Docker 可以在本地运行 LLM。等等,什么?!
由 Mux 主办的 DEV 全球展示挑战赛:展示你的项目!
使用 Docker 在本地运行大型语言模型 (LLM)?没错,你没听错。Docker 现在的功能远不止运行容器镜像。借助Docker Model Runner,你可以在本地运行 LLM 并与之交互。
毋庸置疑,我们已经看到开发领域正朝着人工智能 (AI) 和基因人工智能 (GenAI) 的方向发生巨大转变。考虑到从成本到部署的种种繁琐环节,开发一款基于基因人工智能的应用并非易事。而 Docker 一如既往地发挥着其优势:简化基因人工智能的开发,让开发者能够更快地构建和发布产品及项目。我们现在可以直接在机器上运行 AI 模型!没错,它可以在容器之外运行模型。目前,Docker Model Runner 处于 Beta 测试阶段,适用于搭载 Apple Silicon 的 Mac 版 Docker Desktop,需要 Docker Desktop 4.40 或更高版本。
在本篇博客中,我们将探讨 Docker 模型运行器的优势以及如何以各种方式使用它。让我们马上开始吧!
Docker模型运行器的优势
-
开发者流程:作为开发者,我们最不喜欢的方面之一就是上下文切换和使用 100 种不同的工具,而几乎每个开发者都在使用的 Docker 让事情变得简单,并降低了学习曲线。
-
GPU 加速:Docker Desktop直接在主机上运行llama.cpp 。推理服务器可以访问 Apple 的 Metal AP,从而直接访问 Apple Silicon 上的硬件 GPU 加速。
-
OCI Artifacts:将 AI 模型存储为 OCI Artifacts 格式,而不是 Docker 镜像格式。这可以节省磁盘空间并减少数据提取工作。此外,由于 OCI 是行业标准格式,因此还能提高兼容性和适应性。
-
一切本地化:您无需面对云端 LLM API 密钥、速率限制、延迟等诸多麻烦,即可在本地绑定产品并支付高昂费用。此外,数据隐私和安全也得到了充分保障。模型会根据需要由 llama.cpp 动态加载到内存中。
行动中
请确保您的系统中已安装 Docker Desktop v4.40 或更高版本。安装完成后,请前往“设置”>“开发功能”启用“启用 Docker 模型运行器”。您还可以勾选“启用主机端 TCP 支持”以从本地主机进行通信(我们将在下文中看到演示)。
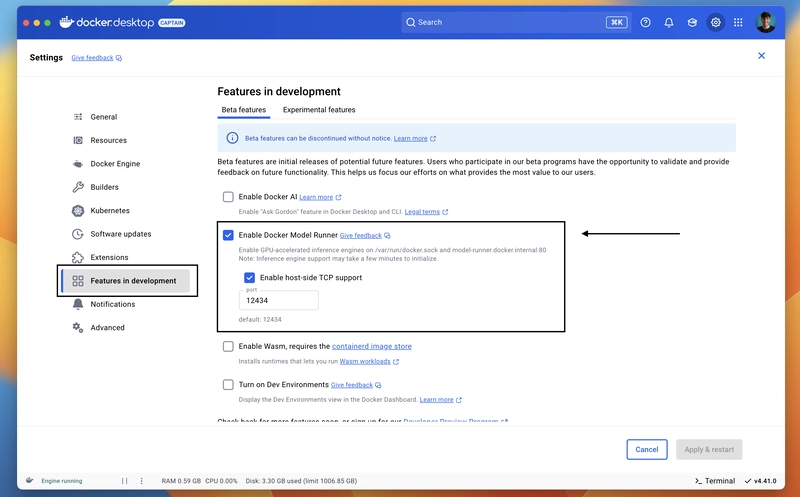
完成后,点击“应用并重启”,一切就绪。要测试是否正常工作,请打开任意终端(输入任意命令)docker model,您将看到所有可用命令的输出,这将验证一切是否按预期运行。
因此,要与LLM交互,我们目前有两种方法(敬请期待):通过CLI或API(兼容OpenAI)。CLI和API都非常直观。我们可以从运行中的容器内部或本地主机与API交互。接下来,我们将更详细地了解这些方法。
通过命令行界面
如果你用过 Docker CLI(几乎所有接触过容器的开发者都用过),并且使用过类似docker pull`docker docker runpull`、`docker model` 等命令,那么 Docker 模型也遵循相同的模式,只是多了一个子命令,即 ` model`关键字。所以,要拉取一个模型,我们可以使用 `docker pull` docker model pull <model name>,要运行一个已拉取的模型,可以使用 `docker model` docker model run <model name>。这大大简化了操作,因为我们无需为了一个新工具而学习全新的术语。
以下是目前支持的所有命令。更多命令即将推出(其中一些也是我最喜欢的)。敬请期待!
