✨ Gemini 2.5 Pro 与 Claude 3.7 Sonnet 编码比较 🔥
谷歌刚刚于 3 月 26 日推出了一个新模型,他们声称该模型在编码、推理和整体各方面都是最好的。🥴但我最关心的是该模型与目前最好的模型 Claude 3.7 Sonnet 的比较情况,而 Claude 3.7 Sonnet 本身于 2 月底发布。
让我们在编码中比较这两个模型,看看我是否需要更改我最喜欢的编码模型,或者 Claude 3.7 是否仍然成立。😮💨

TL;DR
如果您想直接得出结论,根据我们的测试和模型基准,与这些编码性能最强的模型相比,我建议您选择Gemini 2.5 Pro。不过,Claude 3.7 Sonnet 的表现也相差不远。
就在上一篇文章中,Claude 3.7 Sonnet 在所有型号的对比中都占据了绝对优势,我以为这种情况还会持续一段时间。但现在,Gemini 2.5 Pro 占据了主导地位。感觉我们正式进入了 AI 时代。🫠
Gemini 2.5 Pro简介
Gemini 2.5 Pro 目前是一款实验性思维车型,发布不到一周就迅速成为热议话题。Twitter (X) 和 YouTube 上人人都在热议这款车型。它简直是无处不在的热门话题。
就这样,它在 LMArena 上排名第一。但这意味着什么呢?这意味着,这个模型不仅在编码方面,而且在数学、科学、图像理解等方面都击败了所有其他模型。

Gemini 2.5 pro 配备了100 万个令牌上下文窗口,并且即将推出 200 万个上下文窗口。🤯
您可以查看其他人(例如Theo-t3)对此模型的讨论,以对其有更多的了解:
据称这是迄今为止编码最好的模型,在 SWE-bench 上的准确率约为63.8%,这绝对高于我们之前的顶级编码模型 Claude 3.7 Sonnet,准确率约为 62.3%。

