Hello Hadoop | 几分钟轻松学会Hadoop!
原文链接: https://jayachandrika.com
让我们探索 Hadoop(单击跳至该主题):
- Hadoop:它的热门话题是什么?
- Hadoop生态系统
- HDFS:Hadoop分布式文件系统
- YARN:又一个资源协商者
- MapReduce:映射器和化简器
- Pig:MapReduce 的快速简便替代方案
- 技术开发中心
- 蜂巢
- 安巴里:用户界面
- Mesos:YARN 的替代方案
Platform:Hortonworks 沙盒
Hadoop:它的热门话题是什么?
Hadoop is an open source software platform with utilities or tools, for distributed storage and distributed processing on very large files and datasets, performed on several computer
如果还没完全理解,我同意。让我们分解一下。
例如:假设我们获得了在 Google、亚马逊、Facebook 工作的数百万名员工的信息,我们必须合并他们的所有信息,并按薪水的降序重新制作列表。
将如此大数据装入一台普通的计算机进行运算,让计算机去处理每一个员工的数据,要么让计算机像SpaceX火箭一样爆发出来,要么需要很长时间去处理,直到我们的下一代才能看到输出!
如果我们将这些数据分配给多台计算机,每台计算机处理其中的一小部分,就可以快速输出,而不会因处理大量数据而超负荷。
这就是 Hadoop 所做的,
分布式存储-海量数据分布到多台计算机上并存储在那里。
分布式处理- 无需一台昂贵的高处理能力的计算机,只需几台普通计算机即可处理大数据。
简而言之,Hadoop 拥有存储和处理大数据的工具,并能为我们提供预期的结果。
让我们看看 Hadoop 究竟如何处理大数据!
Hadoop生态系统
Hadoop 有许多组件,每个组件都有自己的目的和功能。(有点像 Endgame 中的每个英雄都有自己的电影。)

HDFS、YARN 和 MapReduce 属于 Hadoop 生态系统的核心,其他一些技术则是后来为了解决特定问题而添加的。让我们逐一探讨它们。
假设我们有一大块土豆(大数据),我们想把它做成炸薯条、薯片和鸡块。
-
为了制作它们,我们将土豆分成 3 块:用于炸薯条的土豆、用于炸薯条的土豆和用于炸鸡块的土豆,
这就是HDFS所做的,将大块数据分割并分发到多台计算机。 -
每道菜所需的所有资源或配料都分别分配,类似于
YARN管理每个块或集群所需的资源。 -
我们将土豆转化成我们想要的菜肴,这与
MapReducers以有效的方式转换数据并汇总数据以得到我们想要的结果是一样的。
让我们更详细地探讨每个组件。
HDFS:Hadoop分布式文件系统
正如它所说,它将大文件分布到多台计算机上,如下所示:
-
大文件被转换成块(每个块最大可达 128 Mb)
-
数据块存储在多台计算机上。
-
冗余:为了应对一台计算机发生故障,每个数据块的多个副本存储在每台计算机上。这样,如果一台计算机发生故障,其他计算机仍然可以获取故障计算机的数据。
YARN:又一个资源协商者
- 它是 Hadoop 系统的心跳,所有数据处理都发生在这里。
- 它为应用程序执行提供 CPU、内存等计算资源。
- 它执行作业调度并管理资源,例如哪些节点可用,哪些节点应该被允许运行任务等。
- 通常建议不要直接在 YARN 上编写代码。相反,可以使用更高级的工具,例如 Hive,这样可以简化你的工作。
在某种程度上,就像操作系统如何为计算机分配资源一样,allocates resourcesHadoop 中的 YARN。
MapReduce:映射器和化简器
我们已经将数据写入了 HDFS,并从 YARN 分配了资源。现在该如何从中获取我们想要的结果呢?我们使用 MapReduce 进行编码。
MapReduce 有两个功能:Mapper 和 Reducer。
这里使用 Python 或 Java 编程来编写这些功能。总的来说,它是一种跨数据处理和计算的编程模型。
- 映射器根据所需的输出拆分数据并进行映射。
- Reducer 获取映射器的输出并聚合或组合数据以给出结果。

