Node.js 底层原理 #7 - 全新 V8
照片由 Priscilla Du Preez 在 Unsplash 上拍摄
从 V8.5.9 版本开始,V8 将其原有的管道(由 Full-Codegen 和 Crankshaft 组成)替换为新的管道,该管道使用了两个全新的编译器:Ignition 和 TurboFan。正是这个新的管道,让 JS 如今运行速度飞快。
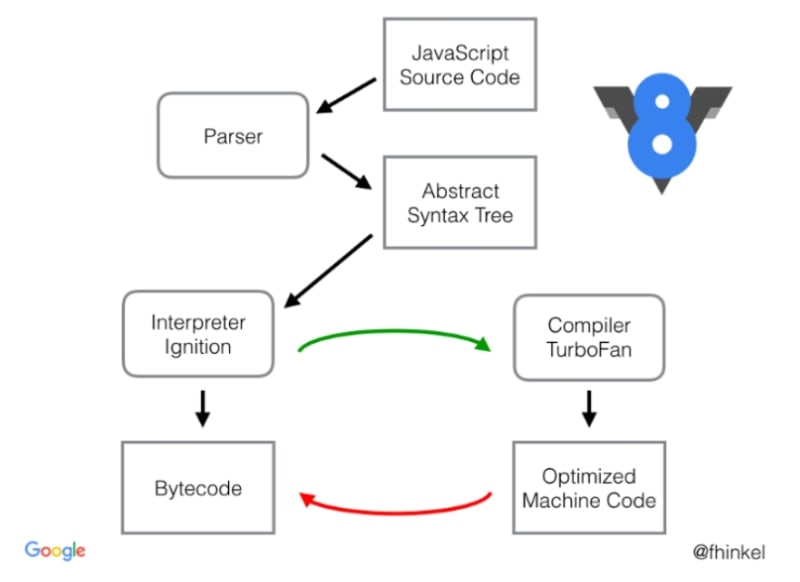
基本上,初始步骤没有改变,我们仍然需要生成 AST 并解析所有 JS 代码,但是,Full-Codegen 已被 Ignition 取代,Crankshaft 已被 TurboFan 取代。
点火

Ignition 是 V8 的字节码解释器,但为什么我们需要解释器呢?编译器比解释器快得多。Ignition 的主要目的是减少内存占用。由于 V8 没有解析器,大多数代码都是动态解析和编译的,因此代码的某些部分实际上会被编译和重新编译多次。这会在 V8 的堆中锁定高达 20% 的内存,这对于内存容量较小的设备尤其不利。
需要注意的是,Ignition不是解析器,而是一个字节码解释器。这意味着代码以字节码形式读取并以字节码形式输出。本质上,Ignition 的作用是获取字节码源并对其进行优化,以生成更小的字节码,同时删除未使用的代码。这意味着,Ignition 不再像以前那样动态地延迟编译 JS,而是一次性获取整个脚本,进行解析和编译,从而减少编译时间,并生成更小的字节码占用空间。
简而言之,这个旧的编译管道:

请注意,这是我们刚刚看到的旧编译管道和 V8 现在使用的新的编译管道之间的步骤。
变成了这样:

这意味着,AST(编译器的真相来源)现在被输入到 Ignition 中,它会遍历所有节点并生成字节码,这是所有编译器的新来源。
本质上,Ignition 所做的就是将代码转换为字节码,因此它会执行以下操作:
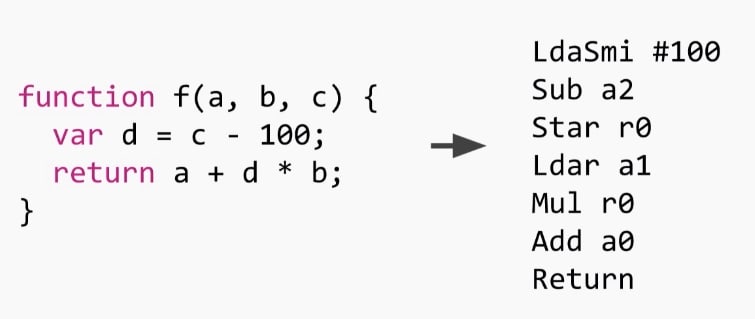
如您所见,这是一个基于寄存器的解释器,因此您可以看到在函数调用期间对寄存器进行操作。r0是需要存储在堆栈上的局部变量或临时表达式的表示。要想象的基准是您有一个无限的寄存器文件,由于它们不是机器寄存器,因此在我们启动时它们会被分配到堆栈框架上。在这个特定的函数中,只使用了一个寄存器。一旦函数启动,r0就会作为被调用者分配到堆栈上undefined。其他寄存器(a0到a2)是该函数的参数(a、b和c),它们由被调用者传递,因此它们也在堆栈上,这意味着我们可以将它们作为寄存器进行操作。
还有另一个隐式寄存器,称为accumulator,它存储在机器的寄存器中,所有输入或输出都应该存储在那里,这意味着操作的结果和变量的加载
读取该字节码,我们有以下一组指令:
LdaSmi #100 -> Load constant 100 into the accumulator (Smi is Small Integer)
Sub a2 -> Subtract the constant we loaded from the a2 parameter (which is c) and store in the accumulator
Star r0 -> Store the value in the accumulator into r0
Ldar a1 -> Read the value of the a1 parameter (b) and store into the accumulator
Mul r0 -> Multiply r0 by the accumulator and store the result also in the accumulator
Add a0 -> Adds the first parameter a0 (a) into the accumulator and stores the result in the accumulator
Return -> Return
我们将在下一篇文章中深入讨论字节码
遍历 AST 之后,生成的字节码会被逐个送入优化流水线。因此,在 Ignition 能够解释任何内容之前,解析器会应用一些优化技术,例如寄存器优化、窥孔优化和死代码移除。

