全栈自然语言处理:构建和部署端到端假新闻分类器
NLP分类器
Web 应用程序架构
Docker 化与部署
最初发布在我的个人博客上(格式更好)
TLDR:这是一个关于构建 NLP 文本分类 Web 应用程序的 API+UI 并将其部署到生产的教程。
注意:所使用的分类模型并非绝对准确,而且在训练数据集上明显存在过拟合。本文重点介绍如何实现全栈 Web 应用程序。参考文献 1。参考文献 2。
在IE攻读硕士学位期间,我参与了NLP课程的文本分类模型的研究。我的笔记比较杂乱,但我会尽量在第一部分简要解释一下。
NLP分类器
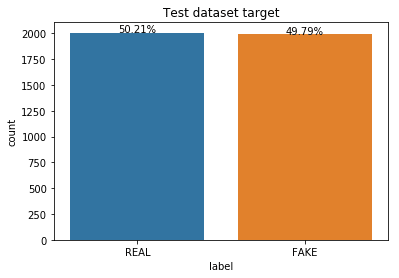
我们的任务是定义某篇新闻是否为假新闻。数据集包含 3997 篇新闻文章,每篇都包含标题、正文和目标标签(真/假二元标签)。课程的一部分内容是在测试数据集上测试模型,但我从未收到过该数据集的目标标签。在训练数据集上进行交叉验证测试的准确率为94%。

我不会详细介绍笔记本的编码细节,但我会简要描述在得出最终模型之前采取的主要步骤。
文本预处理
我们可以清楚地看到目标是平衡的。因此,我们通过执行以下操作进入预处理阶段:
- 将文本小写:完成此预处理步骤是为了稍后可以使用停用词和 pos_tag 词典进行交叉检查。
- 删除仅包含一个字母的单词
- 删除包含数字的单词
- 对文本进行标记并删除标点符号
- 删除停用词:正确的文本分析通常依赖于最常出现的单词。诸如“the”、“as”和“and”之类的停用词在文本中出现很多次,但每个词都无法提供相关的解释,因此自然语言处理 (NLP) 的常见做法之一是删除此类词。
- 删除空标记:标记化之后,我们必须确保所有考虑的标记都有助于标签预测。
- 对文本进行词形还原:为了规范化文本,我们应用了词形还原。这样,具有相同词根的单词会得到同等处理。例如,当文本中出现“took”或“taken”时,它们会被词形还原为动词不定式“take”。
您可以在python_helper.py:79preprocess()中找到该函数。
基线
在笔记本的这一部分,您可以看到我如何分割和矢量化数据集并在数据集上运行多个分类器并测量基线准确性。
最大熵文本分类器的准确率有显著提高。
特征工程与流程
有了基准分数后,我们会做一些额外的工作:
- 位置标签文本:
为每个单词添加一个前缀,表示其类型(名词、动词、形容词……)。例如:我去上学 => PRP-I VBD-went TO-to NN-school
另外,词形还原后将变为“VB-go NN-school”,这表明了语义并区分了句子的目的。
这将有助于分类器区分不同类型的句子。

- TF-IDF加权:
TF-IDF 或词频-逆文档频率尝试根据每个单词在文本中的重复出现来计算其重要性。
- 使用 Trigram Vectorizer 代替常规矢量化器:
我在这里选择使用 Trigram 矢量化器,它对三个单词进行矢量化,而不是对每个单词单独进行矢量化。在这个简短的例句中,三元组分别是“在这个简短的例句中”、“这个简短的例句”和“简短的例句”。
最后,我对过去步骤的不同组合以及不同的模型进行网格搜索,以优化最佳超参数。
如果你看一下这里的预测,你会发现这是性能最好的模型(Vectorizer + TF-IDF + Classifier):
trigram_vectorizer = CountVectorizer(analyzer = "word", ngram_range=(1,3))
tf_idf = TfidfTransformer(norm="l2")
classifier = LogisticRegression(C=1000, class_weight=None, dual=False, fit_intercept=True,
intercept_scaling=1, max_iter=100, multi_class='warn',
n_jobs=None, penalty='l2', random_state=None, solver='warn',
tol=0.0001, verbose=0, warm_start=False)
我将所有内容包装在一个管道中,以便轻松训练(fit())和分类(predict())输入。
from sklearn.pipeline import Pipeline
pipeline = Pipeline([
('trigram_vectorizer', trigram_vectorizer),
('tfidf', tf_idf),
('clf', classifier),
])
腌制
下一步是像这样在训练数据上拟合管道:
pipeline.fit(train.clean_and_pos_tagged_text, encoder.fit_transform(train.label.values))
在此阶段,pipeline对象可以进行新的输入。您可以在此处的predict()笔记本中找到测试预测步骤。
现在,魔法来了。如果您想将整个模型连同训练数据封装在一个文件中以便在任何地方使用,您可以使用Pickle 库。
import pickle
pickle.dump( pipeline, open( "pipeline.pkl", "wb" ) )
Python 中的任何对象都可以被 pickle 保存到磁盘上。然后,它可以被传输到另一个 Python 环境中导入。pickle 的作用是,在将 Python 对象写入文件之前,对其进行序列化。Pickling 只是一种将任何 Python 对象(列表、字典等)转换为字符流的方法。其背后的理念是,这个序列化的文本流包含在另一个 Python 脚本中重建对象所需的一切。
