使用 Apache Airflow 管理数据管道

如今,几乎每个数据密集型 Python 团队都在以某种方式使用 Airflow。了解 Airflow 的界面应该不难理解其中的原因:Airflow 正是数据工程师标准化 ETL 管道创建所需的关键工具。当然,Airflow 最棒的地方在于,它是少数捐赠给 Apache 基金会的 Python 项目之一。太棒了!
如果你恰好是一位数据工程师,但还没有使用过 Airflow(或类似工具),那么你可要好好学习一下了。用不了多久,你就会开始琢磨,如果没有它,自己该如何应对。
气流的意义是什么?
Airflow 为管道业务人员提供了无数好处。将这些好处归结为两大类并不夸张:代码质量和可见性。
Airflow 作为一种创建管道的“框架”,为我们提供了一种构建数据管道的更好方法。正如 Web 框架可以通过抽象通用模式来帮助开发人员一样,Airflow 也通过为数据工程师提供工具来简化管道创建过程中某些重复性的工作。Airflow 集成了众多强大的功能,几乎可以满足任何数据输出需求。通过利用这些工具,工程师们开始看到他们的管道遵循易于理解的格式,从而使代码易于其他人阅读。
Airflow 最显著的优势在于其强大的 GUI。管理多个容易出错的管道可能是任何数据工程师工作中最不光彩的部分。通过在 Airflow 中创建管道,我们可以立即查看所有管道,从而快速发现故障区域。更令人印象深刻的是,我们编写的代码在 Airflow 的 GUI 中以可视化的方式呈现。我们不仅可以检查管道的运行状态,还可以查看我们编写的代码的图形化表示。
要开始使用 Airflow,我们应该停止使用“管道”这个词。相反,我们应该习惯使用DAG这个词。

什么是 DAG?
Airflow 将我们一直称之为“管道”的东西称为DAG(有向无环图)。在计算机科学中,有向无环图仅仅指单向流动的工作流。工作流中的每个“步骤”(一条边)都通过前一步到达,直到到达起点。边的连接称为顶点。
如果这仍然不清楚,请思考一下树形数据结构中节点之间的关系。每个节点都有一个“父”节点,这当然意味着子节点不能是其父节点的父节点。就是这样——这里不需要华丽的辞藻。
DAG 中的边可以有多个“子”边。有趣的是,一个“子”边也可以有多个父边(这就是我们树的类比失效的地方)。以下是一个例子:

在上面的例子中,DAG 从边 1、2 和 3 开始。在管道的各个点上,信息被合并或分解。最终,DAG 以边 8 结束。
我们将深入研究 DAG,但首先,让我们安装 Airflow。
安装 Airflow
安装 Apache 的数据服务通常体验糟糕透顶。大多数情况下,一开始你会被要求创建 Oracle 账户(拜托,杀了我吧),然后安装某个特定版本的 Java。创建 Oracle 账户后,你通常需要安装和配置三四个不同的 Apache 服务,而且这些服务的名字都带着一股令人讨厌的动物味。
设置 Airflow 非常简单。要开始 Airflow 的基本设置,我们只需要安装apache-airflow Python 库:
$ pip3 install apache-airflow
单独安装 Airflow 可以用于测试,但为了构建一些有意义的东西,我们需要安装 Airflow 众多“额外功能”之一。我们安装的每个 Airflow “功能”都支持 Airflow 与服务(最常见的是数据库)之间的内置集成。Airflow默认安装 SQLLite功能。
Airflow 需要一个数据库来创建运行 Airflow 所需的表。在生产环境中使用 Airflow 时,我们很可能不会使用本地 SQLLite 数据库,因此我选择使用 Postgres 数据库:
$ pip3 install apache-airflow[postgres]
$ pip3 install psycopg2-binary
Airflow 利用我们熟悉的 SQLAlchemy 库来处理数据库连接。因此,设置数据库连接字符串的操作应该很熟悉。
Airflow 的功能远不止数据库。它可以安装 Redis、Slack、HDFS、RabbitMQ 等等。要查看所有可用功能,请查看列表:https://airflow.apache.org/installation.html
