构建 Raspberry Pi Hadoop / Spark 集群
下载 java 包
提取包内容
更新替代配置
选择所需的 Java 版本
检查 Java 版本变化
获取工具
运行该工具
专业提示:如果您只想了解如何配置 Hadoop 和 Spark 在集群上运行,请从这里开始。
目录
- 动机和背景
- 什么是 Apache Hadoop?
- Map-Reduce 和并行化
- 什么是 Apache Spark?
- 硬件
- 关于 Raspberry Pi
- 选择 Pi 模型
- 以太网供电 (PoE) 和网络
- 磁盘空间
- 成本和总体规格
- 安装 PoE HAT
- 软件
- 操作系统
- 联网
- 保护集群
- Hadoop 和 Spark
- 单节点设置
- 集群设置
- 结论
动机和背景
“大数据”已成为近十年来的行业热门词汇,但对于该术语的含义以及大数据分析领域涵盖的内容,人们一直存在争议。Apache 软件基金会的 Hadoop 和 Spark(H&S)等大数据工具的使用,褒贬不一。事实上,与其他工具一样,H&S 只有在掌握了正确的使用时机和方法后才能发挥作用。
许多公司使用 H&S 进行数据存储和分析。具备这些技能的开发人员供不应求,但直到最近,如果不投入大量时间和/或金钱,很难获得集群计算的必要经验。如今,像全新Raspberry Pi 4(起价 35 美元)这样的小型廉价单板计算机的广泛普及,几乎消除了开发自主集群的这些障碍。
在本指南中,我将教您如何构建一个由树莓派组成的联网集群。我们将让它们通过网络交换机相互通信,安装 HDFS,并让 Spark 通过 YARN 在整个集群中运行分布式处理作业。本指南全面介绍了搭建树莓派和树莓派集群所需的硬件和软件,并且可以(就像树莓派一样!)扩展到任意数量或规模的机器。
什么是 Apache Hadoop?
Apache Hadoop 分布式文件系统 (HDFS) 是一个分布式(网络化)文件系统,可在现成的消费级硬件上运行。在联网的商用硬件上运行意味着 HDFS 兼具可扩展性和成本效益。HDFS 将文件拆分为“块”(通常大小为 64MB),并将这些块的多个副本存储在同一机架上的不同“数据节点”上、同一数据存储中心的不同机架上或跨多个数据存储中心的多个数据节点上。

以这种方式拆分和存储数据有几个优点:
-
容错。每个块都会生成冗余副本,并存储在多个物理位置。这意味着,如果某个磁盘发生故障(对于大量商用硬件而言,这种情况很常见),该节点上的所有块都可以从其他位置获取。HDFS 还可以为丢失的块创建额外的副本,从而始终保持所需的冗余块数量。
在旧版本的 Hadoop 中,单个 NameNode 可能会给整个系统带来潜在的安全漏洞。由于 NameNode 保存着文件系统及其所有更改的信息,因此一个 NameNode 发生故障会危及整个集群的安全。在新版本中,一个集群可以拥有多个 NameNode,从而消除了单点故障。
-
并行化。数据分块后,使用Map-Reduce分析流水线进行并行处理已成熟。将一个文件分块到 100 个数据块,在 100 台性能相近的机器上处理,其时间大约是单台机器处理相同文件的 1/100。
-
数据本地性。数据块的本地处理也消除了跨网络传输大型数据文件的需要。这可以大幅降低网络带宽需求。原本需要从存储库复制文件的时间和计算能力,现在可以用来在本地处理数据:“移动计算比移动数据更便宜”。
-
大型数据集。由于 HDFS 将文件拆分成块,因此任何单个文件的大小仅受网络可用存储总量的限制。HDFS 基于 POSIX 规范,但放宽了部分 POSIX 要求,从而支持快速数据流传输等诸多优势。HDFS 可以支持数百个联网节点和数千万个文件。
HDFS 通过将磁盘 I/O(读/写)延迟分散到网络上的所有磁盘上来加快数据处理速度。它不再从单个磁盘上的某个位置读取文件,而是由多台机器同时从多个位置读取文件。这些机器可以并行操作同一个文件,从而将处理速度提升几个数量级。
关于 HDFS ,需要注意的一点是,为了确保数据一致性,写入 HDFS 的文件是不可变的。这意味着,要编辑文件,必须先将其从 HDFS 下载到本地文件系统,进行更改,然后再上传回 HDFS。此工作流程与大多数用户习惯的工作流程略有不同,但对于 HDFS 提供的高吞吐量数据访问而言,这是必不可少的。HDFS 并非旨在取代普通的交互式文件系统。它应该用作大数据的存储库,这些数据不会定期更改,但需要快速轻松地进行处理。它是一个“一次写入,多次读取”的文件系统。
如果您有兴趣,可以在这里阅读有关 HDFS 的具体架构细节。
Map-Reduce 和并行化
HDFS 上存储的数据具有分布式特性,非常适合使用map-reduce分析框架进行处理。Map-reduce(也称为“MapReduce”、“Map-Reduce”等)是一种编程技术,它尽可能地并行执行可并行的任务,并解决任何不可并行的“瓶颈”。Map-reduce 是一个通用的分析框架,而非一种特定的算法。(然而,在大数据领域,它有时与 Apache 的Hadoop MapReduce同义,后者将在下文详细讨论。)