在这种情况下,我们正在腌制我们的pipeline对象,以便稍后可以在 API 中使用它pipeline.predict()。
该pipeline.pkl文件现在可以预测任何新闻文章并将其分类为REAL或FAKE。
Web 应用程序架构

因此,我们需要一个 Web 界面,用户可以在其中输入一些新闻文本,然后单击按钮,应用程序即可对输入进行预处理并将其提供给训练有素的模型,并在屏幕上显示分类。
请记住,为了使腌制管道能够正确预测,我们需要以与训练数据集预处理完全相同的方式向其提供预处理的文本。
- 前端/UI:
这将是一个简单的页面,只有一个输入框和一个按钮。无需复杂化。正如我之前提到的, React 更适合这种简单的功能。
- 后端/服务器:
由于我们需要对模型进行“反序列化”才能使用,因此最佳选择是一个能够通过 HTTP 接收输入并返回预测结果的 Python Web 服务器。Flask 是最简单、最直接的框架之一。pickle.load()pipeline
服务器的另一个新增功能是实现一个“随机选择器”,它可以从测试数据集中一次随机获取一篇新闻文章。这将用于填充 UI 输入字段。
目标是让用户更轻松地测试应用程序,而无需实际撰写新闻文章。
Flask API 服务器
假设您有一个现成的 Python 环境并且熟悉 Python 开发,那么安装 pythons 非常简单:
pip install flask
如果您想使用,您可以在此处virtualenv查看步骤。
当你点击根路径时,为静态 React 应用程序(下一节)提供服务的简单 Flask API/如下所示:
from flask import Flask, render_template
app = Flask(__name__, static_folder="./public/static", template_folder="./public")
@app.route("/")
def home():
return render_template('index.html')
# Only for local running
if __name__ == '__main__':
app.run()
现在你只能使用这个,template_folder在其中添加一个简单的 hello world HTML 文件。在下一节构建 React 应用时,我们将使用static_folder存储的 CSS 和 JavaScript 文件等资源。
如果您运行该命令python app.py并点击,http://localhost:5000您应该会看到/public/index.html浏览器中显示的。
如上一节所述,我们主要需要实现两个函数:预测 (predict)和随机 (random )。让我们从更简单的随机选择器端点开始。
random/:
由于文件夹中有测试数据集/data,我们只需要加载它并选择一个随机索引并将其发送回 UI。
from flask import jsonify
import pandas as pd
from random import randrange
@app.route('/random', methods=['GET'])
def random():
data = pd.read_csv("data/fake_or_real_news_test.csv")
index = randrange(0, len(data)-1, 1)
return jsonify({'title': data.loc[index].title, 'text': data.loc[index].text})
jsonify()我们在这里使用 Pandas 读取 CSV 文件,然后使用 flask辅助函数以 JSON 格式发回数据。
现在,无论何时您使用 Postman 发送 GET 请求或在浏览器中http://localhost:5000/random/打开链接,您都应该看到来自测试数据集文件的随机新闻条目。
predict/:
对于预测函数,除了暴露端点之外,我们还需要做一些工作。我们需要获取输入,进行预处理,进行 pos-tag 处理,然后将其输入到管道并返回结果。
因此,我们在单独的文件中创建一个 PredictionModel 类:
from nltk.corpus import wordnet
import string
import nltk
nltk.data.path.append('./nltk_data') # local NLTK data
from nltk.corpus import stopwords
from nltk import pos_tag
from nltk.stem import WordNetLemmatizer
class PredictionModel:
output = {}
# constructor
def __init__(self, text):
self.output['original'] = text
def predict(self):
self.preprocess()
self.pos_tag_words()
# Merge text
clean_and_pos_tagged_text = self.output['preprocessed'] + \