当输入到达时,映射器会逐个转换数据并根据我们想要的输出进行组织。
简化器将映射器的输出简化为我们需要的聚合形式。
Pig:MapReduce 的快速简便替代方案
- Pig Latin,
a scripting language使用类似 SQL 的语法,形成关系、选择数据、过滤数据、转换数据等。包含User defined functions帮助我们创建自己的功能。 - 并非所有业务问题都可以通过转换为 MapReduce 和 Reducer 的形式来解决。因此,Pig Latin 位于 MapReduce 之上,将我们的 Pig Latin 脚本转换为 MapReduce 形式。
-
Pig 脚本可以通过以下三种方式之一运行:
- Grunt(命令行解释器)
- 脚本(将脚本放入文件中并运行)
- Ambari(直接从 Pig View 查看)

技术开发中心
-
我们可能会担心在 mapreduce 上使用 pig 是否会增加延迟。Tez 介于两者之间,可以进行优化,使其速度提高 10 倍。
-
它使 Hive、Pig 和 Map Reduce 作业更快,优化物理数据流和资源使用。
-
使用 DAG(有向无环图),它可以看到作业的工作流程并找到其中的最佳方法,从而使我们的工作更轻松。
假设:我们有三条路径,1-2-3、4-9-8、2-7-9,我们需要找到最小路径,我们选择1-2-3。DAG 的工作方式与此类似。
- 输出通过 DAG 反复处理,最终给出最优解决方案。
蜂巢
- 它
SQL queries从命令提示符获取输入并将其转换为 mapreduce 作业并自动完成作业。 - 我们可以将查询结果存储到中
view,对整个集群执行查询,然后define our own functions。 -
尽管 Pig 和 Hive 可能相似,但 Hive 用于完全结构化数据,而 Pig Hadoop 组件用于半结构化数据。
-
Pig 相对而言比 Hive 更快。
-
与 Pig 和 Spark 不同,Hive 速度较慢,不适用于实时交易。
-
它可能给人一种关系数据库的感觉,但它不能删除、插入等,因为没有表、连接、主键,数据只是平面文本
de-normalized。

正如您所看到的,所使用的查询与 SQL 查询相同。
安巴里:用户界面
- 它基本上是一个以图形方式与集群及其使用进行交互的 Web 界面。
- 它为我们提供了集群的高级视图,包括正在运行的内容、正在使用的系统以及可用/正在使用的资源。
- 它显示有关集群的统计数据,如 CPU 使用率、内存使用率、网络使用率、集群负载等。
- 所有服务(如 HDFS、YARN 等)都可以在使用 Ambari 的集群上使用。
- 甚至可以使用 Ambari 安装 Hadoop。

Mesos:YARN 的替代方案
- 它与 YARN 类似,但不同之处在于 Mesos 更通用。
-
简单来说,YARN 仅适用于 Hadoop 组件(如 mapreduce 等),而 Mesos 可以将资源分配到 Hadoop 外部,如 Web 服务器。
-
YARN 适用于分析和长流程作业,而 Mesos 适用于长流程和短流程作业。
Spark:Hadoop棋盘上的女王
- Spark 引擎非常快,实际上比 mapreduce 快 100 倍,可用于大规模数据处理。
- 像 Hive -> 它可以处理 SQL 查询,像 Apache STORM -> 它可以处理实时流,因此我们称它为女王。
-
Spark 中的处理方式如下:
Driver Program,包含控制作业中发生的情况的脚本。Cluster Manager,可以是YARN,Mesos或者其自身的Spark Cluster Manager。Executor,它包含基于缓存优先内存的解决方案,这与其他基于磁盘的解决方案不同。
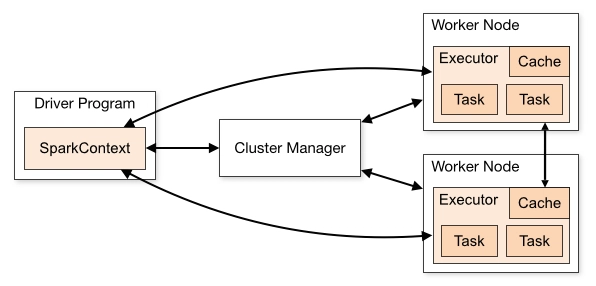
Spark 有许多组件:
- Spark Streaming:处理实时数据。
- Spark SQL:SQL 接口,接受 SQL 查询。
- MLLib:无需映射器和化简器即可执行机器学习操作来解决问题。
- GraphX:所有与图形相关的问题和分析都是使用它完成的。
- Spark Core:提供分布式任务调度、调度和基本I/O功能。