基本气流配置
在执行任何操作之前,我们需要设置一个名为 的重要环境变量AIRFLOW_HOME。启动 Airflow 时,它会查找与该变量值匹配的文件夹。然后,它会将运行 Airflow 所需的一些核心文件解压到该文件夹中:
AIRFLOW_HOME=./airflow
接下来,我们需要将 Airflow 配置文件解压到/airflow目录下。只需运行以下命令即可:
$ airflow initdb
一堆新文件应该会神奇地出现在你的 / airflow目录中,如下所示:
/
├── /airflow
│ ├── airflow.cfg
│ ├── airflow.db
│ ├── /logs
│ │ └── /scheduler
│ │ ├── 2019-06-01
│ │ └── latest -> airflow/logs/scheduler/2019-06-01
│ └── unittests.cfg
└── requirements.txt
首次运行initdb默认会创建一个指向本地 SQLLite 数据库的 Airflow 实例。首次运行后,我们可以将新的./airflow/airflow.cfg文件中的变量更改为指向 Postgres 数据库(或您选择的数据库)。
数据库配置
要将 Airflow 连接到实时数据库,我们需要修改airflow.cfg中的几个设置。找到sql_alchemy_conn变量并粘贴你所选数据库的 SQLAlchemy 连接字符串。如果你使用的是 Postgres,也不要忘记进行sql_alchemy_schema以下设置:
sql_alchemy_conn = postgresql+psycopg2://[username]:[password]@[host]:[post]/[database]
sql_alchemy_schema = public
完成这些更改后,再次初始化数据库:
$ airflow initdb
这一次,Airflow 应该会用运行应用程序所需的一些表来初始化你提供的数据库。我决定亲自查看一下我的数据库:
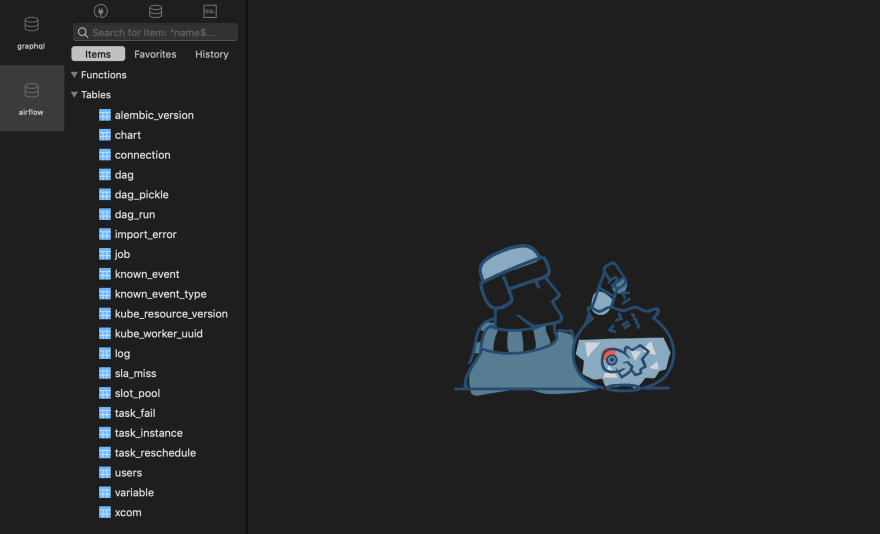
启动 Airflow
配置完所有配置后,运行以下命令在端口 8080 启动 Airflow:
$ airflow webserver -p 8080
输出应该类似于以下内容:
_________________________
____|__ ( ) ___________ / __/________ __
____/| |_ /__ ___/_ /___ /_ __ \_ | /| / /
______ | / _ / _ __/ _ / / /_/ /_ |/ |/ /
_/_/ |_/_/ /_/ /_/ /_/ \ ____/____ /|__/
[2019-06-01 04:38:27,785] { __init__.py:305} INFO - Filling up the DagBag from airflow/dags
Running the Gunicorn Server with:
Workers: 4 sync
Host: 0.0.0.0:8080
Timeout: 120
Logfiles: - -
=================================================================
现在让我们看看localhost:8080发生了什么:
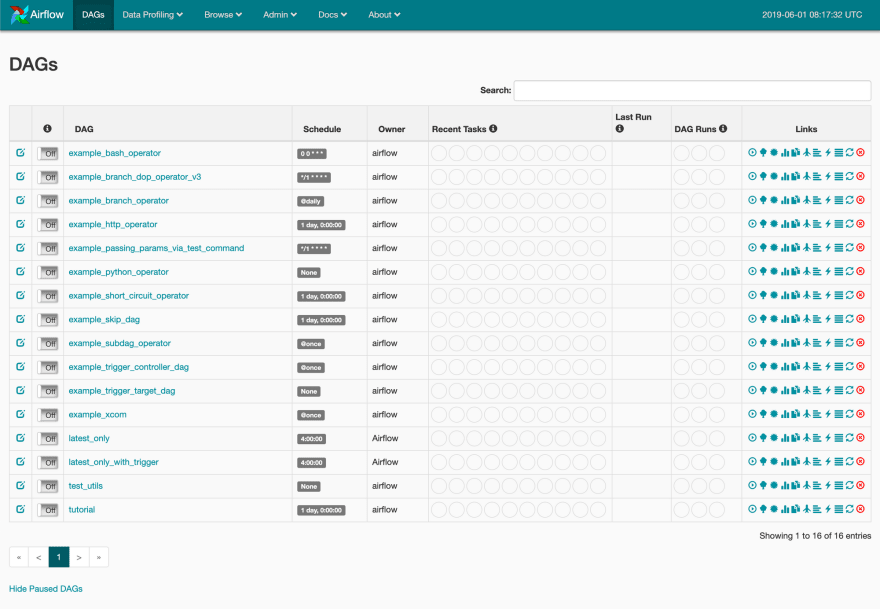
太棒了!Airflow 很贴心地创建了一堆 DAG 示例供我们参考。这些示例对于我们熟悉它来说是一个很好的起点。
在我们变得太疯狂之前,让我们分解一下上面屏幕的元素:
- DAG:DAG 作业的名称。
- 计划:运行当前 DAG 的重复 CRON 计划。
- 所有者:Airflow 实例中拥有该作业的用户的姓名。
- 最近的任务:此作业最近 10 次运行的可视状态(通过/失败/运行)。
- 上次运行:DAG 上次运行的时间。
- DAG 运行:DAG 执行的总次数。
有机会的话,请随意点击并破坏一些东西。
Airflow DAG 的剖析
