🤖 我开发了一个能帮我找工作的 AI 代理 🤯
在当前的市场中,找到适合自己的工作非常困难!
最近,我正在探索 OpenAI Agents SDK 并构建 MCP 代理和代理工作流。
为了运用我的学习成果,我想,为什么不解决一个真正的、常见的问题呢?
因此我构建了这个多代理求职工作流程来找到适合我的工作!

在本文中,我将向您展示如何构建此代理工作流程!
开始吧!
求职代理的工作原理
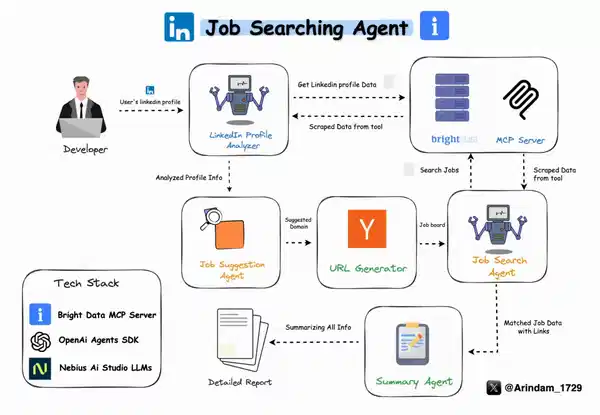
在继续之前,让我们先了解一下工作流代理是如何工作的!
- 首先,用户提供他们的 LinkedIn 个人资料
- 第一位代理使用 BrightData 的 MCP 服务器分析您的个人资料、经验、技能和职业道路。
- 根据分析,它会预测一个符合你的兴趣和经验的领域
- 然后,它使用 BrightData 的 MCP 服务器从 Y Combinator 招聘网站上抓取当前空缺职位
- 最后,它会生成一份详细的报告,其中包含您的个人资料摘要 + 为您量身定制的最佳工作匹配列表。
我对每项任务都使用了单独的代理。
是的,我可以把几个放在一起……但从我的实验来看,这只会让药剂感到困惑并增加幻觉。🙃
如果您更喜欢视频,您可以观看这个:👇🏼
我使用的工具
以下是我用来构建该项目的主要工具。
我一直在寻找简单而可靠的选择,而这些选择结果证明非常适合这项工作。
1. Nebius AI Studio
我一直在寻找一种经济实惠的方式,可以在单个工作流程中多次运行 LLM,而不必过多担心成本或性能。
就在那时我发现了Nebius AI Studio。
它可以轻松运行开源 AI 模型,性能也完全符合我的要求。它速度快、价格实惠,如果你想在不花太多钱的情况下使用强大的模型,它绝对是你的不二之选。
2. BrightData 的 MCP 服务器

LLM 的一大局限性是什么?他们通常无法实时访问实时数据。
MCP 通过允许 LLM 访问外部工具来解决此问题。
对于这个项目,我使用了Bright Data的 MCP(模型上下文协议)服务器。
我在寻找让代理访问互联网的方法时发现了它。有了这个MCP 服务器,我们的代理可以:
- 搜索和浏览网站
- 绕过位置阻止或验证码
- 抓取数据而不被阻止
它非常适合这个项目,我需要来自网络的实时信息。
3.OpenAI Agents SDK
由于我已经在探索 OpenAI Agents SDK 并学习如何构建 MCP 代理和代理工作流,因此我决定将其用作该项目的基础。
我发现它非常简单和灵活,正是我创建多代理设置所需要的,它可以真正解决求职等现实任务。
它是一款轻量级工具,可帮助您轻松创建基于代理的应用程序。有了它,我可以:
- 为我的法学硕士提供指导和工具
- 让代理互相传递工作
- 在将数据发送到模型之前添加基本检查
如果您正在构建多步骤或多代理应用程序,它非常有用。
4. Streamlit 用于 UI

最后,我需要一种快速而干净的方法来构建 UI。
对于 Python 开发人员来说,Streamlit是显而易见的选择。
对于 Python 开发人员来说,Streamlit 是为其应用程序构建直观 UI 的首选。
只需几行代码,我就能拥有一个功能齐全的仪表板,可以在其中输入 LinkedIn URL 并运行工作流程。
它使整个过程变得非常简单。
构建求职代理
说得够多了,让我们开始构建代理吧!🔥
先决条件
在运行此项目之前,请确保您已:
- Python 3.10 或更高版本
- Bright Data帐户和 API 凭证
- Nebius AI Studio帐户和 API 密钥
项目结构
为了保持整洁和模块化,我们这样组织项目:
# Folder Structure 👇🏼
job_finder_agent/
├── app.py # Streamlit web interface
├── job_agents.py # AI agent definitions and analysis logic
├── mcp_server.py # Bright Data MCP server management
├── requirements.txt # Python dependencies
├── assets/ # Static assets (images, GIFs)
└── .env # Environment variables (create this)
以下是简要分析:
app.py:Streamlit 应用的入口点。这是用户与该工具交互的地方。job_agents.py:包含所有与代理相关的逻辑和工作流程。mcp_server.py:初始化 MCP 服务器。- assets/:保存 UI 中使用的任何视觉效果或媒体。
.env:存储 API 密钥等敏感数据,请确保此文件包含在您的.gitignore.
