🤖 OpenAI GPT 4.5 与 Claude 3.7 Sonnet 编码对比 🚀
据说 Claude 3.7 完全碾压了我们最新、最昂贵的 OpenAI 模型 GPT-4.5。不过,除非我亲自测试,否则我不会相信这些基准测试。

因此,我对三个 Web 开发编码问题进行了自己的测试。
让我们看看这两个模型在编码方面如何相互比较。🤨
TL;DR
如果你想直接看结果,Claude 3.7 Sonnet 在编码方面优于 GPT-4.5。GPT-4.5甚至比 Claude 3.7 Sonnet 的成本高出 10 倍,但仍然远远落后(有点糟糕! )。
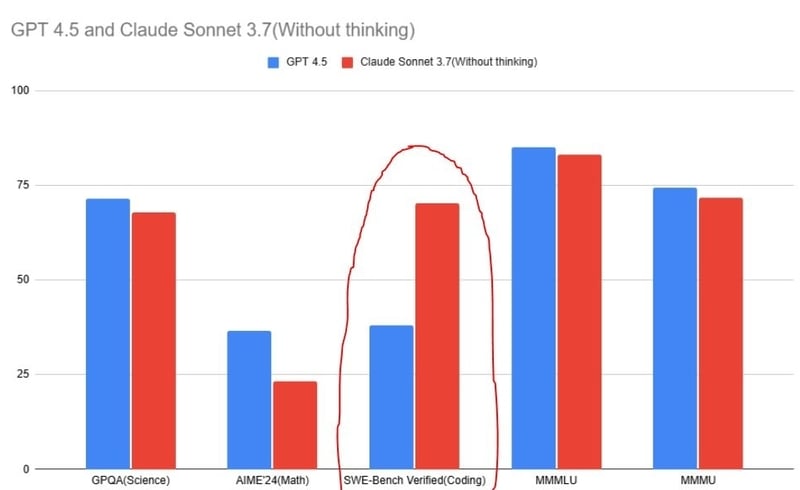
是的,这很公平。Claude 3.7 Sonnet 专为编码而构建,而 GPT-4.5 主要用于写作和设计。
我最近发布了一篇关于 Claude 3.7、Grok 3 和 OpenAI o3-mini-high 的代码对比文章。如果你对 Claude 3.7 的表现感兴趣,可以去看看。👇

GPT-4.5 模型简介
OpenAI 周四发布了 GPT-4.5 的早期版本,这是其旗舰大型语言模型的新版本。该团队声称这是“最大、最好的模型”,其使用体验就像与本地人交谈一样。

不,这不是一个推理模型,正如 OpenAI 首席执行官Sam Altman本人所说。
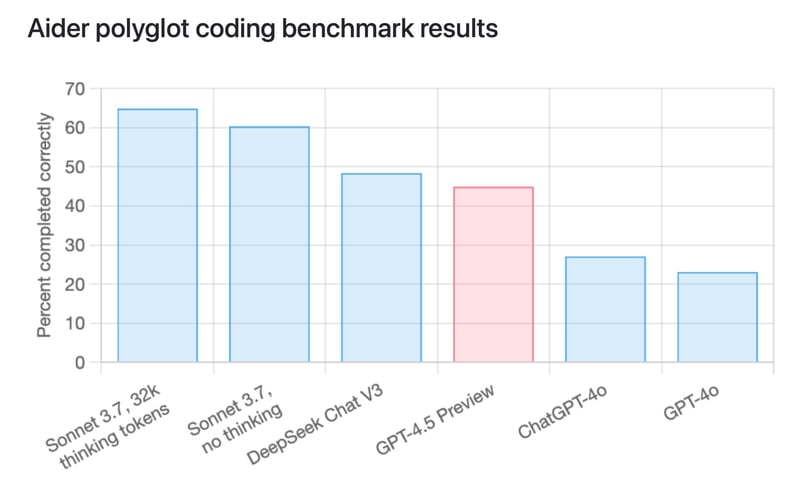
这似乎是正确的,因为与Claude 3.7 Sonnet和早期的GPT-4o编码模型等其他模型相比,其准确率百分比似乎明显较低。
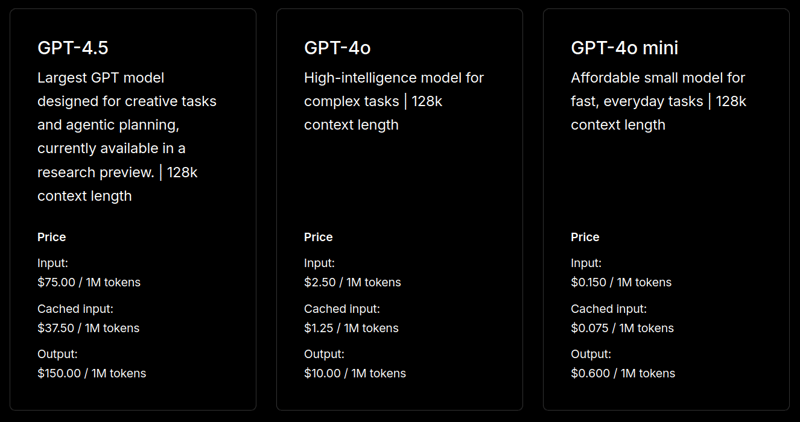
说到定价,这是 OpenAI 最昂贵的 AI 模型,每百万输入令牌 75 美元,每百万输出令牌 150 美元。😮💨您可以将此模型的定价与他们的一些早期模型并排比较:
目前,每月支付 200 美元的 ChatGPT Pro 账户用户即可试用 GPT-4.5。OpenAI 表示,该功能将于下周开始向 Plus 用户推出。
OpenAI 没有透露其新模型的规模,但他们提到,从 GPT-4o 到 GPT-4.5 的规模增长与从 GPT-3.5 到 GPT-4o 的跳跃相似。
是什么让它如此昂贵?
与o1和o3-mini等其他推理模型逐步得出答案不同,像GPT-4.5这样的普通大型语言模型会直接给出它们得出的第一个答案。