Spark 使用一种称为的专门的基本数据结构RDD (Resilient Distributed Datasets)。它是一个代表数据集的对象,我们可以像在 Java 中一样对该对象执行操作。
HBase
- 它基本上是一个可扩展的
NoSQL Database。 - 列式数据存储速度非常快,并且对于高数据交易率很有用。
- 这里采用 CRUD(创建、读取、更新和删除)操作。
阿帕奇风暴
realtime streaming data像来自传感器或网络日志等的连续处理。- 即使 Spark Streaming 也能做到这一点,但更多的是在批处理间隔内,而 Storm 则以事件方式处理数据。
- Spout 指的是流数据源,也就是它们产生的数据。Bolts 指的是转换或聚合流数据的组件。
- 通常kafka(将数据发送到集群)和storm成对使用。
OOZIE
-
在 Hadoop 上运行和安排各种作业/任务。
-
说明通过 XML 文件提供。
ZooKeeper
- 协调集群上的所有事务。例如,哪个是主节点、每个工作节点的任务分配、哪些节点处于启动状态、哪些节点处于关闭状态以及哪些工作节点可用等等。
- 如果主节点死亡,它会选择下一个主节点。
示例:可以在 whatsapp 群组或视频通话中观察到这种现象,如果主持人离开群组,则会指定其他人作为下一个主持人。
Outside Hadoop EcoSystem, we can have databases to store the data and Query Engines to get input data to the cluster. Lets have a look at them!
数据提取:Sqoop + Flume + Kafka
那么如何将数据导入集群呢?Sqoop、Flume 和 Kafka 通过数据提取来帮助实现这一点。
Sqoop:Sqoop是一个用于在关系数据库服务器和Hadoop之间传输数据的命令行界面应用工具。
- 这只是将 Hadoop 数据库与关系数据库绑定的一种方式。
Flume:将数据发送到集群的另一种方式,它充当数据进入和存储之间的缓冲区,这样集群就不会因为实时传入的大量数据而崩溃。
Kafka:这是一个更通用的发布者/订阅者模型,其中publishers发送/生成topics由订阅的数据consumers。
- 从 PC、网络服务器等收集任何类型的数据并将其广播到 Hadoop 集群。
外部数据存储:MySQL、Cassandra、MongoDB
MySQL:典型的SQL基于关系的数据库。
Cassandra:它是一个NoSQL列式数据库,没有单点故障。它符合 CAP 理论中的可用性和部分容错性。
MongoDB:一个NoSQL使用文档模型的数据库。它用于处理海量数据,并且非常灵活。

查询引擎:Drill + Hue + Phoenix + Presto + Zeplin
所有这些都是交互式查询引擎,用于从其下的数据库(如 Hbase、Cassandra 等)中获取所需的数据。
-
Drill让我们使用 SQL 查询,即使其下的数据库(Hbase、Cassandra、MongoDB 等)是非关系数据库。 -
Phoenix类似于使用 SQL 查询的钻取,但具有 ACID 属性(原子性、一致性、隔离性和持久性)。它速度很快,但仅适用于 HBase。 -
Presto与 Drill 类似,但与 Drill 不同的是,它连接到 Cassandra 并跨集群执行查询。 -
Hue(Hadoop 用户体验)SQL 云编辑器用于查询并作为 Cloudera 中的 UI,就像 Ambari 之于 HortonWorks 一样。 -
Zeppelin具有 Notebook UI,可以可视化类似于 TensorFlow 的 jupyter 笔记本的数据并共享、与代码交互。
看到许多组件执行相同的工作可能会让人不知所措。最终,根据任务和数据库类型(无论是关系数据还是非结构化数据等)和其他因素,我们需要决定正确的组件并利用它,这需要对组件、实践和经验的了解。
希望您在学习 Hadoop 的过程中玩得开心,我个人也非常乐意分享它!!
原文链接: https://jayachandrika.com
现在您可以在 Instagram 上关注我们,探索更多有趣的话题:@code_voyager
很高兴您来到这里,让我们回来继续下一篇文章并探索更多!
祝您度过美好的一天!
继续阅读 https://dev.to/chandrika56/hello-hadoop-learn-hadoop-in-just-a-few-minutes-easily-1687