有了这种结构,以后调试、扩展甚至插入新代理都会非常容易。
创建代理🤖
首先,我们将创建项目所需的代理。为此,我们转到job_agents.py文件。
在这里,我们将导入所需的模块:
# job_agents.py 👇🏼
import os
import logging
import asyncio
from agents import (
Agent,
OpenAIChatCompletionsModel,
Runner,
set_tracing_disabled,
)
from agents.mcp import MCPServer
from openai import AsyncOpenAI
logger = logging.getLogger(__name__)
我们现在将定义一个run_analysis启动整个代理工作流程的异步函数。
async def run_analysis(mcp_server: MCPServer, linkedin_url: str):
logger.info(f"Starting analysis for LinkedIn URL: {linkedin_url}")
api_key = os.environ["NEBIUS_API_KEY"]
base_url = "https://api.studio.nebius.ai/v1"
client = AsyncOpenAI(base_url=base_url, api_key=api_key)
set_tracing_disabled(disabled=True)
这是我们的第一个也是最关键的代理之一。它分析用户的 LinkedIn 个人资料,以提取相关的职业见解。
linkedin_agent = Agent(
name="LinkedIn Profile Analyzer",
instructions=f"""You are a LinkedIn profile analyzer.
Analyze profiles for:
- Professional experience and career progression
- Education and certifications
- Core skills and expertise
- Current role and company
- Previous roles and achievements
- Industry reputation (recommendations/endorsements)
Provide a structured analysis with bullet points and a brief executive summary.
""",
mcp_servers=[mcp_server],
model=OpenAIChatCompletionsModel(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_client=client
)
)
💡 注意:此代理确实使用 mcp_server,因为它使用 BrightData 的抓取引擎从 LinkedIn 提取数据。
现在我们已经分析了个人资料,我们需要预测用户最适合哪个领域。
工作建议代理将根据前一个代理的分析,建议用户的首选领域
job_suggestions_agent = Agent(
name="Job Suggestions",
instructions=f"""You are a domain classifier that identifies the primary professional domain from a LinkedIn profile.
""",
model=OpenAIChatCompletionsModel(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_client=client
)
)
💡 注意:这里我们没有使用 MCP 工具,因为它没有执行任何函数调用。
然后,我们将创建一个招聘平台 URL 生成器。该代理会获取域名,并为 Y Combinator 招聘平台构建 URL。
url_generator_agent = Agent(
name="URL Generator",
instructions=f"""You are a URL generator that creates Y Combinator job board URLs based on domains.
""",
model=OpenAIChatCompletionsModel(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_client=client
)
)
接下来,我们将构建职位搜索代理。该代理将访问生成的 URL 并提取真实的职位列表。
Job_search_agent = Agent(
name="Job Finder",
instructions=f"""You are a job finder that extracts job listings from Y Combinator's job board.
""",
mcp_servers=[mcp_server],
model=OpenAIChatCompletionsModel(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_client=client
)
)
💡 注意:此代理再次使用 MCP 服务器,因为它需要向 YC 的工作板进行实时抓取调用。
有时 YC 职位链接会经过身份验证重定向🤷🏻♂️。此代理会清理并简化这些 URL。
如果您使用不需要清理的职位公告板,则可以跳过此代理。
url_parser_agent = Agent(
name="URL Parser",
instructions=f"""You are a URL parser that transforms Y Combinator authentication URLs into direct job URLs.
""",
model=OpenAIChatCompletionsModel(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_client=client
)
)
最后,我们将所有内容整合在一起。该代理会将用户的个人资料、领域预测和作业结果汇总到一份简洁的 Markdown 报告中。
summary_agent = Agent(
name="Summary Agent",
instructions=f"""You are a summary agent that creates comprehensive career analysis reports.