任何管道本质上都只是一系列任务,DAG 也不例外。在 DAG 中,我们的“任务”由运算符定义。
让我们退一步来看:DAG 是我们的工作流,而 DAG 中的任务是该工作流执行的操作。“操作符”指的是任务所属的操作类型,例如数据库操作或脚本操作。不难想象,一个 DAG 中可能包含多个与数据库相关的操作:在这种情况下,我们会使用同一个操作符来定义多个任务(PostgresOperator假设我们处理的是 Postgres)。
以下是一些不同类型的运算符:
BashOperator:执行 bash 命令。PythonOperator:调用 Python 函数。EmailOperator:发送电子邮件。SimpleHttpOperator:生成 HTTP 请求。MySqlOperator,,SqliteOperator:PostgresOperator执行 SQL 命令。DummyOperator:不执行任何操作的操作员(主要用于测试目的)。
还有:
DingdingOperator:向“钉钉”阿里巴巴消息服务发送消息。我也不知道这是啥。- Google Cloud 运算符:Google 云服务拥有大量特定运算符,例如 Bigtable 运算符、Compute Engine 运算符、Cloud Function 运算符等。
- 传感器:等待事件发生后再继续前进(可以等待时间流逝、等待脚本完成等)。
操作符可以在 DAG 中的任何点发生。我们可以在单个 DAG 的整个生命周期内的任何点触发多个操作符。
DAG 示例
让我们探索一下 Airflow 提供的一些 DAG 示例。example_python_operator 是一个很好的起点:

在这里,我正在检查DAG 的图形视图选项卡:此视图最能表示从开始到结束发生的事情。
这看起来像是一个简单的 DAG:它只是启动了 5 个 Python 操作符来触发睡眠定时器,没有其他任何操作。点击菜单栏中的“触发 DAG”项来运行此 DAG,然后在你启动 Airflow 时使用的控制台中检查输出:
[2019-06-01 06:07:00,897] { __init__.py:305} INFO - Filling up the DagBag from /Users/toddbirchard/.local/share/virtualenvs/airflow-a3hcxs5D/lib/python3.7/site-packages/airflow/
example_dags/example_python_operator.py
127.0.0.1 - - [01/Jun/2019:06:07:01 -0400] "POST /admin/airflow/trigger?dag_id=example_python_operator&origin=%2Fadmin%2Fairflow%2Ftree%3Fdag_id%3Dexample_python_operator HTTP/
1.1" 302 307 "http://0.0.0.0:8080/admin/airflow/code?dag_id=example_python_operator" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chr
ome/74.0.3729.169 Safari/537.36"
127.0.0.1 - - [01/Jun/2019:06:07:01 -0400] "GET /admin/airflow/tree?dag_id=example_python_operator HTTP/1.1" 200 9598 "http://0.0.0.0:8080/admin/airflow/code?dag_id=example_pyt
hon_operator" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"
这实际上并没有告诉我们什么,但话又说回来……这不正是我们所期望的吗?毕竟,在“sleep”Python 运算符之后没有任何步骤发生,所以这里的“空”可能是成功的。
为了更好地理解,请查看代码选项卡。没错:我们可以直接从 GUI 查看任何 DAG 的源代码!
