🔥 Gemma 3 27B 与 QwQ 32B 与 Deepseek R1 对比✅
2025 年 3 月发布了一些新的开源模型,其中两个是阿里巴巴的 QwQ 32B 模型和谷歌的新 Gemma 3 27B 模型,据说它们擅长推理。🤔
让我们看看这些模型彼此之间以及与最好的开源推理模型之一 Deepseek R1 模型之间的比较情况。

而且,如果你已经阅读我的帖子一段时间了,你就会知道,在我亲自测试之前,我不会同意这些基准测试!😉
TL;DR
如果你想直接得出结论,那么当与这三个模型进行比较时,答案并不像其他博客文章中那么明显,QwQ 在编码方面领先,但其他两个模型在推理方面同样一流。
如果用于编码,请选择 QwQ 32B 型号或 Deepseek R1,或者用于其他任何事情,Gemma 3 同样很棒,应该可以完成您的工作。
QwQ 32B型号简介
3 月的第一周,阿里巴巴发布了这款模型大小为 32B 的新模型,声称其能够与模型大小为 671B 的 Deepseek R1 相媲美。🤯
这标志着他们在扩展RL(强化学习)以提高模型推理能力方面迈出了第一步。
以下是他们公开的基准测试,以突出 QwQ-32B 与另一款领先型号 Deepseek R1 相比的性能。
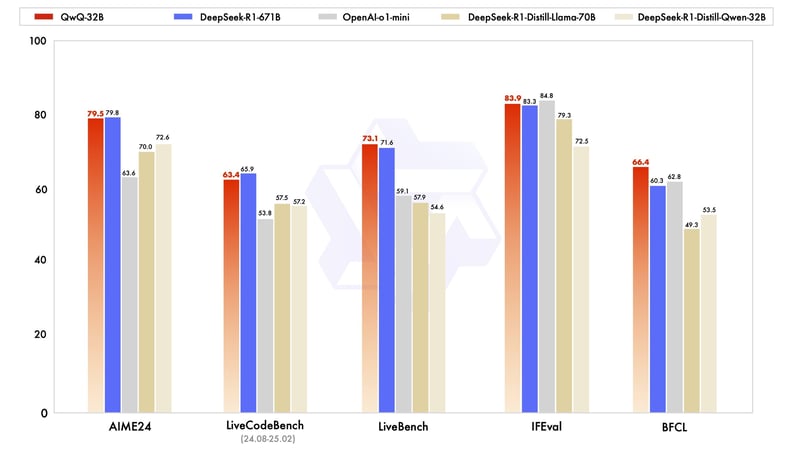
现在,这看起来更有趣了,特别是与大约20 倍大小的模型 Deepseek R1 进行了比较。
Gemma 3 27B 型号简介
Gemma 3 是 Google 基于 Gemini 2.0 全新开源模型。该模型有 4 种不同尺寸(1B、4B、12B 和 27B),但这并不是它真正有趣的地方。
据称它是“可以在单个 GPU 或 TPU 上运行的功能最强大的模型”。🔥 这直接意味着该模型能够在资源有限的设备上运行。
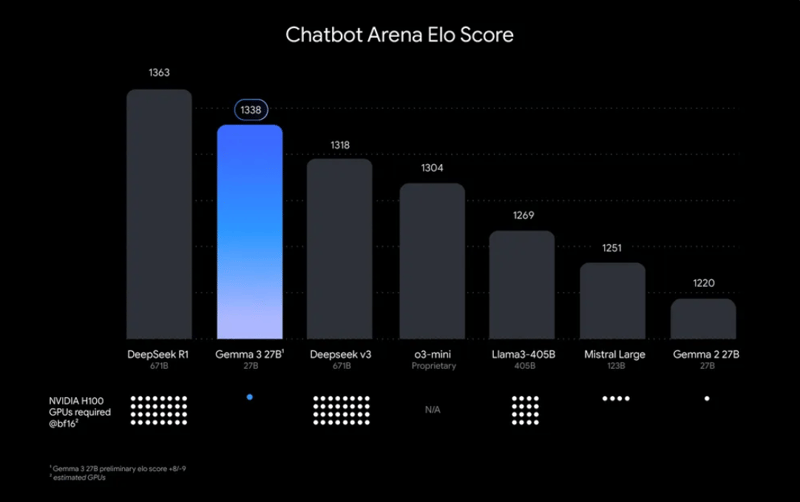
它支持128K 上下文窗口,支持超过140 种语言,主要用于推理任务。
然而,许多人认为 Gemma 3 27B 模型在不同的编码基准测试中表现并不那么出色。
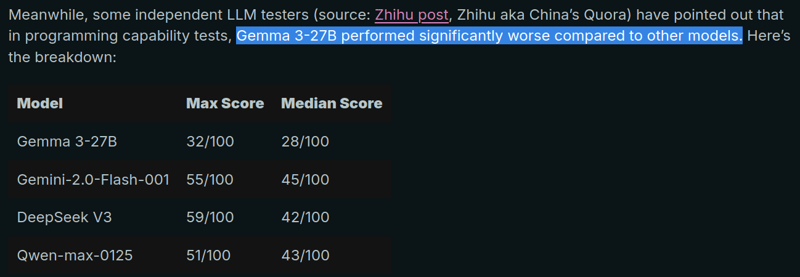
让我们看看事实是否如此,以及该模型的推理能力如何。
编码问题
💁 在本节中,我将通过动画和一道棘手的 LeetCode 问题来测试这三种模型的编码能力。
1. 旋转字母球
提示:创建一个 JavaScript 模拟由字母组成的旋转 3D 球体。距离最近的字母应显示较亮的颜色,而距离最远的字母应显示为灰色。
QwQ 32B 的回复
您可以在此处找到它生成的代码:链接
这是程序的输出:
QwQ 的输出简直太棒了。它完全符合我的要求,从动画到字母旋转,再到颜色变化。一切都恰到好处。太棒了!
Gemma 3 27B 的回复
您可以在此处找到它生成的代码:链接
这是程序的输出:
它似乎没有完全按照我的提示来。肯定有什么东西发生了,但我要求的是一个 3D 球体,结果它似乎只生成了一个旋转的圆环,上面写着字母。
知道这个模型在编码方面并不是那么好,但至少我们得到了一些工作!
Deepseek R1 的回复