一些数据分析任务是可并行化的。例如,如果我们想在特定的数据库中找出所有单词中最常见的字母,我们可能首先要计算每个单词的字母数量。由于一个单词中字母的频率不会影响另一个单词中字母的频率,所以这两个单词可以分别计数。如果你有 300 个长度大致相等的单词,并且有 3 台计算机来计数它们,那么你可以将数据库分开,给每台机器 100 个单词。这种方法的速度大约是用一台计算机计算所有 300 个单词的 3 倍。请注意,任务也可以跨 CPU 核心并行执行。
注意:将数据拆分成块进行并行分析会产生一些开销。因此,如果这些块无法并行处理(例如一台机器上只有一个 CPU 核心可用),算法的并行版本通常会比非并行版本运行得更慢。
当上述示例中的每台机器都分析完所有 100 个单词后,我们需要对结果进行综合。这是一项不可并行的任务。一台计算机需要将所有其他机器的结果加起来,以便对结果进行分析。不可并行的任务是瓶颈,因为在它们完成之前,无法开始进一步的分析。
常见的可并行任务包括:
- 过滤(例如:删除无效或不完整的数据)
- 转换(例如:格式化字符串数据,将字符串解释为数字)
- 流式计算(例如:总和、平均值、标准差等)
- 分箱(例如:频率、直方图)
常见的不可并行任务包括:
- 聚合(例如:将部分结果收集到单个全局结果中)
- 文本解析(例如:正则表达式、语法分析)
- 可视化(例如:创建摘要图)
- 数学建模(例如:线性回归、机器学习)
数据排序是一种不太适合上述任何一类算法的例子。虽然为了进行完整的全局排序,需要将整个数据集集中到一个位置,但对已经进行本地排序的小数据集进行排序,比对等量的未排序数据进行排序要快得多,也容易得多。以这种方式对数据进行排序本质上既是一个map 任务,又是一个reduce任务。
并行化并非适用于所有任务。有些算法本质上是顺序的(又称P 完全)。这些算法包括n体问题、电路值问题、用于数值近似多项式函数根的牛顿法,以及在密码学中广泛使用的哈希链。
什么是 Apache Spark?
HDFS于 2006 年首次发布时,曾与一个 Map-Reduce 分析框架(颇具创意地称为Hadoop MapReduce,通常简称为“MapReduce”)捆绑在一起。HDFS 和 MapReduce 均受 Google 内部研究的启发,是 Google 的“Google 文件系统”和“MapReduce”的 Apache 版本,Google 已获得后者的专利(该专利曾受到批评)。
Hadoop MapReduce 是用于处理存储在 HDFS 上的数据的原始分析框架。MapReduce 执行 map-reduce 分析流水线(如上所述),在“map”任务之前从 HDFS 读取数据,并在“reduce”任务之后将结果写回 HDFS。这种行为正是Apache Spark(被广泛视为 MapReduce 的继任者)相对于 MapReduce提供10 到 100 倍加速的原因之一。
Hadoop MapReduce 与 HDFS 协同工作,“以可靠、容错的方式在商用硬件的大型集群(数千个节点)上并行处理海量数据(数 TB 数据集)。 [来源]
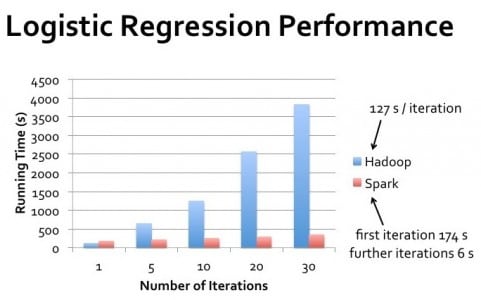
与 MapReduce 相比,Spark 至少具有四个主要优势:
-
Spark 最大限度地减少了不必要的磁盘 I/O。Spark在 MapReduce 的基础上进行了多项改进,力求尽可能减少磁盘读写操作。* MapReduce会将所有中间结果写入磁盘,而 Spark 则尽可能地将结果以流水线形式传输,仅在用户需要时或在分析流水线结束时才写入磁盘。Spark 还会将用于多个操作的数据缓存在内存中,这样就无需多次从磁盘读取。因此,Spark 有时被称为“内存处理”。(不过,这个术语有点误导,因为 MapReduce 和 Spark 都需要在 RAM 中处理数据。)
* 一般来说,CPU 缓存的读写速度比 RAM 快一个数量级,而 RAM 又比 SSD(甚至比传统硬盘还要快)快几个数量级。
-
Spark 提供了容错处理的抽象。Spark提供的主要数据结构是弹性分布式数据集 ( RDD ):
- 弹性——Spark会保存给定 RDD 如何从任何“父” RDD 构建的谱系。如果任何 RDD 损坏或丢失,可以轻松地从其谱系图(即其逻辑执行计划)重新创建。
- 分布式——一个 RDD 可能以物理形式存在于多台机器的不同部分。Spark 清晰地抽象了存储在 HDFS 上的文件的分布式特性。读取和处理存储在单台机器上的单个文件的代码,同样可以用来处理分布式文件,将文件分解成多个块并存储在多个不同的物理位置。
- 数据集——RDD可以存储简单对象(例如
Strings 和Floats),也可以存储更复杂的对象(例如元组、记录、自定义Objects 等等)。这些数据集本质上是可并行化的。
RDD 是不可变的数据集合,因此它们是线程安全的:它们可以并行处理,程序员无需担心竞争条件或其他多线程陷阱。(将存储在 HDFS 上的文件设置为不可变的逻辑与之类似。)
RDD 是惰性求值的。构建 RDD 时必须跟踪的一系列计算,直到需要使用该 RDD 时才会执行——打印到终端、绘制图表、写入文件等等。这减少了 Spark 执行的不必要处理量。
-
Spark 具有不同的处理模型。Spark使用有向无环图 ( DAG )处理模型,而不是简单的两步 map-reduce 流水线:
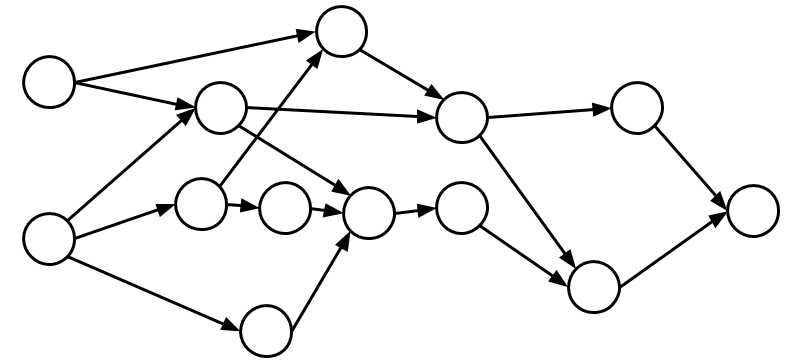
有向无环图(DAG)图这意味着 Spark 会从整体上审视整个处理流程,并尝试全局优化整个流程。MapReduce 会 (1) 从磁盘读取数据,(2) 执行“map”操作,(3) 执行“reduce”操作,(4) 将数据写入磁盘,而 Spark 对于何时完成操作更加灵活。只要朝着最终结果前进,map和reduce操作就可以并行执行,也可以在不同的数据块上在不同的时间执行。DAG 是 MapReduce map-reduce 流水线的更通用版本——它也可以被视为RDD理想化沿袭图的代码实现。
-
Spark 消除了 JVM 启动时间。通过在启动时(而不是在执行新作业时)在每个 DataNode 上启动 Java 虚拟机 (JVM),Spark 消除了加载
*.jar、解析任何配置文件等所需的时间。MapReduce 每次运行新任务时都会打开一个新的 JVM,所有这些启动开销都会在每个作业上产生。每次启动可能只需要几秒钟,但累积起来就会很麻烦。
此外,Spark 内置了对机器学习(MLlib)和图形处理(GraphX )等复杂分析的支持,并且可以在Python、R、Scala、Java 和 SQL shell中交互使用
上述特性使 Spark 比 MapReduce 速度更快、容错性更强、功能更丰富。Spark 拥有诸多优势,因此,只有在需要维护旧版 MapReduce 代码、不关心处理时间、不想花时间学习 Spark 的情况下,您才应该优先使用后者。
虽然还有其他分布式数据存储/分布式分析流程,但 Apache Hadoop 和 Spark 免费、快速、容错,并且相对易于安装和理解。有了对 H&S 的基础知识了解后,我们现在可以开始构建我们自己的 Raspberry Pi H&S 集群了。
硬件
关于 Raspberry Pi
树莓派基金会自2012年初以来一直致力于开发和发布单板计算机。最初的设想是像20世纪七八十年代的DIY“套件”计算机一样,激励孩子们学习电子技术和编程。然而,树莓派的受欢迎程度远远超出了基金会创始人的预期,销量达到1250万台,成为有史以来第三大最受欢迎的个人计算机,超过了Commodore 64,但仍落后于苹果Macintosh和Windows PC。诚然,树莓派引领了新一代计算技术的潮流,但它们也应用于家庭自动化、制造业、机器人技术、数码相机等领域。
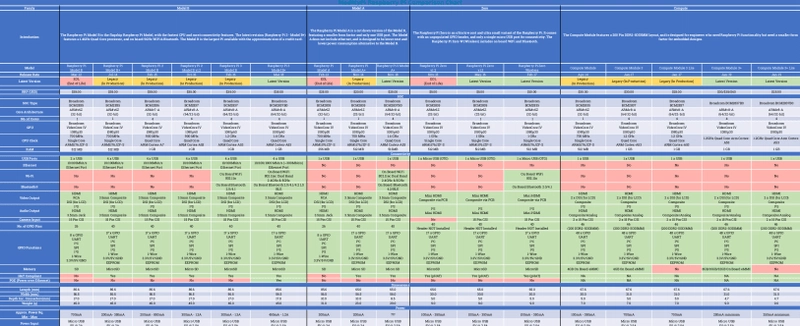
目前市面上有多种不同型号的 Raspberry Pi,它们分为四个系列:A 型、B 型、Zero 型和 Compute 型。B型系列是旗舰级、功能齐全的 Raspberry Pi。B 型均配备以太网连接,这是其他 Pi 系列所不具备的。所有 B 型的制造商建议零售价 (MSRP) 均为 35 美元。所有 B 型的尺寸完全相同:85.6 毫米 x 56.5 毫米 x 17.0 毫米,重量仅为 17 克。
B 型 Pi 的尺寸真的只有信用卡那么大!厚度也差不多跟键盘上的一个键一样宽。它们的大小和重量都跟一副扑克牌差不多。
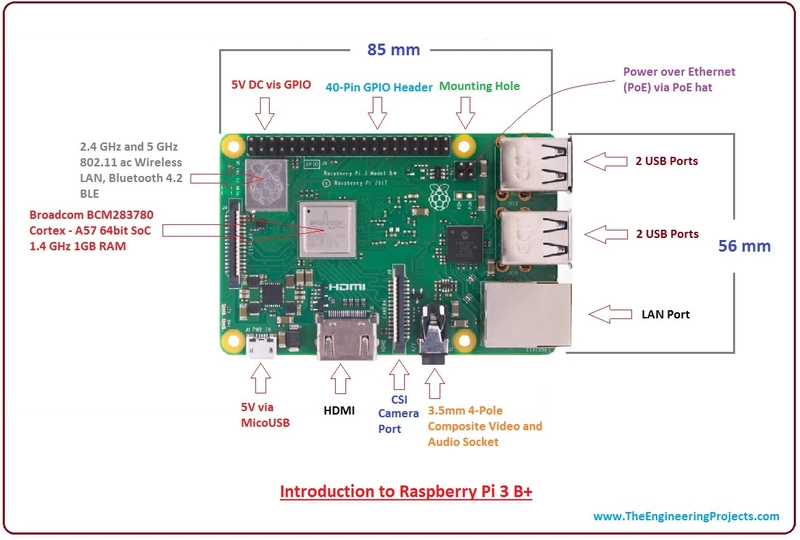
树莓派也有不同的版本。第一版包含 B 型和 B+ 型,B+ 型增加了两个 USB 端口,存储卡从 SD 卡切换到 microSD 卡,并且板子上的 GPIO(通用输入/输出)接口也进行了改动,以便添加Pi HAT(顶部附加硬件)。HAT 连接到 GPIO 引脚,为 Pi 增添了更多功能:支持 PoE(以太网供电)、散热风扇、LCD 屏幕等等。
版本 1 还包含 Model A 和 A+。A 系列体积更小,价格更便宜(20-25 美元),规格也更低(只有 1 个 USB 端口,没有以太网,内存更少)。Model Zero Pi 更加精简,价格也更低(5-10 美元)。所有这些 Pi 型号的详细信息都可以在上表中查看,也可以在网上的各种 比较 表中找到。
选择 Pi 模型
我们希望将树莓派联网以构建 Hadoop 集群,因此我们只能使用配备 Wi-Fi 和/或以太网硬件的型号。目前市面上的树莓派型号包括 Pi 3 Model B、Pi 3 Model B+、Pi 3 Model A+ 和 Pi Zero Wireless。所有这些树莓派都支持 WiFi 连接,但只有 Model B 和 B+ 支持以太网连接。
请注意,第 4 版树莓派 (V4) 几周前才刚刚发布,但商店库存一到就售罄了。如果可以的话,我建议使用第 4 版树莓派 (V4),而不是第 3 版。第 4 版树莓派拥有更快的处理器,并且支持添加更多内存(最高 4GB)。