from __future__ import print_function
import time
from builtins import range
from pprint import pprint
import airflow
from airflow.models import DAG
from airflow.operators.python_operator import PythonOperator
args = {
'owner': 'airflow',
'start_date': airflow.utils.dates.days_ago(2),
}
dag = DAG(
dag_id='example_python_operator',
default_args=args,
schedule_interval=None,
)
# [START howto_operator_python]
def print_context(ds, **kwargs):
pprint(kwargs)
print(ds)
return 'Whatever you return gets printed in the logs'
run_this = PythonOperator(
task_id='print_the_context',
provide_context=True,
python_callable=print_context,
dag=dag,
)
# [END howto_operator_python]
# [START howto_operator_python_kwargs]
def my_sleeping_function(random_base):
"""This is a function that will run within the DAG execution"""
time.sleep(random_base)
# Generate 5 sleeping tasks, sleeping from 0.0 to 0.4 seconds respectively
for i in range(5):
task = PythonOperator(
task_id='sleep_for_' + str(i),
python_callable=my_sleeping_function,
op_kwargs={'random_base': float(i) / 10},
dag=dag,
)
run_this >> task
# [END howto_operator_python_kwargs]
每个 DAG 都以一些基本配置变量开始。args包含高级配置值:
owner:DAG 所属的 Airflow 用户(再次)。start_date:DAG 应该执行的时间。email:出现问题时用于发出警报通知的电子邮件地址。email_on_failure:当为True时,执行失败将向指定的电子邮件地址发送失败作业的详细信息。email_on_retry:当为True时,每次 DAG 尝试重试失败的执行时都会发送一封电子邮件。retries:发生故障时重试 DAG 的次数。retry_delay:重试之间的时间。concurrency:运行 DAG 的进程数。depends_on_past:如果为True,则此任务将依赖于前一个任务的成功后才执行。
设置完 DAG 的配置后,DAG 会通过 实例化dag = DAG()。创建时,我们会传入一些参数DAG()(例如之前设置的参数)。在这里,我们会设置 DAG 的名称和调度时间。
在 DAG 的图形视图中,我们看到了名为 的任务print_the_context,以及一系列遵循 之类的约定的任务sleep_for_#。在源代码中,我们可以准确地看到这些任务名称的定义位置!查看第一个任务:
# [START howto_operator_python]
def print_context(ds, **kwargs):
pprint(kwargs)
print(ds)
return 'Whatever you return gets printed in the logs'
run_this = PythonOperator(
task_id='print_the_context',
provide_context=True,
python_callable=print_context,
dag=dag,
)
第一个任务被设置PythonOperator()为 id print_the_context。它是一个打印一些信息并返回字符串的函数!
这是第二组任务:
def my_sleeping_function(random_base):
"""This is a function that will run within the DAG execution"""
time.sleep(random_base)
# Generate 5 sleeping tasks, sleeping from 0.0 to 0.4 seconds respectively
for i in range(5):
task = PythonOperator(
task_id='sleep_for_' + str(i),
python_callable=my_sleeping_function,
op_kwargs={'random_base': float(i) / 10},
dag=dag,
)
这太酷了:这次,Python 运算符出现在 for 循环中。这完美地演示了如何动态创建 DAG!