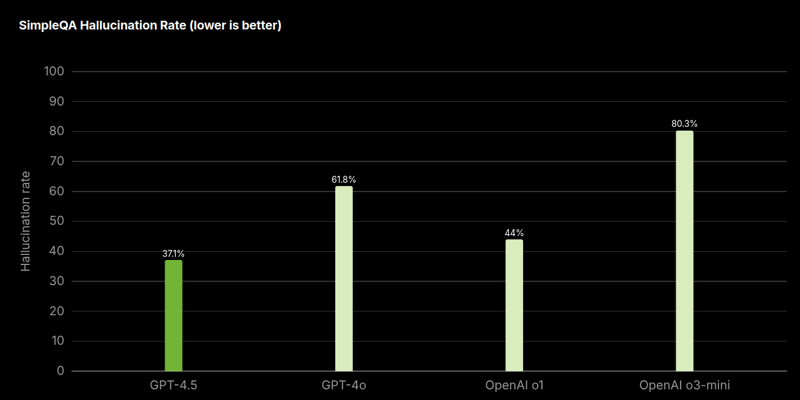
在 OpenAI 去年开发的一项名为SimpleQA的常识性测验中,该测验涵盖了所有内容的问题,GPT-4o 等模型的得分为 38.2%,o3-mini 的得分为 15%,而 GPT-4.5 的得分则高达 62.5%。🤯
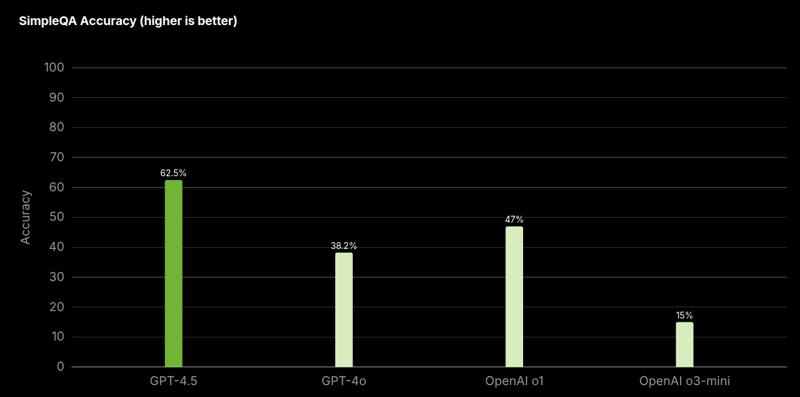
OpenAI 声称 GPT-4.5 给出的虚构答案要少得多,这在人工智能术语中也称为幻觉。
除此之外,它还增强了背景知识和写作技巧,这也是该模型的输出听起来更自然、更少不必要推理的主要原因。
在进行的同一项测试中,GPT-4.5 模型给出虚构答案的概率为 37.1%,而 GPT-4o 和 o3-mini 分别为 61.8% 和 80.3%。
编码比较
💁 正如我之前所说,我们将主要在前端问题上比较这两种模型。
1. 砌体网格图片库
提示:构建一个 Next.js 图片库,其中包含砌体网格、无限滚动和用于按关键词筛选图片的搜索栏。将其设计得像 Unsplash 一样,拥有简洁、现代的 UI。优化图片加载。所有代码都放在 中
page.tsx。
克劳德的回应 3.7 十四行诗
您可以在此处找到它生成的代码:链接
这是程序的输出:
Claude 的作品简直是疯狂。一切都完美地实现了。
我只注意到一个小问题,那就是页脚没有粘在底部。
GPT-4.5 的回应
您可以在此处找到它生成的代码:链接
这是程序的输出:
GPT-4.5 的输出与我预期的并不相符。我的意思是,它没有使用任何类似的 npm 模块,这有点聪明@tanstack/react-query,但显然缺少了 Masonry Grid 布局,而且无限滚动的实现方式感觉更像DIY 风格。
不能抱怨太多,但它与 Claude 3.7 生成的代码相差甚远。
最终结论:毫无疑问,Claude 3.7 Sonnet 的输出要出色得多。✅ 它正确地实现了所有内容,从 Masonry Grid 布局到使用@tanstack/react-query库实现的完美无限滚动。GPT-4.5 的输出仍然有很多不足之处。
2.打字速度测试
让我们测试一下这两个模型,让它们构建一个类似 Monkeytype 的打字速度测试应用。而且,我还可以测试一下我的打字速度。😉(开个玩笑)
提示:构建一个 Next.js 基础打字测试应用。用户输入一个给定的句子,错误会以红色高亮显示,以便用户修改。应用会实时显示打字速度,包括原始速度(包含错误)和调整后速度(无错误)。用户输入到最后,测试就应该结束了。所有代码请参考
page.tsx。
克劳德的回应 3.7 十四行诗
您可以在此处找到它生成的代码:链接
这是程序的输出:
哇哦,用这个模型来写代码感觉有点不合法。这有多好?我都不知道该说什么了。🤯
很快,一切都正确实现了,它就构建了整个打字测试网站,功能远超我的预期。它甚至还添加了准确率显示。
GPT-4.5 的回应
您可以在此处找到它生成的代码:链接
这是程序的输出:
GPT-4.5 也正确完成了这一点,但它生成的代码有一个小问题。一旦用户到达终点,测试就应该结束,但除非用户返回并修复它,否则测试不会结束。
最终结论: GPT-4.5 生成的代码响应存在一个小问题,但公平地说,两个模型都正确无误。✅
3. 协作实时白板
💁 这个比较难,我不确定 Claude 3.7 是否也能解决这个问题。它需要设置一个单独的 Web 套接字服务器并监听连接。
提示:使用 Next.js 构建一个实时协作白板,并使用 Tailwind 进行样式设置。多个用户应该能够即时绘制并查看更新。但是,当一个用户清除其画布时,其他用户的画布不应被清除。
克劳德的回应 3.7 十四行诗
您可以在此处找到它生成的代码:链接
这是程序的输出:
好的,现在我看到一些初级开发人员很快就会被人工智能取代。🤐
对我来说,编写代码要花很长时间。现在我开始明白为什么这个模型在编码方面被称为“野兽”了。简直完美!
GPT-4.5 的回应
您可以在此处找到它生成的代码:链接
这是程序的输出:
GPT-4.5 在这里严重失败。WebSocket 连接已建立,但在客户端解析从 WebSocket 连接接收的数据时出现问题。
最终结论: Claude 3.7 Sonnet 在这方面也完胜。🔥 它生成的代码非常完美,输出也正是我想要的。GPT-4.5 能够建立 WebSocket 连接,但在解析数据时遇到了问题。即使我尝试迭代它的错误,它也无法真正修复它。
概括
你应该很清楚这里的结果了。😮💨 Claude 3.7 以巨大的优势获胜,嘿,我再次强调,这种比较对 GPT-4.5 来说并不公平,因为它没有接受过编程方面的训练。但至少它解决了前两个问题,尽管它并不完美。
何时使用 GPT-4.5 模型?
现在我们已经大致了解了该模型的功能,让我们来看看在哪些情况下您会更喜欢该模型。🤔
总而言之,GPT-4.5 并非一个可以依赖的推理任务模型。GPT-4.5 对人类意图的理解更深入,能够解读细微的线索。它旨在提升对话、设计和写作能力,并增添一丝人情味。
当您需要一个非常具体的编写或设计的用例时,此模型是理想的选择。

那么,它值这个价钱吗?如果一定要说,绝对不值。不过,它值不值得,还是得看你自己的感受。🤷♂️
对于其他任何事情,它都不能完全证明其定价合理,并且可能不是最好的选择。
结论
结果一目了然,而且这并不是说这个比较不公平。这就像我们把一个经验丰富的开发人员和一个甚至不是程序员的人进行比较一样。🥴
但是,进行比较是为了看看 GPT-4.5 在编码方面与 Claude 3.7 Sonnet 的可比性。
不仅仅是这次比较,在我所做的所有比较中,不用说,即使我们使用的是无思考的Claude 3.7 Sonnet,它也更好,而且是目前编码时唯一需要的模型。🔥
你觉得这个对比怎么样?如果你想让我比较一下其他型号,请在评论区留言!👇
文章来源:https://dev.to/composiodev/comparing-openai-gpt-45-and-claude-37-sonnet-on-coding-dj5