如果我们使用 WiFi 连接树莓派,就需要一个无线路由器。我们还需要为每个树莓派购买电源。我打算搭建一个 8 个树莓派集群。八个电源会很笨重。如果我想向任何人炫耀我的集群,我就得把所有电源和一个多功能插座都带在身边。为了减少体积,我们可以改用 PoE 供电。这样可以同时解决每个树莓派的网络和电源问题,但价格更贵。这个选择限制了我只能选择 Model B 或 Model B+。
最后,为了消除树莓派可能造成的网络延迟(而且所有 B/B+ 型号的价格都相同),我打算选择树莓派 3 B+ 型号,它支持最大的以太网带宽(约 300Mbps)。对于我的 8 台树莓派集群来说,树莓派的总成本约为280 美元。
以太网供电 (PoE) 和网络
树莓派 B+ 型可以通过传统的直流电源(micro-USB)供电。这种电源每个售价约 8 美元(我的 8 块树莓派集群总共 64 美元),而且每个树莓派都需要有独立的电源插座。你可以在网上购买一个多功能插座(“电源板”),价格约为 9 美元。
另外,Pis B+ 也可以通过以太网供电,通过一种创造性地称为以太网供电 (PoE) 的技术。PoE 需要支持 PoE 的网络交换机;这些交换机通常比不支持 PoE 的交换机更贵。非 PoE 的 8 端口网络交换机在亚马逊上的售价仅为 10 美元,千兆 (1000Mbps) 交换机的售价仅为 15 美元。所有端口都支持 PoE 的 8 端口网络交换机售价约为 75 美元。通过以太网联网需要 8 根短以太网电缆(10 根一包约 14 美元)。如果您选择非 PoE 路线,您还可以使用优质、便宜的无线路由器(亚马逊上约 23 美元)将您的 Pi 联网。
那么,对于带有直流电源的有线(以太网)集群,我们至少需要 64 美元 + 9 美元 + 10 美元 + 14 美元 = 97 美元的网络和电源成本,或者对于带有直流电源的 WiFi 集群,我们至少需要 64 美元 + 9 美元 + 23 美元 = 96 美元的网络和电源成本。

我正在搭建的集群将用于演示,因此需要便于携带。八个电源加上一个多插座的设计并不理想,所以我选择了 PoE 供电方案。这样可以减少所有额外的体积,但需要付出一定的成本。一个 PoE Pi 集群需要 8 个 PoE HAT(每个约 21 美元),加上以太网线(10 条,14 美元),以及一个支持 PoE 的 8 端口网络交换机(约 75 美元)。这意味着一个 PoE Pi 集群至少需要257 美元的网络和电源成本,是无线集群的 2.5 倍以上。

我还有一个小麻烦。我从 C4Labs 为我的 Pi 集群买了一个专用便携包(55 美元),所以我唯一能从亚马逊英国订购的网络交换机(由于空间限制)是TRENDnet V1.1R,价格约为 92 美元。所以我的网络和电源总成本(加上这个便携包)是329 美元。
请注意,以上报价均不含运费。此外,C4Labs 机箱自带冷却风扇,旨在从树莓派的 GPIO 5V 引脚获取电源。由于 PoE HAT 会占用这些引脚,我购买了一些 USB 接口和一把烙铁,以便将冷却风扇的电线焊接到 USB 接口上。这样,风扇就可以通过 USB 从树莓派获取电源。这两项购买使集群成本增加了约32 美元。
磁盘空间
树莓派不自带板载存储空间。不过,它们配备了 microSD 卡槽,因此可以使用 microSD 卡来存储树莓派的操作系统和数据。高价位的128GB micro SD 卡售价通常在 17.50 美元左右,但大多数这类卡的读取速度限制在 80MB/s 左右。截至本文撰写时,最便宜的 128GB SD 卡读取速度高达 100MB/s,单张售价约为 21 美元,整张卡的价格约为168 美元。
成本和总体规格
总而言之,我的 8-Pi 集群的总成本大约是
- 全部八个 Raspberry Pi Model B+ 售价 280 美元
- 所有电源和网络设备售价 274 美元
- 所有 microSD 卡售价 168 美元
- 55美元买一个漂亮的手提箱
- USB 接口和烙铁售价 32 美元
……总共大约 810 美元。把所有这些东西运到爱尔兰大约需要 125 美元,这样我的集群总成本就达到了 935 美元左右。注意,这还不包括键盘、鼠标、显示器或 HDMI 线缆的费用,这些东西都是我从其他项目借来的。
该 8 台机器集群的具体规格如下:
- CPU:8 x 1.4GHz 64位四核ARM Cortex-A53处理器
- RAM:8 x 1GB LPDDR2 SDRAM(最大数据速率 1066 Mbps)
- 以太网:千兆以太网(最大 300 Mbps),PoE 支持
- 存储:8 x 128GB microSD 存储(最大读取速度 80MB/s)
- 端口:8 个 HDMI 端口、8 个 4 个 USB 2.0 端口
不到 1000 美元,还不错!
安装 PoE HAT
Raspberry Pi 大部分情况下都是即插即用的。但由于我们要安装扩展板 (HAT),所以需要做一些硬件方面的工作。Raspberry Pi 官网提供了如何在 Raspberry Pi 上安装 PoE 扩展板的说明,操作非常简单:
-
找到Raspberry Pi 顶部的40 针 GPIO 接头和附近的4 针 PoE 接头,以及 PoE HAT 底部的相应 40 针和 4 针插槽,但暂时不要将任何东西放在一起。

当 PoE HAT 翻转至正面时,Pi 上的引脚应与 HAT 上的插槽对齐:

-
找到 PoE HAT 包装盒内附带的垫片和螺丝。至少应有 4 个垫片和 8 个螺丝。

-
将垫片从顶部拧到 HAT 上。

-
此时,如果您只组装一个 Pi,则需要将 Pi 连接到 HAT,方法是将垫片与 Pi 上的孔对齐,然后从 Pi 的底部拧入垫片,同时确保小心地将 Pi GPIO 和 PoE 引脚插入 HAT 上的 GPIO 和 PoE 插槽。

然而,对于我的集群,我把所有的树莓派都装在一个 C4Labs Cloudlet / Cluster 机箱里,所以树莓派需要固定在有机玻璃支架上。我撕掉了有机玻璃上的保护纸,然后如下图所示,加上了金属垫片和螺丝。

确保使用较长的螺丝,因为它们需要穿过有机玻璃、金属垫片、Pi 电路板,然后进入 PoE HAT 垫片:

一旦所有部件都拧在一起,Pi 就应该牢固地安装在有机玻璃支架上:









...就是这样!PoE HAT 已成功安装。
将 PoE HAT 压入 Pi 的引脚后,如果尝试取下它,请务必小心。在尝试取下 PoE HAT 时,很容易将引脚从电路板上拧下来。如果发生这种情况,您必须将引脚重新焊接到 Pi 上,或者改用 microUSB 电源(或者购买新的 Pi)。
软件
操作系统
Raspberry Pi有几十种操作系统可供选择。其中一些比较著名的包括:
-
Raspbian——由 Raspberry Pi 基金会开发和维护的基于 Debian 的操作系统(基金会推荐的系统操作系统)
-
Windows IoT Core ——Windows 的物联网 (IoT) 操作系统,适用于小型设备;外观和感觉与Windows 10类似
-
Ubuntu Core——最流行的 Linux 发行版之一Ubuntu 的精简版
-

-
RaspBSD ——Raspberry Pi 的 UNIX 伯克利软件发行版 (BSD) 的一个分支;macOS 也是基于 BSD 的
-
Chromium OS——谷歌基于浏览器的操作系统
-
RetroPie——一款可将您的 Raspberry Pi 变成复古游戏机的操作系统(不允许有版权的游戏!)
-
RISC OS Pi —— RISC OS的 Pi 优化版本,这是专为精简指令集芯片 (RISC) 开发的操作系统,例如 Raspberry Pi 中使用的 AMD 系列




尽管安装 RetroPie 很有趣,但我想我还是会坚持使用 Raspbian,因为它是 Raspberry Pi 基金会推荐的操作系统,并且针对Raspberry Pi 的低性能硬件进行了特别优化。
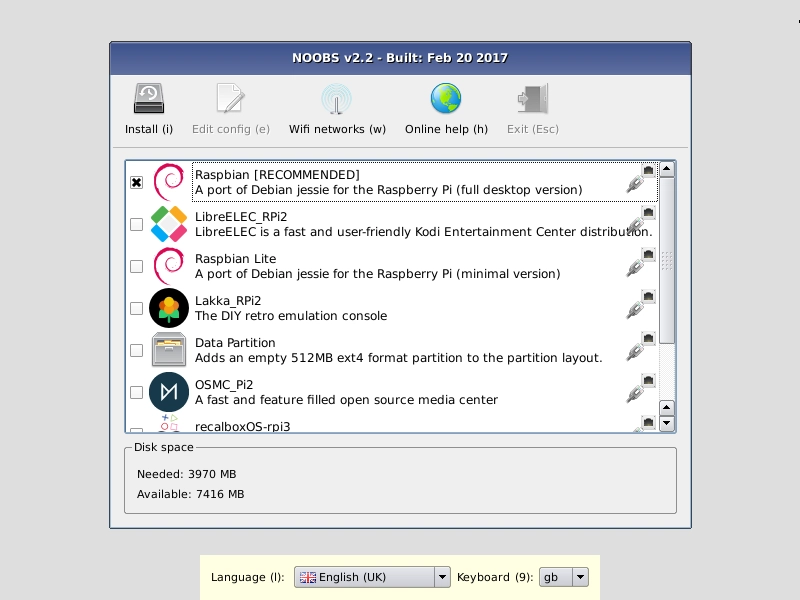
Raspbian 的NOOBS(全新开箱即用软件)安装程序是将 Raspbian 安装到 Raspberry Pi 的最简单方法。只需下载并按照Raspberry Pi 网站上的说明操作即可。您需要将microSD 卡格式化为 FAT(不是 ExFAT!),提取 NOOBS*.zip压缩包,然后将其中的文件复制到新格式化的 microSD 卡中。然后,将 microSD 卡插入 Pi;Pi 底部 USB 端口对面有一个插槽:


将以太网电缆插入 Pi,并将电缆的另一端插入支持 PoE 的网络交换机,为 Pi 供电。插入网络交换机并打开。一两秒钟后,Pi 应该会通电:以太网端口旁边的黄色指示灯和 microSD 卡附近的红色指示灯应该都会亮起。

然后,使用 GPIO 接头对面的 HDMI 端口将 Pi 连接到显示器。

通过 USB 将鼠标和键盘连接到 Pi,然后按照操作系统安装向导中的屏幕说明进行操作(它应该看起来类似于下面的屏幕截图)。
在一台树莓派上成功安装好你选择的操作系统后,你只需克隆 microSD 卡,即可在其他树莓派上安装相同的操作系统。无需多次执行安装向导。在本教程的后面,我将解释如何轻松地apt在集群中的所有树莓派上同时运行特定命令(包括使用 安装软件),这样你就不用像猴子在打字机前一样一遍又一遍地重复相同的手动任务了——这就是我们拥有科技的原因,不是吗?
联网
配置静态 IP 地址
为了方便树莓派联网,我将在网络交换机上为每个树莓派设置静态 IP 地址。我会根据树莓派在网络交换机和便携包中的位置,将它们编号为 1-8(含)。从树莓派上的端口(也就是便携包的“正面”)来看,1 号端口代表最右边的树莓派,8 号端口代表最左边的树莓派。
为了启用用户定义的静态 IP 地址,我编辑每个 Pi 上的文件/etc/dhcpcd.conf并取消注释/编辑以下行:
interface eth0
static ip_address=192.168.0.10X/24
…其中X应该替换为1Pi #1、2Pi #2 等等。在某个 Pi 上完成此更改后,我会重启机器。所有八个 Pi 都完成此操作后,它们应该都能ping通过这些地址互相访问。
我还在nmapPi #1 上安装了它,以便可以轻松检查所有八个 Pi 的状态:
$ sudo nmap –sP 192.168.0.0/24
…将显示所有其他七个 Pi 的状态,不包括运行该命令的那个。“ N hosts up”显示有多少个 Pi 已根据上述信息正确配置、当前已连接并已通电。
启用ssh
为了在每个 Pi 上启用ssh,我们需要遵循以下说明(在此处复制以避免链接腐烂):
自 2016 年 11 月发布以来,Raspbian 默认禁用 SSH 服务器。您可以从桌面手动启用它:
Raspberry Pi Configuration从Preferences菜单启动- 导航至
Interfaces选项卡- 选择
Enabled旁边SSH- 点击
OK或者,
raspi-config可以在终端中使用:
sudo raspi-config在终端窗口中输入- 选择
Interfacing Options- 导航至并选择
SSH- 选择
Yes- 选择
Ok- 选择
Finish或者,使用 systemctl 启动服务
$ sudo systemctl enable ssh $ sudo systemctl start ssh在可能连接到互联网的树莓派上启用 SSH 时,你应该更改其默认密码以确保其安全。更多详情,请参阅安全页面。
主机名
最初,所有的 Pi 都被称为raspberrypi,并且只有一个用户pi:
$ hostname
raspberrypi
$ whoami
pi
如果我们经常在网络上的不同树莓派之间来回切换,这可能会变得非常混乱。为了简化操作,我们将根据每个树莓派在网络交换机机箱 / 中的位置为其分配一个主机名。树莓派 1 被称为pi1,树莓派 2 被称为pi2,依此类推。
为此,必须编辑两个文件:/etc/hosts和/etc/hostname。在这些文件中, 应该只出现一次raspberrypi,这是默认主机名。我们将每个 更改为piX相应X的数字 1-8。最后,在/etc/hostsonly 中,我们还在文件末尾添加了所有其他 Pi 的 IP,例如:
192.168.0.101 pi1
192.168.0.102 pi2
...
192.168.0.108 pi8
这必须在每个 Pi 上手动完成。
在相应的树莓派上完成上述任务后,我们将重启该树莓派。现在,打开终端后,我们不再需要:
pi@raspberrypi:~ $
...你应该看到
pi@piX:~ $
...X该 Pi 在集群上的索引在哪里?我们在每个 Pi 上执行此操作,完成后重新启动它们。从现在开始,在这些说明中,命令提示符将缩写为$。任何其他代码均为输出或文件文本。
简化ssh
要从一个 Pi 连接到另一个 Pi,只需遵循上述说明,就需要以下一系列命令:
$ ssh pi@192.168.0.10X
pi@192.168.0.10X's password: <enter password – 'raspberry' default>
当然,这不需要输入太多代码,但如果我们必须经常这样做,就会变得很麻烦。为了避免这种情况,我们可以设置ssh别名,并ssh使用公钥/私钥对进行无密码连接。
ssh 别名
要设置ssh别名,我们在特定的 Pi 上编辑~/.ssh/config文件并添加以下几行:
Host piX
User pi
Hostname 192.168.0.10X
...将X8 个 Pi 中的 替换为 1-8。请注意,这是在单个 Pi 上完成的,因此一个 Pi 内应该有 8 个代码块~/.ssh/config,除了字符之外,它们看起来与上面的完全相同X,而字符应该会随着网络上的每个 Pi 而变化。然后,ssh命令序列就变成了:
$ ssh piX
pi@192.168.0.10X's password: <enter password>
通过设置公钥/私钥对可以进一步简化这一过程。
公钥/私钥对
在每个 Pi 上,运行以下命令:
$ ssh-keygen –t ed25519
这将在目录中生成一个公钥/私钥对,无需输入密码~/.ssh/即可安全使用ssh。其中一个文件名为id_ed25519,即私钥 。另一个文件名为 ,即公钥。id_ed25519.pub无需密码即可保护对密钥对的访问。公钥用于与其他 PI 通信,而私钥永远不会离开其主机,也绝不能移动或复制到任何其他设备。
每个公钥都需要连接到~/.ssh/authorized_keys其他所有 Pi 上的文件。最简单的方法是,在单个 Pi 上执行一次,然后将authorized_keys文件复制到其他 Pi。假设 Pi #1 包含“主”记录,然后将其复制到其他 Pi。
在 Pi #2(以及 #3、#4 等)上,运行以下命令:
$ cat ~/.ssh/id_ed25519.pub | ssh pi@192.168.0.101 'cat >> .ssh/authorized_keys'
这会将 Pi #2 的公钥文件连接到 Pi #1 的授权密钥列表,从而允许 Pi #2ssh无需密码即可访问 Pi #1(公钥和私钥用于验证连接)。我们需要在每台机器上都执行此操作,将每个公钥文件连接到 Pi #1 的授权密钥列表。我们也应该在 Pi #1 上执行此操作,这样当我们将完成的authorized_keys文件复制到其他 Pi 时,它们也都有权ssh访问 Pi #1。在 Pi #1 上运行以下命令:
$ cat .ssh/id_ed25519.pub >> .ssh/authorized_keys
一旦完成了这一步以及上一节的操作,ssh-ing 就变得非常简单:
$ ssh pi1
...就是这样!可以在~/.bashrc文件中配置其他别名,以进一步缩短此代码(见下文),但我们的系统上没有配置:
alias p1="ssh pi1" # etc.
复制配置
最后,要在所有 Pi 上复制无密码功能ssh,只需使用以下命令将上面提到的两个文件从 Pi #1 复制到其他 Pi scp:
$ scp ~/.ssh/authorized_keys piX:~/.ssh/authorized_keys
$ scp ~/.ssh/config piX:~/.ssh/config
现在您应该能够ssh通过 ,从任何其他 Pi 进入集群上的任何 Pi ssh piX。
易于使用
最后,对集群进行了一些其他的易于使用的增强。
获取除此 Pi 之外的所有 Pi 的主机名
要获取 Pi 的主机名,您只需使用:
$ hostname
pi1
...要获取集群上所有其他Pi 的主机名,请定义以下函数:
function otherpis {
grep "pi" /etc/hosts | awk '{print $2}' | grep -v $(hostname)
}
该
-v标志指示grep反转选择。仅返回不匹配的hostname行。
...~/.bashrc然后,在source您的~/.bashrc文件中包含:
$ source ~/.bashrc
(请注意,无论何时编辑~/.bashrc,为了使这些更改生效,您必须source删除文件或注销并重新登录。)然后,您可以在命令行上使用以下命令调用新函数:
$ otherpis
pi2
pi3
pi4
...
请注意,此功能依赖于您在文件中列出 Pi 的所有 IP 和主机名/etc/hosts。
向所有 Pi 发送相同的命令
要向每个 Pi 发送相同的命令,请将以下函数添加到~/.bashrc您想要从中口述命令的 Pi 中(我将其添加到 Pi #1 ~/.bashrc,然后~/.bashrc使用以下说明将文件复制到所有其他 Pi):
function clustercmd {
for pi in $(otherpis); do ssh $pi "$@"; done
$@
}
这将在每个其他 Pi 上运行给定的命令,然后在这个 Pi 上运行:
$ clustercmd date
Tue Apr 9 00:32:41 IST 2019
Tue Apr 9 05:58:07 IST 2019
Tue Apr 9 06:23:51 IST 2019
Tue Apr 9 23:51:00 IST 2019
Tue Apr 9 05:58:57 IST 2019
Tue Apr 9 07:36:13 IST 2019
Mon Apr 8 15:19:32 IST 2019
Wed Apr 10 03:48:11 IST 2019
……我们可以看到,所有树莓派的系统时间都不一样。我们来解决这个问题。
跨集群同步时间
只需告诉每台 Pi 安装该软件包htpdate,日期就会更新。就是这样:
$ clustercmd "sudo apt install htpdate -y > /dev/null 2>&1"
$ clustercmd date
Wed Jun 19 16:04:22 IST 2019