你觉得自己有能力创建自己的 DAG 吗?我想你也一样。让我们开始吧。
准备创建我们自己的 DAG
在继续下一步之前,我们需要先解决一些琐碎的事情。这不会花很长时间。
创建 Airflow 用户
正如我们已经看到的,DAG 需要有一个“所有者”。到目前为止,我们看到的默认 DAG 将其用户设置为Airflow。我们无法对我们创建的 DAG 执行此操作 - 我们需要设置一个合法用户。在 Airflow 用户界面中,导航至Admin > Users。
然后,创建一个将“拥有”我们的新 DAG 的用户。
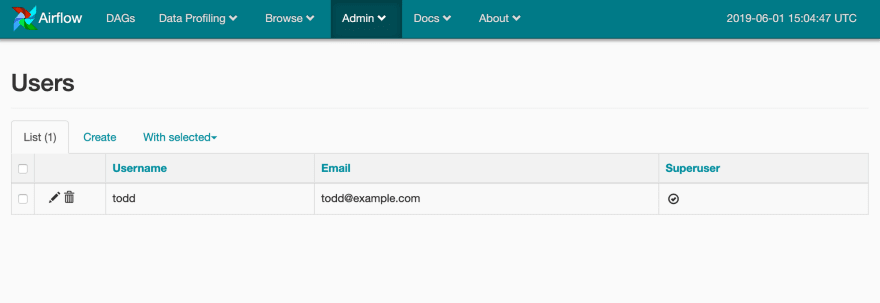
创建新连接
为了模拟真实场景,我们应该让 DAG 将信息插入数据库。DAG 输出的目标需要在 Airflow UI 的Admin > Connections下创建和管理。
我已经开始设置下面的 Postgres 连接:

创建我们的第一个 DAG
关闭你的 Web 服务器,并在/airflow 目录下创建一个名为/dags 的文件夹。我们将在这里存储后续创建的 DAG 的源代码(你的 DAG 的位置可以在 中更改airflow.cfg,但/dags是默认位置)。在/dags 目录下创建一个 Python 文件,文件名可以类似my_first_dag.py(说实话,文件名可以随意)。
我将创建一个由三个任务组成的 DAG。这些任务将使用Bash、Python和Postgres运算符:
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.operators.python_operator import PythonOperator
from airflow.operators.postgres_operator import PostgresOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'todd',
'depends_on_past': False,
'start_date': datetime(2015, 6, 1),
'email': ['todd@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(dag_id='my_custom_dag',
default_args=default_args,
schedule_interval=timedelta(days=1))
# Task 1
t1 = BashOperator(
task_id='print_date',
bash_command='date',
dag=dag)
# Task 2
def my_python_function():
now = datetime.now()
response = 'This function ran at ' + str(now)
return response
t2 = PythonOperator(
task_id='my_python_task',
python_callable=my_python_function,
params={'my_param': 'Parameter I passed in'},
dag=dag)
# Task 3
t3 = PostgresOperator(task_id='my_postgres_task',
sql="INSERT INTO test VALUES (3, 69, 'this is a test!');",
postgres_conn_id='my_postgres_instance',
autocommit=True,
database="airflow2",
dag=dag)
# Pipeline Structure
t2.set_upstream(t1)
t3.set_upstream(t2)
我特意设置了一堆参数default_args来演示它的具体实现。注意owner参数的值。
查看我们创建的任务:
- 任务 1是一个简单的 bash 函数,用于打印日期。
- 任务 2通过 Python 函数返回当前时间。
- 任务 3将一组值插入 Postgres 数据库(插入 3 个值
3, 69, 'this is a test!':)。
脚本的最后一部分至关重要:我们在这里设置管道结构。这是set_upstream()我们设置操作发生顺序的一种方法:通过调用set_upstream()每个任务,可以推断 t1 将是第一个任务。忘记设置管道结构将导致任务无法运行!还有其他几种设置方法:
set_downstream()达到 的相反效果set_upstream()。t1 >> t2 >> t3是处理像这样的简单 DAG 的更简洁的方法。
我们现在应该能够在 UI 的图形视图中看到这个 DAG 的结构:

测试我们的 DAG
如果你和我一样,你的 DAG 第一次运行就无法运行。这很让人沮丧。幸运的是,我们可以通过 Airflow CLI 轻松测试新 DAG 中的任务。只需输入以下内容:
airflow test [your_dag_id] [your_task_name_to_test] [today's_date]
这是我输入的用于测试 Postgres 任务的内容:
airflow test my_custom_dag my_python_task 06/01/2019
经过一些调整后,我能够收到成功:
[2019-06-01 11:36:49,702] { __init__.py:1354} INFO - Starting attempt 1 of 2
[2019-06-01 11:36:49,702] { __init__.py:1355} INFO -
--------------------------------------------------------------------
[2019-06-01 11:36:49,702] { __init__.py:1374} INFO - Executing <Task(PythonOperator): my_python_task> on 2019-06-01T00:00:00+00:00
[2019-06-01 11:36:50,059] {python_operator.py:104} INFO - Exporting the following env vars:
AIRFLOW_CTX_DAG_ID=my_custom_dag
AIRFLOW_CTX_TASK_ID=my_python_task
AIRFLOW_CTX_EXECUTION_DATE=2019-06-01T00:00:00+00:00
[2019-06-01 11:36:50,060] {python_operator.py:113} INFO - Done. Returned value was: This function ran at 2019-06-01 11:36:50.060110
果然,我的数据库中创建了该记录!
文章来源:https://dev.to/hackersandslackers/manage-data-pipelines-with-apache-airflow-93o