存该内容。
每当向 API 发出请求时,我们都可以缓存响应以供后续使用。如果再次发出相同的请求并因任何原因失败,我们只会提供之前缓存的响应。
self.addEventListener('fetch', e => {
const {method, url} = e.request;
const requestClone = e.request.clone();
if(url.includes('/api')) {
e.respondWith(
fetch(e.request)
.then(response => {
const responseClone = response.clone();
if(method === 'GET') {
cacheApiResponse(responseClone);
}
return response;
})
.catch(err => {
if(method === 'GET') {
return getCachedApiResponse(e.request);
}
if(method === 'POST') {
cacheApiRequest(requestClone);
return new Response(JSON.stringify({
message: 'POST request was cached'
}));
}
})
);
}
else {
e.respondWith(
caches.match(e.request)
.then(response => response ? response : fetch(e.request))
);
}
});
当请求的 URL 包含 时/api,我们就知道这是对 API 的调用。然后我们通过调用 来传递它e.respondWith,fetch(e.request)这实际上只是转发了同一个请求。
当响应到达时,需要将其克隆,使用cacheApiResponse方法(省略实现)保存到IndexedDB,然后提供服务。
但是,当获取过程中发生错误并且 Promise 从fetch(e.request)拒绝中返回时,我们会捕获该错误并提供之前使用缓存的 API 响应getCachedApiResponse(e.request)。
这样,我们可以确保即使用户离线或由于其他原因无法访问 API,对动态内容的调用也会成功。
自动同步
上面的例子主要通过 GET 请求来获取数据,但如果您需要执行 POST 请求来将数据保存在后端怎么办?
catch如您所见,以下示例中的子句中检查了 POST 请求:
.catch(err => {
...
if(method === 'POST') {
cacheApiRequest(requestClone);
return new Response(JSON.stringify({
message: 'POST request was cached'
}));
}
})
这意味着每当由于用户离线而导致对 API 的 POST 请求失败时,都会使用该cacheApiRequest方法保存请求的克隆(省略实现)并返回自定义响应,表明 POST 请求已保存。
这使我们能够保存对本地缓存(如 IndexedDB)所做的所有更改,并在用户重新上线时将这些更改发送到后端。
每当用户的连接恢复时,sync就会触发一个事件,我们可以重试之前进行的 API 调用:
self.addEventListener('sync', e => {
e.waitUntil(retryApiCalls());
});
预加载响应
到目前为止,我们已经了解了如何提供以前缓存的静态资产,以及如何保存 API 响应以便在 API 不可用或用户离线时从缓存中提供它们。
但是,用于获取动态内容的 API 调用必须至少先进行一次,以便可以缓存它们以供后续调用。
这意味着任何未首先进行的 API 调用都不会被缓存,因此在用户离线时将不可用。
如果您的网站仅包含静态 HTML 页面,您可以install通过将它们提供给cache.addAll()调用来在事件中缓存它们:
const filesToCache = [
'/index.html',
'/about.html',
'/blog/posting.html'
...
];
self.addEventListener('install', e => {
e.waitUntil(
caches.open(cacheName)
.then(cache => cache.addAll(filesToCache))
);
});
实际上,我们可以对从我们的网站发出的任何或某些 API 调用执行相同的操作来预取内容。
例如,如果您的网站是一个博客,您可以预先获取最新或最受欢迎的帖子,这样即使用户处于离线状态,它们也可以立即可用。
用户只需访问你网站的一个页面。当 Service Worker 激活后,我们会预加载所需的内容。正确的做法是activate使用 Service Worker 的事件:
self.addEventListener('activate', e => {
...