您可以在此处找到它生成的代码:链接
这是程序的输出:
它基本上也算正确,完全实现了我的要求。这一点毋庸置疑,但与 QwQ 32B 型号的输出相比,就整体输出而言,它似乎真的没法比。
概括:
在这一部分,毫无疑问,QwQ 32B 模型胜出。它在我们的动画编程测试和 LeetCode 难题中都取得了压倒性胜利。将这些小型模型与模型大小为 671B(每个查询激活 37B)的 Deepseek 进行比较似乎不太公平,但令人惊讶的是,QwQ 32B 在这方面击败了 Deepseek R1。
2. LeetCode 问题
为此,让我们用一个超难的 LeetCode 问题进行快速的 LeetCode 检查,看看这些模型如何解决一个棘手的 LeetCode 问题(接受率仅为 14.4%):强密码检查器。
考虑到这是一个很难的 LeetCode 问题,我对这三个模型都不抱什么希望,因为它们不如 Claude 3.7 等其他一些代码模型那么好。
如果您想了解Claude 3.7与Grok 3和o3-mini-high等顶级型号的比较情况,请查看此博客文章:

Prompt:
A password is considered strong if the below conditions are all met:
- It has at least 6 characters and at most 20 characters.
- It contains at least one lowercase letter, at least one uppercase letter, and at least one digit.
- It does not contain three repeating characters in a row (i.e., "Baaabb0" is weak, but "Baaba0" is strong).
Given a string password, return the minimum number of steps required to make password strong. if password is already strong, return 0.
In one step, you can:
- Insert one character to password,
- Delete one character from password, or
- Replace one character of password with another character.
Example 1:
Input: password = "a"
Output: 5
Example 2:
Input: password = "aA1"
Output: 3
Example 3:
Input: password = "1337C0d3"
Output: 0
Constraints:
1 <= password.length <= 50
password consists of letters, digits, dot '.' or exclamation mark '!'.