Ensure your response is well-formatted markdown that can be directly displayed.""",
model=OpenAIChatCompletionsModel(
model="meta-llama/Llama-3.3-70B-Instruct",
openai_client=client
)
)
它创建的报告在 Streamlit 甚至 markdown 渲染器中看起来很干净,因此您可以轻松地共享它或保存以备后用!😉
创建工作流
现在所有代理都已准备就绪,让我们构建按逻辑顺序连接它们的实际流程。
在 Agents SDK 中,要创建工作流,您必须将前一个代理的结果作为输入传递,并指定starting_agent为将处理当前任务的代理。
代码如下:
# Get LinkedIn profile analysis
logger.info("Running LinkedIn profile analysis")
linkedin_result = await Runner.run(starting_agent=linkedin_agent, input=query)
logger.info("LinkedIn profile analysis completed")
# Get job suggestions
logger.info("Getting job suggestions")
suggestions_result = await Runner.run(starting_agent=job_suggestions_agent, input=linkedin_result.final_output)
logger.info("Job suggestions completed")
# Get specific job matches
logger.info("Getting job link")
job_link_result = await Runner.run(starting_agent=url_generator_agent, input=suggestions_result.final_output)
logger.info("Job link generation completed")
# Get job matches
logger.info("Getting job matches")
job_search_result = await Runner.run(starting_agent=Job_search_agent, input=job_link_result.final_output)
logger.info("Job search completed")
# Parse URLs to get direct job links
logger.info("Parsing job URLs")
parsed_urls_result = await Runner.run(starting_agent=url_parser_agent, input=job_search_result.final_output)
logger.info("URL parsing completed")
# Create a single input for the summary agent
logger.info("Generating final summary")
summary_input = f"""LinkedIn Profile Analysis:
{linkedin_result.final_output}
Job Suggestions:
{suggestions_result.final_output}
Job Matches:
{parsed_urls_result.final_output}
Please analyze the above information and create a comprehensive career analysis report in markdown format."""
# Get final summary with a single call
summary_result = await Runner.run(starting_agent=summary_agent, input=summary_input)
logger.info("Summary generation completed")
return summary_result.final_output
初始化 MCP 服务器
现在,我们将初始化我们的 MCP 服务器!
我们将首先创建一个mcp_server.py文件,它将处理与设置和访问 MCP 服务器相关的所有事项。
首先,我们导入必要的模块,包括用于处理异步逻辑的 asyncio 和来自 Agents SDK 的 MCPServerStdio:
import os
import logging
import asyncio
from agents.mcp import MCPServerStdio
logger = logging.getLogger(__name__)
_mcp_server = None
接下来,我们将创建 Initializemcpserver fn,它将使用凭证初始化 mcp 服务器
async def initialize_mcp_server():
"""Initialize MCP server."""
global _mcp_server
if _mcp_server:
return _mcp_server
try:
server = MCPServerStdio(
cache_tools_list=False,
params={
"command": "npx",
"args": ["-y", "@brightdata/mcp"],
"env": {
"API_TOKEN": os.environ["BRIGHT_DATA_API_KEY"],
"WEB_UNLOCKER_ZONE": "mcp_unlocker",
"BROWSER_AUTH": os.environ["BROWSER_AUTH"],
}
}
)
await asyncio.wait_for(server.__aenter__(), timeout=10)
_mcp_server = server
return server
except Exception as e:
logger.error(f"Error initializing MCP server: {e}")
return None
💡 注意:请确保您已在 .env 中正确设置环境变量(BRIGHT_DATA_API_KEY、BROWSER_AUTH),否则服务器将无法启动。
此函数做了几件重要的事情:
- 如果服务器已经启动,则防止重新初始化。
- 启动一个新的 MCP 服务器实例。
- 处理超时并正常记录任何故障。
为了保持整洁,我们添加了两个实用函数:
- 等待服务器准备就绪(wait_for_initialization)
- 另一个用于检索服务器实例(get_mcp_server)
它们在这里:
async def wait_for_initialization():
"""Wait for MCP initialization to complete."""
return await initialize_mcp_server() is not None
def get_mcp_server():
"""Get the current MCP server instance."""