这是 Google 分享的关于构建恐龙游戏模型的快速演示。
以下是该模型在推理、数学和科学方面的快速基准测试。这证实了该模型不仅适用于编程,也适用于你所有其他需求。我认为他们声称它是一个全能型的模型。🤷♂️
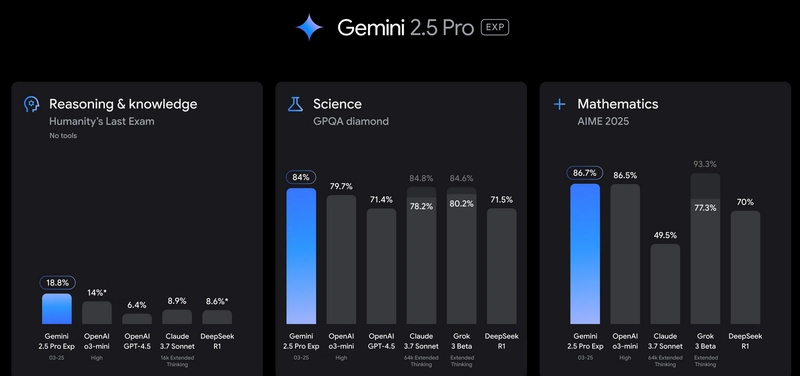
这一切都很酷,我会证实这一说法,但在本文中,我将主要比较编码模型,让我们看看它与 Claude 3.7 Sonnet 相比表现如何。
编码问题
💁 让我们比较一下这两个模型在编码方面的表现。我们将进行总共 4 项测试,主要针对 WebDev、动画和一道 LeetCode 难题。
1.飞行模拟器
提示:使用 JavaScript 创建一个简单的飞行模拟器。该模拟器应包含一架可以从平坦跑道起飞的飞机。飞机的飞行可以通过简单的键盘输入(例如方向键或 WASD)进行控制。此外,使用块状结构生成一个类似于 Minecraft 的基本城市景观。
Gemini 2.5 Pro 的回应
您可以在此处找到它生成的代码:链接
这是程序的输出:
我完全满足了我的要求,从飞机的移动到基本的 Minecraft 风格的积木建筑,一切都功能齐全。我实在没什么可抱怨的。这款游戏 10/10 分满分。🔥
克劳德的回应 3.7 十四行诗
您可以在此处找到它生成的代码:链接
这是程序的输出:
我发现这架飞机有些问题。飞机明显是侧着的,我不知道为什么。而且,它一起飞就完全失控了,而且明显飞出了城外。总而言之,我觉得我们这里根本没用到一台完全可以正常工作的飞行模拟器。
概括:
公平地说,Gemini 2.5 确实一次性解决了这个问题。虽然 Claude 3.7 Sonnet 代码的问题其实并不大,但我们确实没有得到预期的输出,而且绝对比不上 Gemini 2.5 Pro 的结果。
2. 魔方解算器
这是法学硕士(LLM)最难的题目之一。我试过很多其他法学硕士(LLM)的题目,但都没答对。让我们看看这两个模型是怎么做的。
提示:使用 Three.js 用 JavaScript 构建一个简单的 3D 魔方可视化和求解器。该魔方应使用标准颜色构建一个 3x3 的魔方。包含一个随机打乱魔方的打乱按钮。包含一个逐步呈现解题过程的求解函数。允许使用基本的鼠标控制来旋转视图。
Gemini 2.5 Pro 的回应
您可以在此处找到它生成的代码:链接
这是程序的输出:
它竟然能一次性完成如此高难度的任务,真是令人印象深刻。有了 100 万个 token 上下文窗口,我真切地感受到这个模型的强大。
克劳德的回应 3.7 十四行诗
您可以在此处找到它生成的代码:链接
这是程序的输出:
再次,有点失望,它和其他一些法学硕士(LLM)的题目一样,颜色不合格,而且完全解不开魔方。我确实试着帮它找到答案,但没什么用。
概括:
Gemini 2.5 Pro 再次领先。最棒的是,所有测试都是一次性完成的。Claude 3.7 则令人失望,尽管它是目前最好的编码模型之一,但它却没能正确完成这项测试。
3. 球在旋转的四维立方体内弹跳
提示:创建一个简单的 JavaScript 脚本,可视化一个球在旋转的四维超立方体内弹跳的画面。当球与某个侧面碰撞时,高亮显示该侧面以指示撞击。
Gemini 2.5 Pro 的回应
您可以在此处找到它生成的代码:链接
这是程序的输出:
我在输出中没有发现任何问题。球和碰撞物理效果都运行完美,甚至我要求它突出显示碰撞侧的部分也正常工作。这个免费模型的编码能力似乎太差了。🔥
克劳德的回应 3.7 十四行诗
您可以在此处找到它生成的代码:链接
这是程序的输出:
哇,Claude 3.7 Sonnet 终于答对了。它还给每边都加了颜色,不过谁要的呢?🤷♂️ 不过,这里也没什么可抱怨的,因为主要功能看起来运行良好。
概括:
这次答案显而易见。两款机型都给出了正确的答案,实现了我所有的需求。我并不会说我更喜欢 Claude 3.7 Sonnet 的输出,但它确实比 Gemini 2.5 Pro 投入了不少精力。
4. LeetCode 问题
对于这个问题,让我们用 LeetCode 快速检查一下,看看这些模型如何处理一个棘手的 LeetCode 问题(接受率仅为 14.9%):放置 3 个车来求最大值。
Claude 3.7 Sonnet 以擅长解决 LC 问题而闻名。如果你想了解Claude 3.7与Grok 3和o3-mini-high等顶级模型的比较情况,请查看以下博客文章:

Prompt:
You are given a m x n 2D array board representing a chessboard, where board[i][j] represents the value of the cell (i, j).
Rooks in the same row or column attack each other. You need to place three rooks on the chessboard such that the rooks do not attack each other.
Return the maximum sum of the cell values on which the rooks are placed.
Example 1:
Input: board = [[-3,1,1,1],[-3,1,-3,1],[-3,2,1,1]]
Output: 4
Explanation:
We can place the rooks in the cells (0, 2), (1, 3), and (2, 1) for a sum of 1 + 1 + 2 = 4.
Example 2:
Input: board = [[1,2,3],[4,5,6],[7,8,9]]
Output: 15
Explanation:
We can place the rooks in the cells (0, 0), (1, 1), and (2, 2) for a sum of 1 + 5 + 9 = 15.
Example 3:
Input: board = [[1,1,1],[1,1,1],[1,1,1]]
Output: 3
Explanation:
We can place the rooks in the cells (0, 2), (1, 1), and (2, 0) for a sum of 1 + 1 + 1 = 3.
Constraints:
3 <= m == board.length <= 100
3 <= n == board[i].length <= 100
-109 <= board[i][j] <= 109
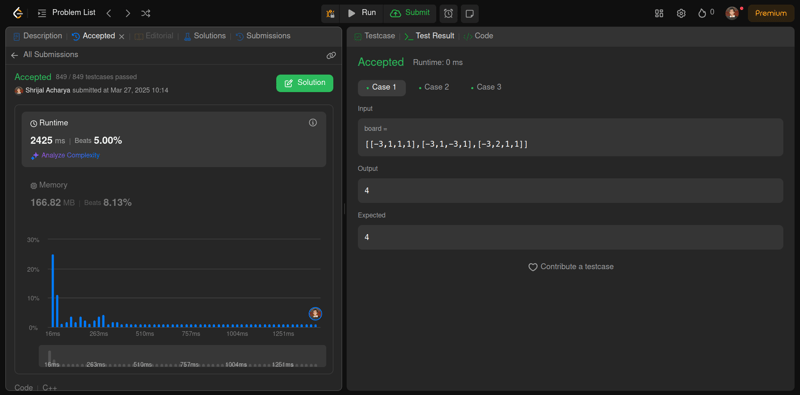
Gemini 2.5 Pro 的回应
💁 我对这个模型寄予厚望,因为它能够轻松回答我们测试的所有三个编码问题。
您可以在此处找到它生成的代码:链接
不过,回答这个问题确实花了不少时间,而且它写的代码也超级复杂,难以理解。我觉得它给出的答案确实比要求的复杂。不过,我们主要还是想看看它能否正确回答。
不出所料,它一下子就答对了这道 LeetCode 难题。这道题是我学习 DSA 时遇到的难题之一。它一下子就答对了,我都有点不开心了。😮💨
克劳德的回应 3.7 十四行诗
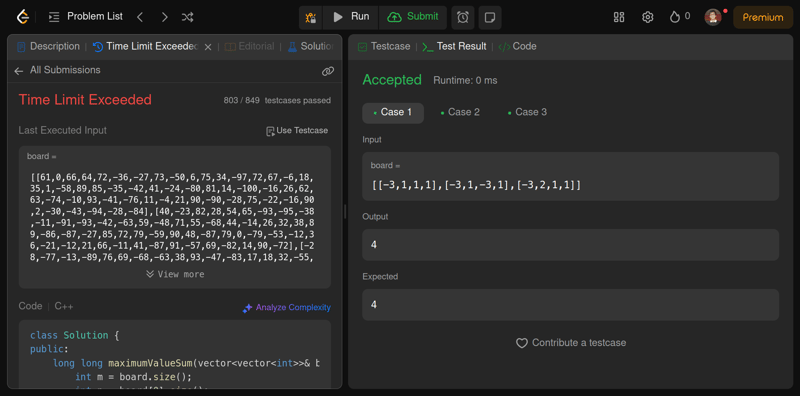
💁 我希望这个模型能够击败这个模型,因为在我做过的所有其他编码测试中,Claude 3.7 Sonnet 都正确回答了所有 LeetCode 问题。
您可以在此处找到它生成的代码:链接
它确实编写了正确的代码但却得到了 TLE,但如果我必须比较代码的简单性,我会说这个模型的代码更简单易懂。
概括:
Gemini 2.5 确实得到了正确的答案,并且也按照预期的时间复杂度编写了代码,但 Claude 3.7 Sonnet 确实陷入了 TLE。如果一定要比较代码的简洁性,Claude 3.7 生成的代码似乎更好一些。
结论
对我来说,Gemini 2.5 Pro 是赢家。我们比较了两个号称编码能力最强的模型。我在模型统计数据中看到的最大区别在于 Gemini 2.5 Pro 的上下文窗口略高,但别忘了,这是一个实验性的模型,改进仍在进行中。
想象一下,在2M 令牌上下文窗口之后,这个模型会有多好?😵
谷歌最近推出了许多坚固的模型,之前是 Gemma 3 27B 模型,这是一款具有令人难以置信的效果的超轻量级模型,现在又推出了这款野兽模型 Gemini 2.5 Pro。
如果您想看一下 Gemma 3 27B 型号的比较,请参见:

你觉得 Gemini 2.5 Pro 怎么样?快在评论区留言告诉我你的想法吧!👇
鏂囩珷鏉ユ簮锛�https://dev.to/composiodev/gemini-25-pro-vs-claude-37-sonnet-coding-comparison-37cp