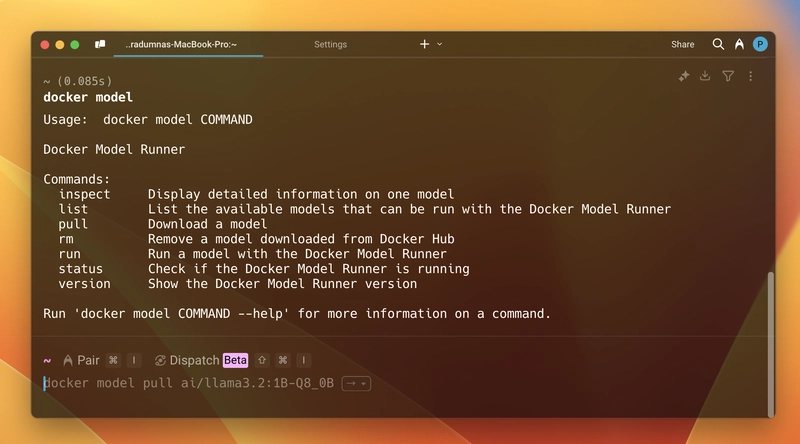
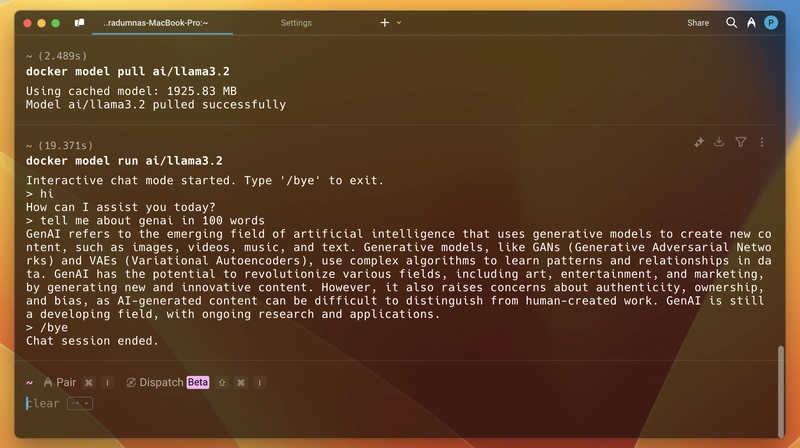
现在,要运行一个模型,首先需要拉取它。例如,我们将运行 `docker pull` 命令llama3.2。您可以在Docker Hub 的 GenAI Catalog中找到所有可用的模型。打开终端并运行 `docker pull` 命令docker model pull ai/llama3.2。拉取模型需要一些时间,具体时间取决于模型的大小和您的网络带宽。拉取完成后,运行 `docker pull` 命令docker model run ai/llama3.2,它将启动一个类似普通聊天机器人或 ChatGPT 的非正式聊天模式。聊天结束后,您可以使用 ` /byedocker pull` 命令退出交互式聊天模式。以下是屏幕截图:
来自 API(OpenAI)
Model Runner 的一个绝妙之处在于它实现了与 OpenAI 兼容的接口。我们可以通过多种方式与 API 交互,例如在运行的容器内部,或者通过 TCP 或 Unix 套接字从主机进行交互。
我们将看到不同方法的示例,但在此之前,这里列出可用的端点。无论我们是从容器内部还是从主机与 API 交互,端点都保持不变。只有主机会改变。
# OpenAI endpoints
GET /engines/llama.cpp/v1/models
GET /engines/llama.cpp/v1/models/{namespace}/{name}
POST /engines/llama.cpp/v1/chat/completions
POST /engines/llama.cpp/v1/completions
POST /engines/llama.cpp/v1/embeddings
Note: You can also omit llama.cpp.
从容器内部
在容器内部,我们将使用http://model-runner.docker.internal它作为基本 URL,并且可以访问上面提到的任何端点。例如,我们将访问/engines/llama.cpp/v1/chat/completions该端点进行聊天。
我们将使用该模型curl。您可以看到它使用了与 OpenAI API 相同的模式结构。请确保您已拉取要使用的模型。
curl http://model-runner.docker.internal/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 100 words about the docker compose."