QwQ 32B 的回复
您可以在此处找到它生成的代码:链接
太棒了,答案对了。不仅如此,它还能以O(N) 的时间复杂度编写完整个代码,这在预期的时间复杂度范围内。
如果一定要比较代码质量,我会说它还不错。它不仅代码质量好,而且所有文档都写得非常到位。所以,这个模型看起来潜力巨大。
尽管花了很多时间去思考,但真正重要的是可行的答案。
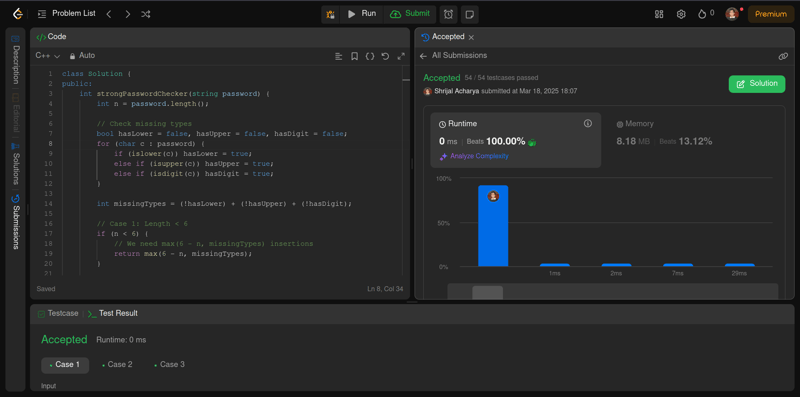
Gemma 3 27B 的回复
您可以在此处找到它生成的代码:链接
好吧,Gemma 3 在这方面做得不够好。它几乎完成了一半,54 个测试用例中有 39 个通过了,但这种错误的代码根本帮不上忙。与其写出糟糕的代码,还不如干脆不写代码。🤷♂️
但考虑到该模型是一个只有 27B 个参数的开源模型,并且在单个 GPU 或 TPU上运行,这是我们可以考虑的一件事。
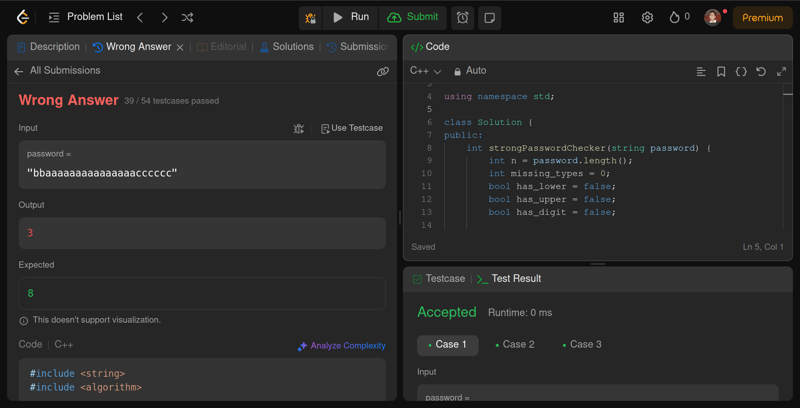
Deepseek R1 的回复
在这个问题上,我几乎不抱任何希望。在我之前的测试中,我将 Deepseek R1 与 Grok 3 进行了比较,结果 Deepseek R1 表现相当糟糕。如果你想了解一下:

您可以在此处找到它生成的代码:链接
太棒了,54 个测试用例中51 个通过,差点就成功了。但即使只有一个测试用例失败,也会导致提交错误,所以 Deepseek R1 这次运气真不好。
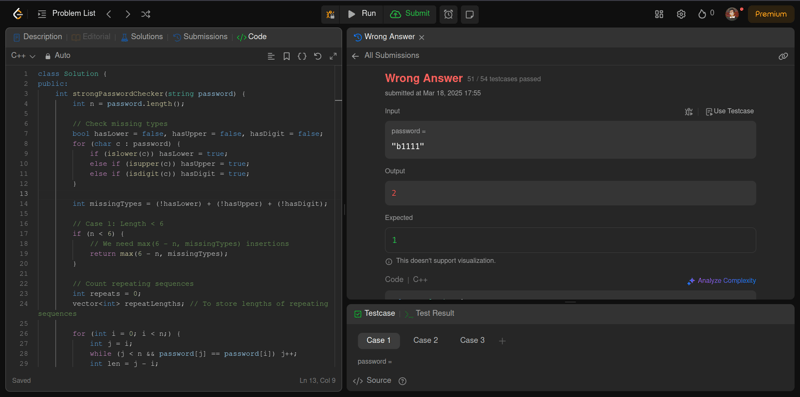
概括:
在两道编程题上比较这三个模型时,结果非常明显。QwQ 32B 模型显然是赢家🔥,Gemma 3 27B 确实尝试过,但绝对不适合用于高级编程。Deepseek 的评价不多,它虽然中等,但足以应付大多数基础到中级的编程问题,因为我每天都会用到它。
推理问题