const postings = [
'/api/blog/1'
'/api/blog/3'
'/api/blog/9'
];
e.waitUntil(async () => {
await Promise.all(postings.map(url => prefetch(url)));
}());
});
const prefetch = async url => {
const response = await fetch(url);
const clone = response.clone();
cacheApiResponse(clone);
};
在事件内部activate,我们遍历一个包含数据的数组,例如我们最受欢迎的博客文章的 URL。然后在后台获取每篇文章,并使用该cacheApiResponse方法进行存储(省略具体实现)。
现在,我们可以从缓存中提供所有这些帖子,因此它们将立即可用,而无需网络调用。
您的网站不仅可以完全离线使用,而且还能几乎立即加载,为用户提供类似应用程序的体验。
缓存策略
缓存资源时可以采用多种策略。
缓存,回退到网络
在前面的例子中,静态资源的策略是始终先尝试缓存。如果资源未缓存,则尝试网络。
API 调用和其他 GET 请求也可以这样做。这是构建离线优先体验的最佳方法,但这也意味着用户可能会从缓存中收到过时的内容。
幸运的是,有一个解决方案,我们将在第三个策略中看到。
网络,回退到缓存
与上述策略相反,始终先尝试网络。如果失败,则从缓存中提供资源。
对于经常更新的资源来说,这是一个很好的策略,因此在线用户将始终获得最新的内容,而离线用户将获得(可能较旧的)缓存版本。
这种方法的缺点是,当网络请求需要一段时间时,如果该网络请求最终失败,则也需要一段时间才能回退到缓存。
先缓存,后网络
解决“网络,回退到缓存”策略问题的一个好方法是始终立即从缓存中提供资源,然后在后台发出网络请求来获取相同资源并更新缓存。
这种方法的好处是,所请求的资源始终立即可用,并且缓存的版本几乎始终是最新的。
当然,也有可能从网络获取的内容较新,而用户刚从缓存中获得的是旧版本。
在这种情况下,你可以从缓存中更新已显示的内容。但是,你需要注意不要破坏用户体验。
例如,用户可能正在阅读一篇文章的缓存版本。如果这篇文章突然更新了新的、不同的内容,您可能会提供糟糕的用户体验。
如果您非常确定要更新用户尚未看到的内容,您可以选择这样做。您还可以显示横幅,指示有新内容可用,并提示用户刷新页面。
如果资源对时间不是很敏感,您还可以选择仅显示缓存版本,并在后续访问时显示较新的版本。
通常,您需要根据资源类型同时使用多种策略。
经常更新的资源可能最好通过网络提供,而从缓存提供不经常更新的资源可能是安全的。
您应该确定最适合您的情况的方法,并根据您的需要调整服务人员。
通用错误回退:
如果网络和缓存都发生故障,或者缓存版本不可用,则可以提供通用错误响应。例如,可以显示一个页面,提示“网站暂时离线”。
这可以只是一个驻留在缓存中的静态 HTML 页面:
self.addEventListener('fetch', e => {
e.respondWith(
caches.match(e.request)
.then(response => response ? response : fetch(e.request))
.catch(() => caches.match('./offline.html'))
)
});
现在,去实现该服务工作者
Service Worker 让您能够控制网站与互联网之间的所有网络流量。这项功能带来了令人难以置信的强大功能。
您现在可以立即提供资源并为用户提供类似应用程序的体验。
除了控制网络流量之外,服务工作者还能让您的网站在用户未与您的网站互动时接收推送通知。
服务工作者还使您能够将您的网站转变为渐进式 Web 应用程序,从而允许用户将您的网站安装到他们的设备上并像原生应用程序一样与其进行交互。
但是,控制网络流量并使您的网站离线工作的能力应该足以成为今天为您的网站实施服务工作者的理由。
现在所有主流浏览器都支持 Service Worker,所以没有理由或借口不使用它。
你的用户会感谢你的。
编者注:觉得这篇文章有什么问题?您可以在这里找到正确版本。
插件:LogRocket,一个用于 Web 应用的 DVR

LogRocket是一款前端日志工具,可让您重播问题,就像它们发生在您自己的浏览器中一样。无需猜测错误发生的原因,也无需要求用户提供屏幕截图和日志转储,LogRocket 让您重播会话,快速了解问题所在。它可与任何应用程序完美兼容,不受框架限制,并且提供插件来记录来自 Redux、Vuex 和 @ngrx/store 的额外上下文。
除了记录 Redux 操作和状态外,LogRocket 还记录控制台日志、JavaScript 错误、堆栈跟踪、带有标头 + 正文的网络请求/响应、浏览器元数据以及自定义日志。它还会对 DOM 进行插桩,以记录页面上的 HTML 和 CSS,即使是最复杂的单页应用程序,也能重现像素完美的视频。
免费试用。
每个网站都应该有一名服务人员,该帖子最先出现在LogRocket 博客上。
文章来源:https://dev.to/bnevilleoneill/every-website-deserves-a-service-worker-3gbj