优化管道是顺序的,这使得 Ignition 可以读取更小的字节码并解释更优化的代码。
这是从解析器到 Ignition 的完整管道:

字节码生成器恰好是另一个编译器,它编译为字节码而不是机器码,可以由解释器执行。
Ignition 不是用 C++ 编写的,因为它需要在解释函数和 JIT 函数之间建立跳床,因为调用约定不同。
它也不像 V8 中的许多东西那样用手工汇编编写,因为它需要移植到 9 种不同的架构中,这是不切实际的。
Ignition 并非如此,它基本上是使用 TurboFan 编译器的后端编写的,这是一个一次性编写的宏汇编器,可以编译到所有架构。而且,我们还可以免费获得 TurboFan 生成的底层优化。
涡扇发动机

TurboFan 是一款 JS 优化编译器,现已取代 Crankshaft 成为官方的 JIT 编译器。但它并非一直如此。TurboFan 最初的设计目标是成为一个非常优秀的 WebAssembly 编译器。TurboFan 的初始版本实际上非常智能,进行了大量类型和代码优化,在通用 JavaScript 中表现非常出色。
TurboFan 采用了一种名为“节点海”(Sea-of-Nodes)的表示方法(我们将在下一章讨论,但文章底部有参考链接),仅此一项就大幅提升了 JavaScript 代码的整体编译性能。TurboFan 的理念是实现 Crankshaft 已有的所有功能,同时让 V8 能够编译出速度更快的 ES6 代码,而 Crankshaft 当时并不知道该如何处理 ES6 代码。因此,TurboFan 最初只是作为 ES6 代码的辅助编译器:
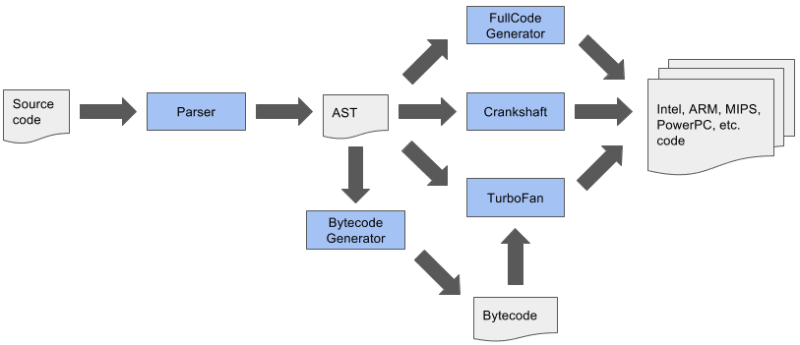
除了技术复杂性之外,整个问题在于,语言特性应该在管道的不同部分实现,并且所有这些管道都应该相互兼容,包括它们生成的代码优化。当 TurboFan 无法处理所有用例时,V8 曾使用过这种编译管道一段时间,但最终,这种管道被另一种管道取代了:

正如我们在上一章中看到的,Ignition 将解析后的 JS 代码解释为字节码,字节码成为流水线中所有编译器的新数据来源,AST 不再是所有编译器在编译代码时依赖的唯一数据来源。这一简单的改变使得许多不同的优化技术成为可能,例如更快地删除死代码,以及大大减少内存和启动占用空间。
除此之外,TurboFan 明确分为 3 个独立的层:前端、优化层和后端。
前端层负责生成由 Ignition 解释器运行的字节码,优化层则仅负责使用 TurboFan 优化编译器进行代码优化。所有其他较低级别的任务,例如低级优化、调度以及为支持的架构生成机器码,均由后端层处理 - Ignition 也依赖 TurboFan 的后端层来生成其字节码。仅层级分离一项就使机器特定代码比以前减少了 29%。

去优化悬崖
总而言之,TurboFan 的设计和创建完全是为了处理 JavaScript 等不断发展的语言,而 Crankshaft 并不是为此而设计的。
这是因为 V8 团队过去专注于编写优化代码,而忽略了随之而来的字节码。这导致了几个性能悬崖,使得运行时执行变得非常难以预测。有时,一段快速运行的代码会遇到 Crankshaft 无法处理的情况,然后这段代码可能会被去优化,运行速度可能比前者慢 100 倍。这就是所谓的优化悬崖。最糟糕的是,由于运行时代码执行的不可预测性,我们无法隔离甚至解决这类问题。因此,编写“CrankScript”——一段为了让 Crankshaft 满意而编写的 JavaScript 代码——的重任就落在了开发者的肩上。
早期优化
过早的优化是万恶之源,即使是编译器也是如此。基准测试证明,优化编译器的重要性不如解释器。由于 JavaScript 代码需要快速执行,因此在执行之前没有时间编译、重新编译、分析和优化代码。
这个问题的解决方案超出了 TurboFan 或 Crankshaft 的范围,我们通过创建 Ignition 解决了这个问题。优化解析器生成的字节码可以大大减小 AST,从而减小字节码,最终减少内存占用,因为进一步的优化可以推迟到以后进行。代码执行时间越长,优化编译器的类型反馈就越多,最终减少了由于错误类型反馈信息导致的反优化。
文章来源:https://dev.to/_staticvoid/node-js-under-the-hood-7-the-new-v8-4gd6