' ' + self.output['pos_tagged']
self.output['prediction'] = 'FAKE' if pipeline.predict(
[clean_and_pos_tagged_text])[0] == 0 else 'REAL'
return self.output
# Helper methods
def preprocess(self):
# check file on github
def pos_tag_words(self):
# check file on github
然后我们在app.py端点中使用该类,如下所示:
@app.route('/predict', methods=['POST'])
def predict():
model = PredictionModel(request.json)
return jsonify(model.predict())
因此,基本上,当您向发送 POST 请求时http://localhost:5000/predict,脚本将PredictionModel使用输入文本初始化一个新实例并返回预测。
例如PredictionModel("Some news article text"),将返回如下的 JSON 对象:
{
"original":"Some news article text",
"preprocessed":"news article text",
"pos_tagged":"NN-news NN-article IN-text",
"prediction":"FAKE"
}
注意:我导出了 NLTK 数据,您可以看到我在这里从本地路径加载它。这样做的原因是为了更好地管理版本,因为我在 Docker 上安装正确的 NLTK 库时遇到了问题。
但是我们使用了该pipeline对象但实际上并没有声明它......
加载泡菜:
这里我们需要理解的关键点是,在使用.pickle 文件进行预测之前,我们需要先加载它。请注意,pickle 文件的大小约为 350 MB 。
我们可以在文件顶部添加:
with open("pickle/pipeline.pkl", 'rb') as f:
pipeline = pickle.load(f)
请记住,当您第一次运行app.py脚本时,它会加载 350MB 管道对象到您的机器 RAM 中。
初始运行后,当脚本处于待机状态等待请求时,无论何时调用pipeline.predict()脚本,它都会立即运行,因为对象已经在您的 RAM 中。
注意:在本地运行时,此方法可以正常工作,但将其部署到生产环境中时,需要考虑服务器内存以及脚本崩溃时会发生什么。我将在部署部分讨论这个问题。
React 用户界面
我们将使用以下命令初始化 React 应用create-react-app。您可以通过运行 来全局安装它npm i -g create-react-app。
然后,为了初始化实际的代码模板,我们运行create-react-app fake-news-client。这将创建一个名为“fake-news-client”的文件夹,并在其中安装所需的包。
如果您进入文件夹并运行一个简单的程序,react-scripts start您应该会在浏览器中构建并提供一个简单的反应应用程序http://localhost:3000/。
请注意,后端文件将是项目的根文件夹,而前端将位于其中名为的子目录中
webapp。
现在我们需要安装一个将在项目中使用的额外包。cd 进入文件夹并运行npm i -s node-sass。
我正在使用它node-sass来编写应用程序样式,这意味着您需要将所有.css文件重命名.scss并更改文件中的引用index.js。
让我们构建 UI
在/src/index.js文件中,我们可以开始添加状态对象以及包含以下内容的 HTML 模板:
- 输入:新闻文本的文本区域
- 操作:按钮获取
/random数据,另一个按钮/predict - 状态标签:应用程序可以处于以下状态之一:空闲、加载或错误。
- 结果标签:预测,真实/假。
import React from 'react';
import ReactDOM from 'react-dom';
import './index.scss';
class NLPInterface extends React.Component {
state = {
text: '', // Textarea value
loading: false, // Loading state flag
error: false, // Error state flag
prediction: null, // Prediction result
}
render() {
return (
<div className="container">
<h1>NLP Fake News Classifier</h1>
<textarea disabled={this.state.loading} value={this.state.text} onChange={this.updateInput}>
</textarea>
<button disabled={this.state.loading} className="random" onClick={this.random}>
Load random News from test dataset ? <span>Click here</span>.