💁 在这里,我们将检查这两个模型的推理能力。
1.水果交换
我们先从一个非常简单(一点也不棘手)的问题开始,这需要一些常识。不过,我们先看看这些模型是否具备这些常识。
我只是想测试一下这些模型是否能解析所问的问题,推理出所需内容,或者处理所有给出的内容。类似于问“是什么10000*3456*0*1234?”🥱
提示:你一开始有14个苹果。艾玛拿了3个,还给你2个。你丢掉7个,捡起4个。利奥拿了4个,给了你5个。你从艾玛那里拿走1个苹果,和利奥交换了3个苹果,然后把这3个苹果给艾玛,她递给你一个苹果和一个橙子。扎拉拿走了你的苹果,给了你一个梨。你用梨和利奥交换了一个苹果。之后,扎拉用一个苹果换了一个橙子,又用橙子和你交换了另一个苹果。你有多少个梨?直接回答我的问题。
正如您所见,我们用苹果和橘子提供了所有不必要的背景,但对于梨,也就是所要求的,它最后只有一笔交易,导致我们拥有 0 个梨。
QwQ 32B 的回复
你可以在这里找到它的理由:链接
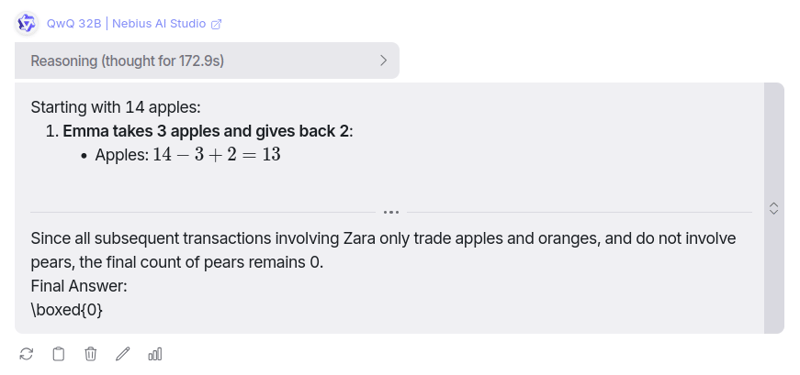
正如我所想,它似乎完全缺乏这种能力。😮💨说真的,它思考了172秒(约2.9分钟),做了所有苹果和橘子相关的计算。QwQ 32B 的这种表现确实令人失望。
Gemma 3 27B 的回复
你可以在这里找到它的理由:链接

只需几秒钟,它就能计算出所有情况并返回梨的总数。这方面没什么可抱怨的。
响应确实非常快,对这个模型印象深刻。
Deepseek R1 的回复
你可以在这里找到它的理由:链接
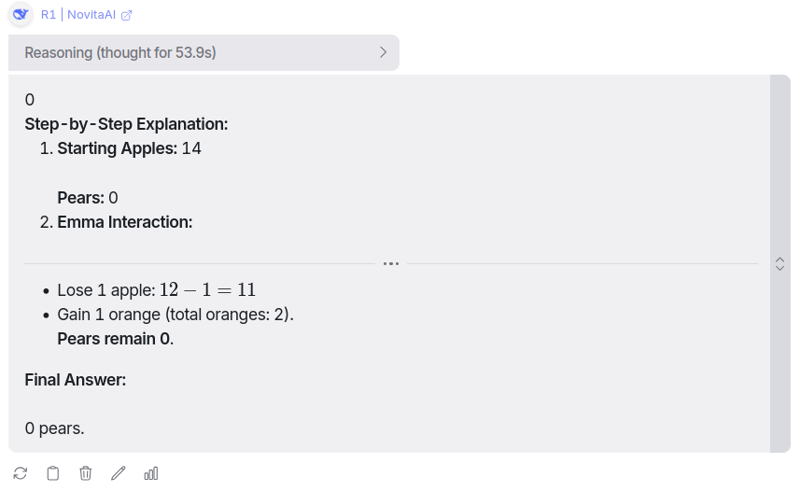
它思考了大约一分钟,终于给出了答案。我原本以为它会给出正确答案,但我只是想看看它能否给出我所问问题的答案,而不用进行那些毫无意义的计算。可惜的是,它也失败了。
概括:
说实话,对于这个问题,我其实并没有刻意寻找正确答案;连一年级学生都能答对。我只是想看看这些法学硕士(LLM)能不能过滤掉所有不必要的细节,只回答题目要求的问题。可惜的是,所有题目都答不出来,尽管我在题目末尾加了一句: “只回答题目要求的问题。” 😮💨
2.电梯里的女人
提示:一位秃顶瘦削的女士住在公寓的78层。晴天时,她会乘电梯到67层,然后步行走完剩下的路程。下雨天时,她会直接乘电梯到她所在的楼层。为什么下雨天她会直接乘电梯到她所在的楼层?
这个问题有点棘手,因为我加入了一些类似的不必要的细节,分散法学硕士(LLM)的注意力,让他们无法轻易找到答案。答案是,这位女士个子矮,夏天够不到按钮,但她带着一把伞,可以用来按更高处的电梯按钮。
答案与女孩是秃头还是瘦子无关。🥴
QwQ 32B 的回复
你可以在这里找到它的理由:链接
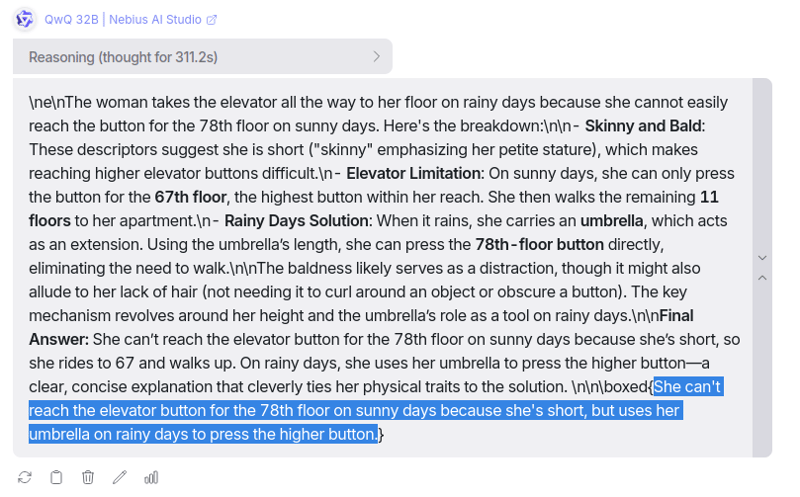
这里花了很长时间,311 秒(~5.2 分钟),而且花了一些时间才弄清楚这与她秃头和瘦弱有什么关系,但在这里,我对反应印象深刻。
它解释思维过程的方式真的令人印象深刻。你或许也想看看。
公平地说,QwQ 32B 确实正确并且完美地解释了一切。✅
Gemma 3 27B 的回复
你可以在这里找到它的理由:链接
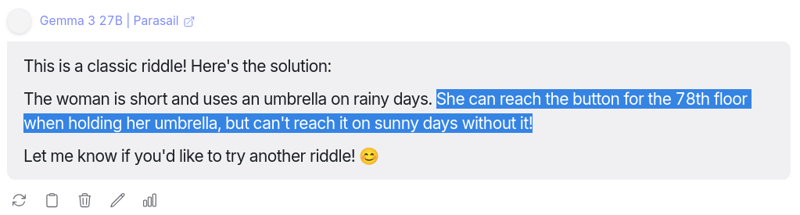
Gemma 3 真的让我震惊,几秒钟内就猜对了。这个模型在推理任务上表现非常稳定。到目前为止,我对这个谷歌开源模型印象深刻。🔥
Deepseek R1 的回复
你可以在这里找到它的理由:链接
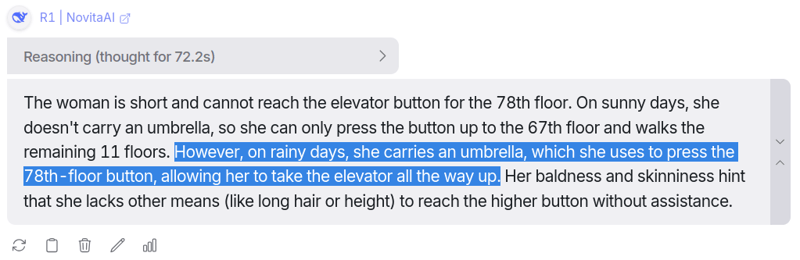
我们知道 Deepseek 在推理任务方面表现非常出色,因此它得出正确答案也就不足为奇了。
花了一些时间才得出答案,大约思考了 72 秒(~1.2 分钟),但我喜欢它每次提出的推理和思维过程。