Wed Jun 19 16:04:18 IST 2019
Wed Jun 19 16:04:19 IST 2019
Wed Jun 19 16:04:20 IST 2019
Wed Jun 19 16:04:48 IST 2019
Wed Jun 19 16:04:12 IST 2019
Wed Jun 19 16:04:49 IST 2019
Wed Jun 19 16:04:25 IST 2019
注意,现在所有日期和时间的精度都在一分钟以内。如果我们重启所有树莓派,它们的精度会更高:
$ clustercmd date
Wed Jun 19 16:09:28 IST 2019
Wed Jun 19 16:09:27 IST 2019
Wed Jun 19 16:09:29 IST 2019
Wed Jun 19 16:09:31 IST 2019
Wed Jun 19 16:09:28 IST 2019
Wed Jun 19 16:09:30 IST 2019
Wed Jun 19 16:09:24 IST 2019
Wed Jun 19 16:09:28 IST 2019
现在它们已对齐,误差在 10 秒以内。请注意,在集群中运行该命令需要几秒钟。要将所有时钟精确同步到远程服务器(例如time.nist.gov或 等受尊重的标准google.com),您可以执行以下操作:
$ clustercmd sudo htpdate -a -l time.nist.gov
...这将需要几分钟,因为程序会以小于 30 毫秒的间隔缓慢调整时钟,这样任何系统文件时间戳都不会出现“跳跃”。此命令完成后,时钟将同步(请记住,通过网络通信需要一两秒钟,因此它们仍然会“偏差”两三秒):
$ clustercmd date
Wed Jun 19 16:36:46 IST 2019
Wed Jun 19 16:36:47 IST 2019
Wed Jun 19 16:36:47 IST 2019
Wed Jun 19 16:36:48 IST 2019
Wed Jun 19 16:36:49 IST 2019
Wed Jun 19 16:36:49 IST 2019
Wed Jun 19 16:36:49 IST 2019
Wed Jun 19 16:36:49 IST 2019
重启集群
我在 Pi #1 上添加了以下函数~/.bashrc:
function clusterreboot {
clustercmd sudo shutdown -r now
}
此功能可以轻松重启整个集群。另一个功能允许我在不重启的情况下关闭整个集群:
function clustershutdown {
clustercmd sudo shutdown now
}
将相同的文件发送给所有 Pi
要将文件从一个 Pi 复制到所有其他 Pi,让我们向任何特定 Pi 的文件添加一个名为clusterscp(cluster secure copy)的函数:~/.bashrc
function clusterscp {
for pi in $(otherpis); do
cat $1 | ssh $pi "sudo tee $1" > /dev/null 2>&1
done
}
然后,我们可以将定义的所有易于使用的功能复制到~/.bashrc集群上的每个其他 Pi 中:
$ source ~/.bashrc && clusterscp ~/.bashrc
保护集群
你可能只是为了好玩才搭建 Hadoop 集群,但我搭建集群是为了工作中的数据分析。由于我的集群将存储专有数据,因此集群安全至关重要。
我们可以采取很多措施来保护计算机免受未经授权的访问。最简单(也是最有效)的方法(ssh按照上文“简化”部分的说明设置无密码后ssh)是禁用基于密码的身份验证。这意味着用户只有拥有与某个树莓派上的某个私钥对应的公钥才能登录系统。虽然理论上这些密钥是可以破解的,但ed25519 是迄今为止最安全的公钥/私钥对算法,在可预见的未来很可能不会被破解。
禁用基于密码的身份验证和root登录
要禁用基于密码的身份验证,我们需要编辑文件/etc/ssh/sshd_config。其中有 6 个选项需要特别更改。在此文件中搜索以下键,并根据以下示例进行更改。确保以下所有行均不以“ #”开头,这将注释掉该行,以便系统忽略它。
PermitRootLogin no
PasswordAuthentication no
ChallengeResponseAuthentication no
UsePAM no
X11Forwarding no
PrintMotd no
上述命令分别用于:阻止黑客尝试以 身份登录root(因此他们需要知道用户名是pi);禁止基于密码的身份验证(因此他们需要在特定树莓派上找到与特定私钥对应的 ed25519 公钥);禁用树莓派之间/从/到树莓派的 X11(GUI)转发(所有操作都必须在命令行中完成);以及禁用“每日消息”(MOTD),该消息有时可能包含泄露信息。/etc/ssh/sshd_config在特定树莓派上编辑并进行上述更改,然后使用以下命令将这些更改复制到所有其他树莓派……
警告:请务必小心执行以下步骤。如果您在 中输入错误sshd_config,然后在树莓派上重启ssh服务,系统会报错,您将无法ssh再访问该树莓派。您需要手动(将 HDMI 线缆连接到视频输出)连接到树莓派进行重新配置!
$ clusterscp /etc/ssh/sshd_config
...并ssh在所有 Pi 上重新启动服务(重新加载配置):
$ clustercmd sudo service ssh restart
要完全删除 MOTD,请删除该文件/etc/motd:
$ clustercmd sudo rm /etc/motd
监控ssh活动fail2ban
为了监控和保护集群的完整性,我们可以做的另一件大事是安装一个名为“记录并根据可能的恶意活动暂时封禁 IP”的程序fail2ban。fail2ban要在集群中的每台机器上安装此程序,请运行以下命令:
$ clustercmd sudo apt install fail2ban –y
然后,将配置文件复制到单个 Pi 上:
$ cp /etc/fail2ban/jail.conf /etc/fail2ban/jail.local
jail.local...并编辑以开头的位置附近的行[sshd]。请注意,[sshd]出现在文件顶部附近的注释块中 - 忽略它。[sshd]应按如下方式配置:
[sshd]
enabled = true
port = ssh
logpath = %(sshd_log)s
backend = %(sshd_backend)s
完成编辑后jail.local,使用以下命令将其复制到集群上的所有其他 Pi:
$ clusterscp /etc/fail2ban/jail.local
...并使用以下命令重启fail2ban所有 Pi 上的服务:
$ clustercmd sudo service fail2ban restart
Hadoop 和 Spark
单节点设置
Hadoop
Apache Hadoop v2.7+需要 Java 7+才能运行。我在树莓派上安装 Raspbian 时,使用的是NOOBS v3.0.1 (2019-04-08)。这会安装 Raspbian 和 Java 1.8.0_65(HotSpot 又名 Oracle 的 Java 8)。所以所有树莓派都默认安装了合适的 Java 版本。接下来,我们可以下载并安装 Hadoop。
我将首先在主节点(树莓派 #1)上构建一个单节点集群,然后使用工作节点创建一个多节点集群。在树莓派 #1 上,使用以下命令获取 Hadoop:
$ cd && wget https://bit.ly/2wa3Hty
(这是 的缩短链接hadoop-3.2.0.tar.gz)
$ sudo tar -xvf 2wa3Hty -C /opt/
$ rm 2wa3Hty && cd /opt
$ sudo mv hadoop-3.2.0 hadoop
然后,确保更改此目录的权限:
$ sudo chown pi:pi -R /opt/hadoop
$PATH最后,通过编辑~/.bashrc并将以下行添加到文件末尾,将此目录添加到:
export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
...并编辑/opt/hadoop/etc/hadoop/hadoop-env.sh以添加以下行:
export JAVA_HOME=$(readlink –f /usr/bin/java | sed "s:bin/java::")
您可以通过检查版本来验证 Hadoop 是否已正确安装:
$ cd && hadoop version | grep Hadoop
Hadoop 3.2.0
火花
我们将以与上面下载 Hadoop 类似的方式下载 Spark:
$ cd && wget https://bit.ly/2HK6nTW
(这是 的缩短链接spark-2.4.3-bin-hadoop2.7.tgz)
$ sudo tar –xvf 2HK6nTW –C /opt/
$ rm 2HK6nTW && cd /opt
$ sudo mv spark-2.4.3-bin-hadoop2.7 spark
然后,确保更改此目录的权限:
$ sudo chown pi:pi -R /opt/spark
$PATH最后,通过编辑~/.bashrc并将以下行放在文件末尾,将此目录添加到您的目录中:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
您可以通过检查版本来验证 Spark 是否已正确安装:
$ cd && spark-shell --version
... version 2.4.3 ... Using Scala version 2.11.12 ...
HDFS
要启动并运行 Hadoop 分布式文件系统 (HDFS),我们需要修改一些配置文件。所有这些文件都在 中/opt/hadoop/etc/hadoop。第一个是core-site.xml。将其编辑如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://pi1:9000</value>
</property>
</configuration>
接下来是hdfs-site.xml,它看起来应该是这样的:
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///opt/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
...这将配置 DataNode 和 NameNode 信息的存储位置,并将副本数(即在集群中复制一个块的次数)设置为 1(稍后我们会更改)。请确保您也使用以下命令创建了以下目录:
$ sudo mkdir -p /opt/hadoop_tmp/hdfs/datanode
$ sudo mkdir -p /opt/hadoop_tmp/hdfs/namenode
...并调整这些目录的所有者:
$ sudo chown pi:pi -R /opt/hadoop_tmp
下一个文件是mapred-site.xml,它应该如下所示:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
...最后yarn-site.xml,看起来应该是这样的:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
编辑完这四个文件后,我们就可以格式化 HDFS 了(警告:如果 HDFS 中已经有数据,请不要这样做!数据将会丢失!):
$ hdfs namenode -format -force
...然后我们使用以下两个命令启动 HDFS:
$ start-dfs.sh
$ start-yarn.sh
...并通过创建临时目录来测试它是否正常工作:
$ hadoop fs -mkdir /tmp
$ hadoop fs -ls /
Found 1 items
drwzr-xr-x - pi supergroup 0 2019-04-09 16:51 /tmp
...或者通过运行命令jps:
$ jps
2736 NameNode
2850 DataNode
3430 NodeManager
3318 ResourceManager
3020 SecondaryNameNode
3935 Jps
这表明 HDFS 已启动并正在运行,至少在 Pi #1 上是这样的。要检查 Spark 和 Hadoop 是否协同工作,我们可以执行以下操作:
$ hadoop fs -put $SPARK_HOME/README.md /
$ spark-shell
...这将打开 Spark shell,并提示scala>:
scala> val textFile = sc.textFile("hdfs://pi1:9000/README.md")
...
scala> textFile.first()
res0: String = # Apache Spark
隐藏execstack警告
在运行上述 Hadoop 命令时,您可能会收到类似的警告...
“您已加载库...这可能已禁用堆栈保护。”
...在我们的 Raspberry Pi 上出现这种情况的原因是 Hadoop 二进制文件所针对的 32 位运行时与我们运行的 64 位 Raspbian 版本不匹配。要忽略这些警告,请将以下行
# export HADOOP_OPTS="-Djava.net.preferIPv4Stack=true"
.../opt/hadoop/etc/hadoop/hadoop-env.sh进入
export HADOOP_OPTS="-XX:-PrintWarnings –Djava.net.preferIPv4Stack=true"
这样以后就不会再出现警告了。(或者,您也可以下载 Hadoop 源代码并从头开始构建。)
隐藏NativeCodeLoader警告
您可能看到的另一个警告是util.NativeCodeLoader“ Unable to load [the] native-hadoop library for your platform”。此警告无法轻易解决。这是因为 Hadoop 是针对 32 位架构编译的,而我们拥有的 Raspbian 版本是 64 位。我们可以在 64 位机器上从头开始重新编译该库,但我宁愿不看到此警告。为此,我们可以在文件底部添加以下几行~/.bashrc:
export HADOOP_HOME_WARN_SUPPRESS=1
export HADOOP_ROOT_LOGGER="WARN,DRFA"
这将阻止NativeCodeLoader打印这些警告。
集群设置
此时,您应该拥有一个单节点集群,该单节点既充当主节点,又充当工作节点。要设置工作节点(并将计算分配到整个集群),我们必须执行以下步骤……
创建目录
使用以下命令在所有其他 Pi 上创建所需的目录:
$ clustercmd sudo mkdir -p /opt/hadoop_tmp/hdfs
$ clustercmd sudo chown pi:pi –R /opt/hadoop_tmp
$ clustercmd sudo mkdir -p /opt/hadoop
$ clustercmd sudo chown pi:pi /opt/hadoop
复制配置
使用以下命令将 /opt/hadoop 中的文件复制到每个其他 Pi:
$ for pi in $(otherpis); do rsync –avxP $HADOOP_HOME $pi:/opt; done
这将花费很长时间,所以去吃午饭吧。
回来后,使用以下命令查询每个节点上的 Hadoop 版本,验证文件是否正确复制:
$ clustercmd hadoop version | grep Hadoop
Hadoop 3.2.0
Hadoop 3.2.0
Hadoop 3.2.0
...
在集群上配置 Hadoop
很难找到一个好的指南来指导如何在联网的机器集群中安装 Hadoop。这个链接指向我遵循的指南,基本没有出现任何问题。为了使 HDFS 在整个集群中运行,我们需要修改之前编辑过的配置文件。所有这些文件都在 中/opt/hadoop/etc/hadoop。第一个是core-site.xml。将其编辑成如下所示:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://pi1:9000</value>
</property>
</configuration>
接下来是hdfs-site.xml,它看起来应该是这样的:
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop_tmp/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop_tmp/hdfs/namenode</value>
</property>
<property>
<name>dfs.replication</name>
<value>4</value>
</property>
</configuration>
下一个文件是mapred-site.xml,它应该如下所示:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>256</value>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>128</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>128</value>
</property>
</configuration>
...最后yarn-site.xml,看起来应该是这样的:
<configuration>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>pi1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>900</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>900</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>64</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
对这些文件进行以下更改,然后从所有树莓派中删除所有旧文件。我假设您正在逐步完成本教程,并且尚未向单节点树莓派 #1 集群添加任何重要的大型数据。您可以使用以下命令清理所有树莓派:
$ clustercmd rm –rf /opt/hadoop_tmp/hdfs/datanode/*
$ clustercmd rm –rf /opt/hadoop_tmp/hdfs/namenode/*
如果不这样做,可能会出现树莓派无法相互识别的错误。如果数据节点(树莓派 #2-#8)无法启动,或者无法与名称节点(树莓派 #1)通信,清理上述文件或许能解决问题(对我来说就是这样的)。
接下来,我们需要创建两个文件,$HADOOP_HOME/etc/hadoop/分别告诉 Hadoop 哪些 Pi 用作工作节点,哪些 Pi 用作主节点(NameNode)。master在上述目录中创建一个文件,并添加一行:
pi1
然后,在同一目录中创建一个名为workers(NOTslaves,与以前版本的 Hadoop 一样)的文件,并添加所有其他 Pi:
pi2
pi3
pi4
...
然后,你需要/etc/hosts再次编辑。在任何树莓派上,删除如下代码:
127.0.0.1 PiX
...X该 Pi 的索引在哪里?然后,使用以下命令将此文件复制到所有其他 Pi:
$ clusterscp /etc/hosts
现在就可以执行此操作,因为此文件不再特定于 Pi。最后,重启集群以使这些更改生效。所有 Pi 重启后,在 1 号 Pi 上运行以下命令:
警告:如果您的 HDFS 中已有数据,请勿执行此操作!否则数据将会丢失!
$ hdfs namenode -format -force
...然后我们使用以下两个命令启动 HDFS:
$ start-dfs.sh && start-yarn.sh
我们可以通过从任意一台树莓派(使用 )将文件放入 HDFS 来测试集群,hadoop fs -put并确保它们在其他树莓派(使用 )上显示。您还可以通过打开 Web 浏览器并导航至http://pi1:9870hadoop fs -ls来检查集群是否已启动并正在运行。此 Web 界面提供了文件资源管理器以及有关集群运行状况的信息。