</button>
<button disabled={this.state.loading} className="cta" onClick={this.predict}> Predict </button>
{this.state.loading ? <h1>Classifying ...</h1> : ''}
{this.state.error ? <h1>ERROR</h1> : ''}
<h1>
{this.state.prediction}
</h1>
</div>
)
}
}
ReactDOM.render(
<NLPInterface />,
document.getElementById('root'));
您可以在SCSS 文件中找到样式。
下一步是写下将模板与后端连接起来所需的 UI 逻辑。
让我们从文本区域开始,我们可以看到它从中读取它的值this.state.text,并且onChange我们正在绑定this.updateInput将更新的事件处理程序state.text
updateInput = ({ target: { value } }) => this.setState({
text: value,
prediction: null // To reset previous prediction whenever the text in the textarea changes
});
接下来我们有随机新闻选择器按钮,它会触发以下功能onClick:
random = () => fetch("/random")
.then(response => response.json())
.then(article => article.title + '\n\n' + article.text)
.then(text => this.setState({
text,
prediction: null
}))
.catch(error => this.setState({ error: true }));
最后,我们将实际的预测功能绑定到另一个按钮:
predict = () => {
this.setState({ loading: true, prediction: null }); // Start loading
fetch("/predict", {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify(this.state.text)
})
.then(response => response.json())
.then(({ prediction }) => {
this.setState({ loading: false, prediction })
})
.catch(error => this.setState({ loading: false, error: true }))
}
这将获得预测结果,并将其存储到函数底部的标签state.prediction中显示。H1render()
瞧!我们有一个可以与 Flask 后端通信的工作网页。
捆绑
为了捆绑前端应用程序并将其移动到/publicFlask 应用程序将提供的文件夹,我们将编辑package.json文件:
"scripts": {
"prebuild": "rm -r ../public",
"build": "react-scripts build",
"postbuild": "mv build/ ../public",
}
现在,如果您npm run build在 webapp 文件夹中运行,然后进入上一级目录
并运行,python app.py然后访问,http://localhost:5000您会发现应用程序已启动并正在运行🎉🎉
Docker 化与部署
要在远程服务器上成功运行此应用程序,我们需要考虑到这将是一个启动时间相对较慢的服务,因为一旦脚本运行,我们就会加载 350 MB 的 pickle。
为此,我们将使用gunicorn HTTP 服务器来运行 python 应用程序。gunicorn 基本上会:
- 使用多个异步工作者并行运行服务器脚本多次
- 确保服务器始终运行并接受请求
运行后,pip install gunicorn您可以运行以下命令使用 gunicorn 运行脚本:
gunicorn -t 120 -b :8080 app:app
这将在端口 8080 上运行服务器,我添加了-t 120标志以告诉它在超时前等待 120 秒。
现在我们开始部署。我选择使用Google Cloud Run来运行这个应用程序,也是因为我们的应用程序需要加载大型 pickle 文件,因此无状态工作负载很重。
要使用 Cloud Run,我们需要通过写下Dockerfile来容器化我们的应用程序:
FROM python:3.7-stretch
RUN apt-get update -y
RUN apt-get install -y python-pip python-dev build-essential
COPY . /app
WORKDIR /app
RUN python -m pip install --upgrade pip
RUN pip install -r requirements.txt
CMD gunicorn -t 120 -b :$PORT app:app
您还可以看到我将所有需要的 Python 包导出到一个requirments.txt文件中。
最后,为了使其在 Google Cloud 上运行,您需要:
- 启动 Google Cloud 项目
- 激活计费
- 打开 Google 在线控制台
- 将代码拉入你的账户服务器
cd进入项目文件夹并运行gcloud builds submit --tag gcr.io/[your project ID]/fake-news-service这会将 docker 容器镜像部署到该 URL 中。- 转到 Cloud Run 仪表板并点击“创建服务”
- 输入您在步骤 5 中创建的图像 URL
- 设置分配的内存为1GB
- “创造”

💃🏼 💃🏼该应用程序将在不到 5 分钟的时间内启动并运行。💃🏼 💃🏼
相关链接:
文章来源:https://dev.to/iammowgoud/fullstack-nlp-building-deploying-end-to-end-fake-news-classifier-56fb