真的很难理解这个问题与女人秃头和瘦弱有什么关系,但是嘿,这就是我添加它的原因。🥱

概括:
毫无疑问,这三个模型都非常擅长推理问题。我尤其喜欢 QwQ 32B 和 Deepseek R1 模型解释其思维过程的方式,以及 Gemma 3 回答这两个问题的速度之快。这三个模型都能得到 10/10 的答案✅,但 QwQ 32B 有时可能会让人觉得它的推理有些不必要。🤷♂️
数学问题
💁 查看了这三个模型的推理问题答案,我确信这两个模型也应该通过数学问题。
1. 钟针呈直角
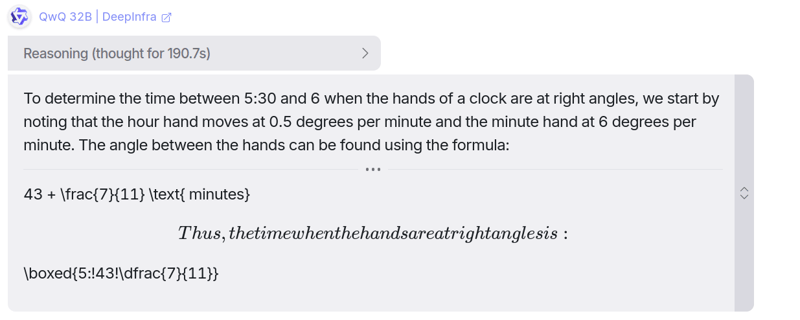
提示:在 5:30 到 6 点之间,什么时候时钟的指针会成直角?
QwQ 32B 的回复
你可以在这里找到它的理由:链接
Gemma 3 27B 的回复
你可以在这里找到它的理由:链接
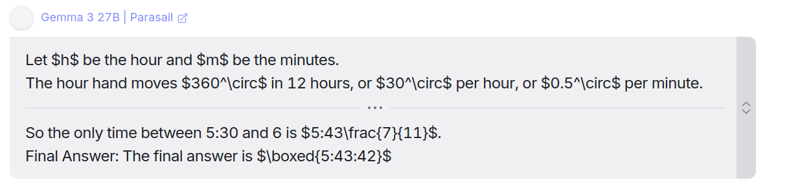
除了编程题,Gemma 3 也答对了这道题,并且在我提到的所有推理和数学题上都取得了压倒性的优势。这真是一个精巧却强大的模型。
真的印象深刻!🫡
Deepseek R1 的回复
你可以在这里找到它的理由:链接

从我的这篇比较 Deepseek R1 和 Grok 3 的文章中,我们已经可以清楚地看到 Deepseek 在数学方面的表现有多好,所以我对这个模型寄予厚望。
和往常一样,它也答对了这道题。它确实经过了一番漫长的推理和思考才得出答案,但它最终还是找到了答案。
概括:
这三个模型在推理和数学方面都表现得非常出色。它们全都答对了。Gemma 3 27B 很快就搞定了,另外两个模型 QwQ 32B 和 Deepseek R1 也凭借正确的推理能力取得了优异的成绩。✅
2. 字母排列
提示:单词“MATHEMATICS”的字母可以有多少种不同的排列方式,使得元音总是连在一起?