在集群上配置 Spark
Spark 在单机上运行良好,因此我们可能会误以为我们正在充分利用 Hadoop 集群的全部功能,而实际上并非如此。我们上面执行的部分配置是针对 Hadoop YARN(又一个资源协商器)的。这是一个 HDFS 的“资源协商器”,负责协调文件在集群中的移动和分析方式。为了让 Spark 能够与 YARN 通信,我们需要在 Pi #1 中配置另外两个环境变量~/.bashrc。之前,我们定义了
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin
...在 中~/.bashrc。就在此之下,我们现在将添加另外两个环境变量:
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native:$LD_LIBRARY_PATH
$HADOOP_CONF_DIR是包含我们上面编辑的所有配置文件的目录*-site.xml。接下来,我们创建 Spark 配置文件:
$ cd $SPARK_HOME/conf
$ sudo mv spark-defaults.conf.template spark-defaults.conf
...我们将以下几行添加到此文件的末尾:
spark.master yarn
spark.driver.memory 465m
spark.yarn.am.memory 356m
spark.executor.memory 465m
spark.executor.cores 4
这些值的含义在此链接中解释。但请注意,以上内容与特定机器密切相关。上面的配置对我来说在 Raspberry Pi 3 Model B+ 上运行良好,但对于性能较低或较高的机器,它可能不适合您(或并非最佳选择)。Spark 也对可分配的内存量设置了严格的下限。您465m在上面看到的是该条目的最小可配置值——低于该值,Spark 将拒绝运行。
Raspberry Pi 3 Model B+ 在空闲状态下会使用 9-25% 的内存。由于它们总共有 926MB 的内存,因此每台 Raspberry Pi 最多可以使用 840MB 的内存来运行 Hadoop 和 Spark。
完成所有配置后,重启集群。需要注意的是,重启集群时,请勿再次格式化 HDFS NameNode。只需停止并重启 HDFS 服务即可:
$ stop-dfs.sh && stop-yarn.sh
$ start-dfs.sh && start-yarn.sh
现在,您可以通过命令行向 Spark 提交作业:
pi@pi1:~ $ spark-submit --deploy-mode client --class org.apache.spark.examples.SparkPi $SPARK_HOME/examples/jars/spark-examples_2.11-2.4.3.jar 7
OpenJDK Client VM warning: You have loaded library /opt/hadoop/lib/native/libhadoop.so.1.0.0 which might have disabled stack guard. The VM will try to fix the stack guard now.
It's highly recommended that you fix the library with 'execstack -c <libfile>', or link it with '-z noexecstack'.
2019-07-08 14:01:24,408 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2019-07-08 14:01:25,514 INFO spark.SparkContext: Running Spark version 2.4.3
2019-07-08 14:01:25,684 INFO spark.SparkContext: Submitted application: Spark Pi
2019-07-08 14:01:25,980 INFO spark.SecurityManager: Changing view acls to: pi
2019-07-08 14:01:25,980 INFO spark.SecurityManager: Changing modify acls to: pi
2019-07-08 14:01:25,981 INFO spark.SecurityManager: Changing view acls groups to:
2019-07-08 14:01:25,981 INFO spark.SecurityManager: Changing modify acls groups to:
2019-07-08 14:01:25,982 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(pi); groups with view permissions: Set(); users with modify permissions: Set(pi); groups with modify permissions: Set()
2019-07-08 14:01:27,360 INFO util.Utils: Successfully started service 'sparkDriver' on port 46027.
2019-07-08 14:01:27,491 INFO spark.SparkEnv: Registering MapOutputTracker
2019-07-08 14:01:27,583 INFO spark.SparkEnv: Registering BlockManagerMaster
2019-07-08 14:01:27,594 INFO storage.BlockManagerMasterEndpoint: Using org.apache.spark.storage.DefaultTopologyMapper for getting topology information
2019-07-08 14:01:27,596 INFO storage.BlockManagerMasterEndpoint: BlockManagerMasterEndpoint up
2019-07-08 14:01:27,644 INFO storage.DiskBlockManager: Created local directory at /tmp/blockmgr-e5479834-d1e4-48fa-9f5c-cbeb65531c31
2019-07-08 14:01:27,763 INFO memory.MemoryStore: MemoryStore started with capacity 90.3 MB
2019-07-08 14:01:28,062 INFO spark.SparkEnv: Registering OutputCommitCoordinator
2019-07-08 14:01:28,556 INFO util.log: Logging initialized @10419ms
2019-07-08 14:01:28,830 INFO server.Server: jetty-9.3.z-SNAPSHOT, build timestamp: unknown, git hash: unknown
2019-07-08 14:01:28,903 INFO server.Server: Started @10770ms
2019-07-08 14:01:28,997 INFO server.AbstractConnector: Started ServerConnector@89f072{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2019-07-08 14:01:28,997 INFO util.Utils: Successfully started service 'SparkUI' on port 4040.
2019-07-08 14:01:29,135 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1b325b3{/jobs,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,137 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@b72664{/jobs/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,140 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@34b7b8{/jobs/job,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,144 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1e8821f{/jobs/job/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,147 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@b31700{/stages,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,150 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@165e559{/stages/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,153 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1ae47a0{/stages/stage,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,158 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@5a54d{/stages/stage/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,161 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1ef722a{/stages/pool,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,165 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1d9b663{/stages/pool/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,168 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@14894fc{/storage,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,179 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@567255{/storage/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,186 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@362c57{/storage/rdd,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,191 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@4ee95c{/storage/rdd/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,195 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1c4715d{/environment,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,200 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@a360ea{/environment/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,204 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@148bb7d{/executors,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,209 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@27ba81{/executors/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,214 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@336c81{/executors/threadDump,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,217 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@156f2dd{/executors/threadDump/json,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,260 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1e52059{/static,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,265 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@159e366{/,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,283 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@1dc9128{/api,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,288 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@c4944a{/jobs/job/kill,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,292 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@772895{/stages/stage/kill,null,AVAILABLE,@Spark}
2019-07-08 14:01:29,304 INFO ui.SparkUI: Bound SparkUI to 0.0.0.0, and started at http://pi1:4040
2019-07-08 14:01:29,452 INFO spark.SparkContext: Added JAR file:/opt/spark/examples/jars/spark-examples_2.11-2.4.3.jar at spark://pi1:46027/jars/spark-examples_2.11-2.4.3.jar with timestamp 1562590889451
2019-07-08 14:01:33,070 INFO client.RMProxy: Connecting to ResourceManager at pi1/192.168.0.101:8032
2019-07-08 14:01:33,840 INFO yarn.Client: Requesting a new application from cluster with 7 NodeManagers
2019-07-08 14:01:34,082 INFO yarn.Client: Verifying our application has not requested more than the maximum memory capability of the cluster (900 MB per container)
2019-07-08 14:01:34,086 INFO yarn.Client: Will allocate AM container, with 740 MB memory including 384 MB overhead
2019-07-08 14:01:34,089 INFO yarn.Client: Setting up container launch context for our AM
2019-07-08 14:01:34,101 INFO yarn.Client: Setting up the launch environment for our AM container
2019-07-08 14:01:34,164 INFO yarn.Client: Preparing resources for our AM container
2019-07-08 14:01:35,577 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
2019-07-08 14:02:51,027 INFO yarn.Client: Uploading resource file:/tmp/spark-ca0b9022-2ba9-45ff-8d63-50545ef98e55/__spark_libs__7928629488171799934.zip -> hdfs://pi1:9000/user/pi/.sparkStaging/application_1562589758436_0002/__spark_libs__7928629488171799934.zip
2019-07-08 14:04:09,654 INFO yarn.Client: Uploading resource file:/tmp/spark-ca0b9022-2ba9-45ff-8d63-50545ef98e55/__spark_conf__4579290782490197871.zip -> hdfs://pi1:9000/user/pi/.sparkStaging/application_1562589758436_0002/__spark_conf__.zip
2019-07-08 14:04:13,226 INFO spark.SecurityManager: Changing view acls to: pi
2019-07-08 14:04:13,227 INFO spark.SecurityManager: Changing modify acls to: pi
2019-07-08 14:04:13,227 INFO spark.SecurityManager: Changing view acls groups to:
2019-07-08 14:04:13,228 INFO spark.SecurityManager: Changing modify acls groups to:
2019-07-08 14:04:13,228 INFO spark.SecurityManager: SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(pi); groups with view permissions: Set(); users with modify permissions: Set(pi); groups with modify permissions: Set()
2019-07-08 14:04:20,235 INFO yarn.Client: Submitting application application_1562589758436_0002 to ResourceManager
2019-07-08 14:04:20,558 INFO impl.YarnClientImpl: Submitted application application_1562589758436_0002
2019-07-08 14:04:20,577 INFO cluster.SchedulerExtensionServices: Starting Yarn extension services with app application_1562589758436_0002 and attemptId None
2019-07-08 14:04:21,625 INFO yarn.Client: Application report for application_1562589758436_0002 (state: ACCEPTED)
2019-07-08 14:04:21,680 INFO yarn.Client:
client token: N/A
diagnostics: [Mon Jul 08 14:04:20 +0100 2019] Scheduler has assigned a container for AM, waiting for AM container to be launched
ApplicationMaster host: N/A
ApplicationMaster RPC port: -1
queue: default
start time: 1562591060331
final status: UNDEFINED
tracking URL: http://pi1:8088/proxy/application_1562589758436_0002/
user: pi
2019-07-08 14:04:22,696 INFO yarn.Client: Application report for application_1562589758436_0002 (state: ACCEPTED)