return _mcp_server
创建 Streamlit UI
最后,我们将组装所有内容并使用 Streamlit 为该代理创建 UI。
首先,我们导入所有必要的模块并设置 Streamlit 应用程序配置
import streamlit as st
import asyncio
import os
import logging
import nest_asyncio
import base64
from dotenv import load_dotenv
from job_agents import run_analysis
from mcp_server import wait_for_initialization, get_mcp_server
nest_asyncio.apply()
load_dotenv()
logger = logging.getLogger(__name__)
# Set page config
st.set_page_config(
page_title="LinkedIn Profile Analyzer",
page_icon="🔍",
layout="wide"
)
接下来,一旦 MCP 服务器初始化完毕,我们将使用 asyncio 异步调用 run_analysis() 函数。
当用户点击“分析配置文件”按钮时,将触发此功能。
# Initialize session state
if 'analysis_result' not in st.session_state:
st.session_state.analysis_result = ""
if 'is_analyzing' not in st.session_state:
st.session_state.is_analyzing = False
async def analyze_profile(linkedin_url: str):
try:
if not await wait_for_initialization():
st.error("Failed to initialize MCP server")
return
result = await run_analysis(get_mcp_server(), linkedin_url)
st.session_state.analysis_result = result
except Exception as e:
logger.error(f"Error analyzing LinkedIn profile: {str(e)}")
st.error(f"Error analyzing LinkedIn profile: {str(e)}")
finally:
st.session_state.is_analyzing = False
我们还初始化了一些会话状态变量来管理交互之间的应用程序状态。
现在到了最有趣的部分,也就是主 UI 🤩!我们将创建一个简单的 UI 来与我们的 Agent 交互。
def main():
# Load and encode images
with open("./assets/bright-data-logo.png", "rb") as bright_data_file:
bright_data_base64 = base64.b64encode(bright_data_file.read()).decode()
# Create title with embedded images
title_html = f"""
<div style="display: flex; align-items: center; gap: 0px; margin: 0; padding: 0;">
<h1 style="margin: 0; padding: 0;">
Job Searcher Agent with
<img src="data:image/png;base64,{bright_data_base64}" style="height: 110px; margin: 0; padding: 0;"/>
</h1>
</div>
"""
st.markdown(title_html, unsafe_allow_html=True)
st.markdown("---")
# Sidebar
with st.sidebar:
st.image("./assets/Nebius.png", width=150)
api_key = st.text_input("Enter your API key", type="password")
st.divider()
st.subheader("Enter LinkedIn Profile URL")
linkedin_url = st.text_input("LinkedIn URL", placeholder="https://www.linkedin.com/in/username/")
if st.button("Analyze Profile", type="primary", disabled=st.session_state.is_analyzing):
if not linkedin_url:
st.error("Please enter a LinkedIn profile URL")
return
if not api_key:
st.error("Please enter your API key")
return
st.session_state.is_analyzing = True
st.session_state.analysis_result = ""
loop = asyncio.new_event_loop()
asyncio.set_event_loop(loop)
try:
loop.run_until_complete(analyze_profile(linkedin_url))
finally:
loop.close()
# Results section
if st.session_state.analysis_result:
st.subheader("Analysis Results")
st.markdown(st.session_state.analysis_result)
# Loading state
if st.session_state.is_analyzing:
st.markdown("---")
with st.spinner("Analyzing profile... This may take a few minutes."):
st.empty()
if __name__ == "__main__":
main()
就是这样!现在,我们拥有一个功能齐全的 Streamlit UI,它连接到一个多智能体 AI 系统,具有浏览器自动化功能,并通过 MCP 进行抓取。
本地运行:
现在一切都已设置完毕,让我们在本地运行这个应用程序!
首先,我们将创建一个虚拟环境:
python -m venv venv
source venv/bin/activate # On Windows, use: venv\Scripts\activate
接下来,安装以下列出的所有必需软件包requirements.txt:
pip install -r requirements.txt
最后,运行应用程序:
streamlit run app.py
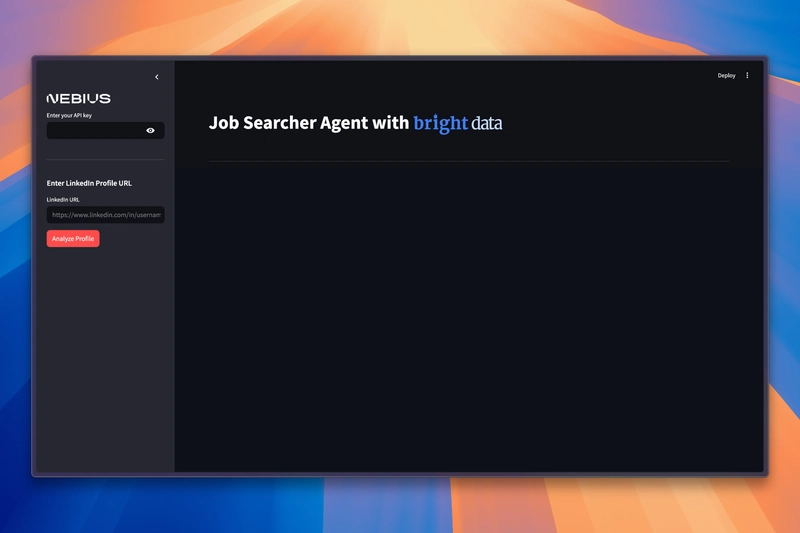
我们的代理已准备好分析 LinkedIn 个人资料并像魔术一样找到匹配的工作。🪄
就这样!🎉
我们已经成功构建了一个多代理工作流,可以使用 MCP 服务器为我们寻找工作。
您可以在这里找到完整的代码:Github Repo
如果您觉得这篇文章有用,请与您的同行分享
另外,关注我以获取更多类似内容:

对于付费合作,请发送电子邮件至:arindammajumder2020@gmail.com。
感谢您的阅读!