这是向法学硕士 (LLM) 提出的一个经典数学问题,所以让我们看看这三个模型的表现如何。
QwQ 32B 的回复
你可以在这里找到它的理由:链接
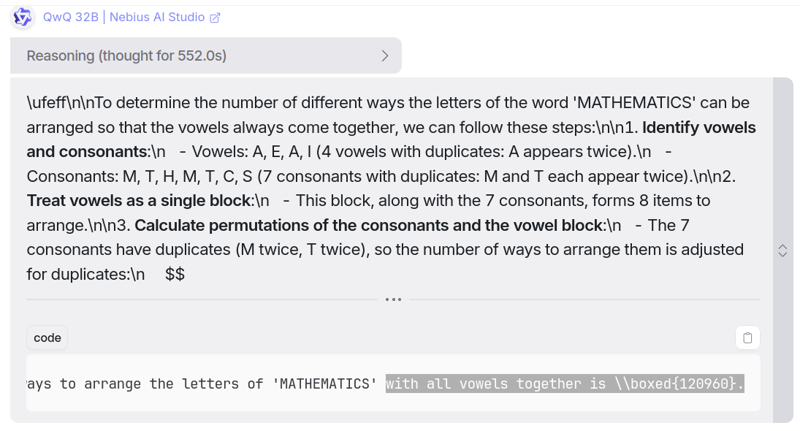
经过 552 秒(~9.2 分钟)🥱 的思考,是的,它确实花了那么长时间才想出答案,但一如既往,它也回答了这个问题。
我同意它所有的推理过程感觉又长又无聊,但如果它能完成任务,那也是好的一面。QwQ 32B 模型看起来真的很扎实,到目前为止,所有问题都迎刃而解。🔥
Gemma 3 27B 的回复
你可以在这里找到它的理由:链接

完全正确。这个模型的响应速度和准确性令人惊叹。谷歌在这个模型上做得确实很棒,这一点毋庸置疑。😵
Deepseek R1 的回复
你可以在这里找到它的理由:链接
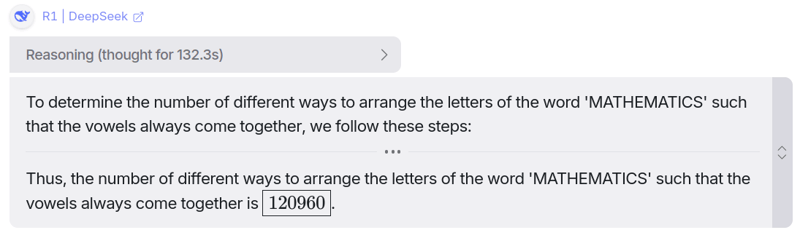
经过大约 132 秒(~2.2 分钟)的思考,它终于得出了答案,而且再次是 Deepseek R1 的正确答案。
概括:
这次的答案也显而易见。我们三个模型都完美地解决了这个问题,并给出了完美的解释和推理。对于这么难的问题,三个模型都能给出令人印象深刻的答案,而对我来说,Gemma 3 27B 的表现尤为突出。多么轻量级的实体模型啊!🔥
结论
结果一目了然。对我来说,经过这么一番比较,如果一定要选一个模型,我还是会选择Deepseek R1。QwQ 32B 模型表现非常出色,可以说是本次比较的绝对赢家。✅ 其他一些测试这些模型的人似乎也得出了同样的结论。👇

但对我来说,Deepseek R1 模型感觉像是一个具有平衡推理和整体响应时间的最佳点。
虽然 Gemma 3 和 Deepseek R1 无法完全正确解答编码问题,但它们的整体推理能力实在是太棒了。Gemma 3 27B 模型给我留下了深刻的印象。它绝对是你工具箱里必备的一款模型。
你怎么看?在下面的评论区留言告诉我你的想法吧!👇
鏂囩珷鏉ユ簮锛�https://dev.to/composiodev/gemma-3-27b-vs-qwq-32b-vs-deepseek-r1-comparison-4o90