2019-07-08 14:04:23,711 INFO yarn.Client: Application report for application_1562589758436_0002 (state: ACCEPTED)
2019-07-08 14:04:24,725 INFO yarn.Client: Application report for application_1562589758436_0002 (state: ACCEPTED)
...
2019-07-08 14:05:45,863 INFO yarn.Client: Application report for application_1562589758436_0002 (state: ACCEPTED)
2019-07-08 14:05:46,875 INFO yarn.Client: Application report for application_1562589758436_0002 (state: ACCEPTED)
2019-07-08 14:05:47,883 INFO yarn.Client: Application report for application_1562589758436_0002 (state: RUNNING)
2019-07-08 14:05:47,884 INFO yarn.Client:
client token: N/A
diagnostics: N/A
ApplicationMaster host: 192.168.0.103
ApplicationMaster RPC port: -1
queue: default
start time: 1562591060331
final status: UNDEFINED
tracking URL: http://pi1:8088/proxy/application_1562589758436_0002/
user: pi
2019-07-08 14:05:47,891 INFO cluster.YarnClientSchedulerBackend: Application application_1562589758436_0002 has started running.
2019-07-08 14:05:47,937 INFO util.Utils: Successfully started service 'org.apache.spark.network.netty.NettyBlockTransferService' on port 46437.
2019-07-08 14:05:47,941 INFO netty.NettyBlockTransferService: Server created on pi1:46437
2019-07-08 14:05:47,955 INFO storage.BlockManager: Using org.apache.spark.storage.RandomBlockReplicationPolicy for block replication policy
2019-07-08 14:05:48,178 INFO storage.BlockManagerMaster: Registering BlockManager BlockManagerId(driver, pi1, 46437, None)
2019-07-08 14:05:48,214 INFO storage.BlockManagerMasterEndpoint: Registering block manager pi1:46437 with 90.3 MB RAM, BlockManagerId(driver, pi1, 46437, None)
2019-07-08 14:05:48,265 INFO storage.BlockManagerMaster: Registered BlockManager BlockManagerId(driver, pi1, 46437, None)
2019-07-08 14:05:48,269 INFO storage.BlockManager: Initialized BlockManager: BlockManagerId(driver, pi1, 46437, None)
2019-07-08 14:05:49,426 INFO cluster.YarnClientSchedulerBackend: Add WebUI Filter. org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter, Map(PROXY_HOSTS -> pi1, PROXY_URI_BASES -> http://pi1:8088/proxy/application_1562589758436_0002), /proxy/application_1562589758436_0002
2019-07-08 14:05:49,441 INFO ui.JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /jobs, /jobs/json, /jobs/job, /jobs/job/json, /stages, /stages/json, /stages/stage, /stages/stage/json, /stages/pool, /stages/pool/json, /storage, /storage/json, /storage/rdd, /storage/rdd/json, /environment, /environment/json, /executors, /executors/json, /executors/threadDump, /executors/threadDump/json, /static, /, /api, /jobs/job/kill, /stages/stage/kill.
2019-07-08 14:05:49,816 INFO ui.JettyUtils: Adding filter org.apache.hadoop.yarn.server.webproxy.amfilter.AmIpFilter to /metrics/json.
2019-07-08 14:05:49,829 INFO handler.ContextHandler: Started o.s.j.s.ServletContextHandler@136bd1{/metrics/json,null,AVAILABLE,@Spark}
2019-07-08 14:05:49,935 INFO cluster.YarnClientSchedulerBackend: SchedulerBackend is ready for scheduling beginning after waiting maxRegisteredResourcesWaitingTime: 30000(ms)
2019-07-08 14:05:50,076 INFO cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: ApplicationMaster registered as NettyRpcEndpointRef(spark-client://YarnAM)
2019-07-08 14:05:52,074 INFO spark.SparkContext: Starting job: reduce at SparkPi.scala:38
2019-07-08 14:05:52,479 INFO scheduler.DAGScheduler: Got job 0 (reduce at SparkPi.scala:38) with 7 output partitions
2019-07-08 14:05:52,481 INFO scheduler.DAGScheduler: Final stage: ResultStage 0 (reduce at SparkPi.scala:38)
2019-07-08 14:05:52,485 INFO scheduler.DAGScheduler: Parents of final stage: List()
2019-07-08 14:05:52,492 INFO scheduler.DAGScheduler: Missing parents: List()
2019-07-08 14:05:52,596 INFO scheduler.DAGScheduler: Submitting ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34), which has no missing parents
2019-07-08 14:05:53,314 WARN util.SizeEstimator: Failed to check whether UseCompressedOops is set; assuming yes
2019-07-08 14:05:53,404 INFO memory.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 1936.0 B, free 90.3 MB)
2019-07-08 14:05:53,607 INFO memory.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 1256.0 B, free 90.3 MB)
2019-07-08 14:05:53,625 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on pi1:46437 (size: 1256.0 B, free: 90.3 MB)
2019-07-08 14:05:53,639 INFO spark.SparkContext: Created broadcast 0 from broadcast at DAGScheduler.scala:1161
2019-07-08 14:05:53,793 INFO scheduler.DAGScheduler: Submitting 7 missing tasks from ResultStage 0 (MapPartitionsRDD[1] at map at SparkPi.scala:34) (first 15 tasks are for partitions Vector(0, 1, 2, 3, 4, 5, 6))
2019-07-08 14:05:53,801 INFO cluster.YarnScheduler: Adding task set 0.0 with 7 tasks
2019-07-08 14:06:08,910 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2019-07-08 14:06:23,907 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2019-07-08 14:06:38,907 WARN cluster.YarnScheduler: Initial job has not accepted any resources; check your cluster UI to ensure that workers are registered and have sufficient resources
2019-07-08 14:06:47,677 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Registered executor NettyRpcEndpointRef(spark-client://Executor) (192.168.0.106:44936) with ID 1
2019-07-08 14:06:48,266 INFO storage.BlockManagerMasterEndpoint: Registering block manager pi6:39443 with 90.3 MB RAM, BlockManagerId(1, pi6, 39443, None)
2019-07-08 14:06:48,361 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, pi6, executor 1, partition 0, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:48,371 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, pi6, executor 1, partition 1, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:48,375 INFO scheduler.TaskSetManager: Starting task 2.0 in stage 0.0 (TID 2, pi6, executor 1, partition 2, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:48,379 INFO scheduler.TaskSetManager: Starting task 3.0 in stage 0.0 (TID 3, pi6, executor 1, partition 3, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:50,877 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on pi6:39443 (size: 1256.0 B, free: 90.3 MB)
2019-07-08 14:06:52,001 INFO scheduler.TaskSetManager: Starting task 4.0 in stage 0.0 (TID 4, pi6, executor 1, partition 4, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:52,024 INFO scheduler.TaskSetManager: Starting task 5.0 in stage 0.0 (TID 5, pi6, executor 1, partition 5, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:52,039 INFO scheduler.TaskSetManager: Starting task 6.0 in stage 0.0 (TID 6, pi6, executor 1, partition 6, PROCESS_LOCAL, 7877 bytes)
2019-07-08 14:06:52,115 INFO scheduler.TaskSetManager: Finished task 2.0 in stage 0.0 (TID 2) in 3733 ms on pi6 (executor 1) (1/7)
2019-07-08 14:06:52,143 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 3891 ms on pi6 (executor 1) (2/7)
2019-07-08 14:06:52,144 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 3776 ms on pi6 (executor 1) (3/7)
2019-07-08 14:06:52,156 INFO scheduler.TaskSetManager: Finished task 3.0 in stage 0.0 (TID 3) in 3780 ms on pi6 (executor 1) (4/7)
2019-07-08 14:06:52,217 INFO scheduler.TaskSetManager: Finished task 4.0 in stage 0.0 (TID 4) in 222 ms on pi6 (executor 1) (5/7)
2019-07-08 14:06:52,249 INFO scheduler.TaskSetManager: Finished task 6.0 in stage 0.0 (TID 6) in 215 ms on pi6 (executor 1) (6/7)
2019-07-08 14:06:52,262 INFO scheduler.TaskSetManager: Finished task 5.0 in stage 0.0 (TID 5) in 247 ms on pi6 (executor 1) (7/7)
2019-07-08 14:06:52,270 INFO cluster.YarnScheduler: Removed TaskSet 0.0, whose tasks have all completed, from pool
2019-07-08 14:06:52,288 INFO scheduler.DAGScheduler: ResultStage 0 (reduce at SparkPi.scala:38) finished in 59.521 s
2019-07-08 14:06:52,323 INFO scheduler.DAGScheduler: Job 0 finished: reduce at SparkPi.scala:38, took 60.246659 s
Pi is roughly 3.1389587699411
2019-07-08 14:06:52,419 INFO server.AbstractConnector: Stopped Spark@89f072{HTTP/1.1,[http/1.1]}{0.0.0.0:4040}
2019-07-08 14:06:52,432 INFO ui.SparkUI: Stopped Spark web UI at http://pi1:4040
2019-07-08 14:06:52,473 INFO cluster.YarnClientSchedulerBackend: Interrupting monitor thread
2019-07-08 14:06:52,602 INFO cluster.YarnClientSchedulerBackend: Shutting down all executors
2019-07-08 14:06:52,605 INFO cluster.YarnSchedulerBackend$YarnDriverEndpoint: Asking each executor to shut down
2019-07-08 14:06:52,640 INFO cluster.SchedulerExtensionServices: Stopping SchedulerExtensionServices
(serviceOption=None,
services=List(),
started=false)
2019-07-08 14:06:52,649 INFO cluster.YarnClientSchedulerBackend: Stopped
2019-07-08 14:06:52,692 INFO spark.MapOutputTrackerMasterEndpoint: MapOutputTrackerMasterEndpoint stopped!
2019-07-08 14:06:52,766 INFO memory.MemoryStore: MemoryStore cleared
2019-07-08 14:06:52,769 INFO storage.BlockManager: BlockManager stopped
2019-07-08 14:06:52,825 INFO storage.BlockManagerMaster: BlockManagerMaster stopped
2019-07-08 14:06:52,851 INFO scheduler.OutputCommitCoordinator$OutputCommitCoordinatorEndpoint: OutputCommitCoordinator stopped!
2019-07-08 14:06:52,902 INFO spark.SparkContext: Successfully stopped SparkContext
2019-07-08 14:06:52,927 INFO util.ShutdownHookManager: Shutdown hook called
2019-07-08 14:06:52,935 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-1d1b5b79-679d-4ffe-b8aa-7e84e6be10f2
2019-07-08 14:06:52,957 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-ca0b9022-2ba9-45ff-8d63-50545ef98e55
如果您仔细检查上述命令的输出,您会看到下一个结果是:
took 60.246659 s
Pi is roughly 3.1389587699411
我最后建议你做的是,如果你已经定义了 and函数,那么就stop-dfs.sh添加它们。你应该在关闭所有机器之前关闭 Hadoop 集群,然后在机器重启后重启集群:stop-yarn.shclusterrebootclustershutdown
function clusterreboot {
stop-yarn.sh && stop-dfs.sh && \
clustercmd sudo shutdown -r now
}
function clustershutdown {
stop-yarn.sh && stop-dfs.sh && \
clustercmd sudo shutdown now
}
结论
就这样!希望本指南能够对您有所帮助,无论您是想设置 Raspberry Pi、构建自己的 Hadoop 和 Spark 集群,还是只想了解一些大数据技术。如果您发现本指南有任何问题,请告知我;我很乐意对其进行修改或使其更加清晰。
如果您想了解更多关于在 HDFS 上运行的命令或如何向 Spark 提交作业的信息,请点击相关链接。感谢您看到最后!
如果你喜欢这类内容,请务必在 Twitter和Dev.To 上关注我。我发布的内容涵盖 Java、Hadoop、Spark、R 等。
鏂囩珷鏉ユ簮锛�https://dev.to/awwsmm/building-a-raspberry-pi-hadoop-spark-cluster-8b2