}
]
}'
为了测试它在运行的容器内部是否有效,我以jonlabelle/network-tools交互模式运行镜像,然后使用上述 curl 命令与 API 通信。结果成功了。
如您所见,下方是我收到的响应。响应采用 JSON 格式,包含生成的消息、令牌使用情况、模型详情和响应时间。一切都符合标准。
来自主持人
正如我之前提到的,要与 A 交互,您必须确保已启用 TCP。您可以通过访问 [此处应填写网址] 来验证 TCP 是否正常工作localhost:12434。您将看到一条消息,提示“Docker 模型运行器。该服务正在运行。”
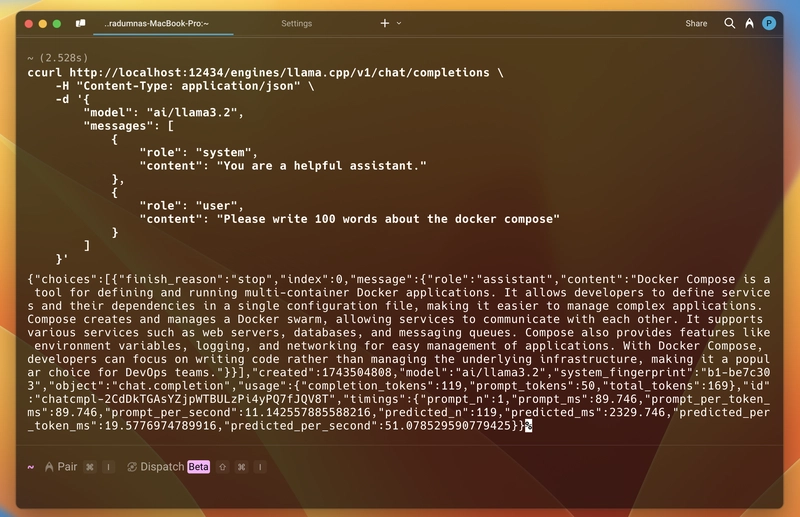
在这种情况下,我们将使用http://localhost:12434基本 URL,并遵循相同的端点。curl 命令也是如此;我们只需替换基本 URL,其他一切都保持不变。
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "ai/llama3.2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 100 words about the docker compose."
}
]
}'
让我们在终端中运行一下来试试:
它将返回与另一个相同的 JSON 格式响应,包括生成的消息、令牌使用情况、模型详细信息和响应时间。
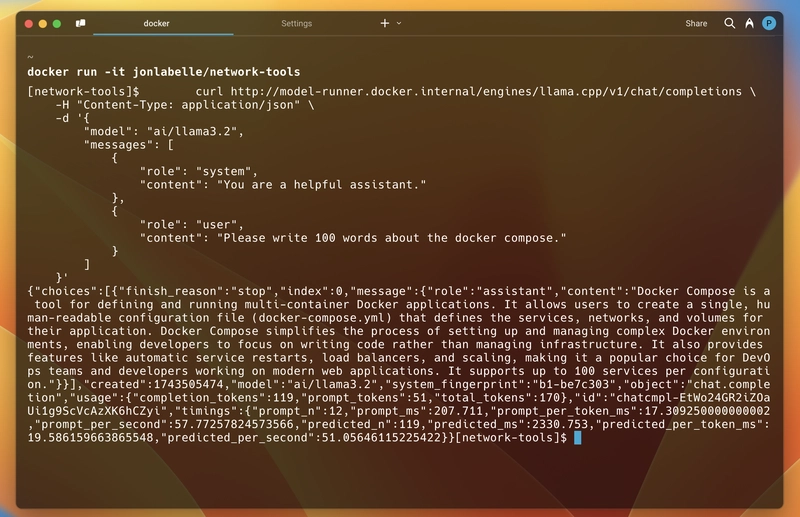
有了 TCP 支持,我们不仅可以与容器内运行的应用程序交互,还可以与任何地方的应用程序交互。
博客就到这里。您可以点击此处访问官方文档,了解更多关于 Docker 模型运行器的信息。请密切关注 Docker 的公告,后续会有更多内容发布。一如既往,很高兴您读到了最后——非常感谢您的支持。我经常在Twitter上分享技巧(永远都是 Twitter 啦 😉)。您可以在那里关注我。
文章来源:https://dev.to/pradumnasaraf/docker-can-run-llms-locally-wait-what-35fn