使用六边形架构编写可测试的无服务器应用程序并防止供应商锁定
无服务器最可怕的是什么?这个问题的答案取决于你问的人和时机。
在无服务器发展的早期,人们会提到长时间运行的任务。然而,随着 AWS Lambda 15 分钟超时、AWS Fargate 以及许多其他公告的发布,这个问题已经得到解决。医疗应用开发者以及其他处理敏感数据的行业人士可能会提到合规性,但无服务器提供商正在定期为其平台添加对各种合规性的支持。二进制文件和大型依赖项怎么办?这是一个令人恼火的问题,但 AWS 推出了 Lambda Layers。冷启动?如果您仍然遇到冷启动问题,您可以考虑使用 VPC(一种比较特殊的技术),或者我们正在以完全不同的方式使用无服务器。如果您在 VPC 中运行 Lambda 函数,AWS 有个好消息要告诉您。
也许 Node.js?开玩笑的,我超爱 Node.js!
然而,无论您是在与后端开发人员、系统架构师还是商务人员交谈,总会出现一件事,并且通常会伴随几秒钟的沉默。

那么,大型不良供应商锁定又如何呢?
什么是供应商锁定?
如果几秒钟的沉默没有吓跑你,你可以问自己,那个神秘的供应商锁定到底是什么?
如果你查看维基百科,你会看到以下定义:
从经济学角度来看,供应商锁定使得客户依赖于某个供应商的产品和服务,如果不付出大量的转换成本就无法使用其他供应商的产品和服务。
正如所有定义一样,这句话要么太枯燥,让人昏昏欲睡,要么会引出很多其他问题。其中一个后续问题可能是“云计算中的供应商锁定是如何运作的?”
假设你需要一台服务器。我不知道你为什么这么做,你很奇怪,但目前这并不重要。
所以你需要一台服务器。你可以购买或租用。你或许可以尝试从零开始搭建,但要做到这一点,你必须先创造一个完整的宇宙,而这远远超出了本文的讨论范围。

假设你足够理智,决定租用一台服务器。你找到一个拥有多台服务器的人,我们叫他杰夫,然后从他那里租了一台服务器。因为你比较古怪,所以你把这台服务器叫做“云”,但实际上,它只是杰夫地下室里一台普通的服务器。

Jeff 很聪明,他知道你和其他一些奇葩是怎么用他的服务器的。鉴于你们大多数人都有数据库,他推荐了云数据库服务。存储、计算,甚至机器学习服务也一样。
由于 Jeff 的客户数量足够多,他决定按实际使用量收费。这意味着您只需为实际使用的服务付费。我是不是应该说,您一定很喜欢他的服务?

但是,如果杰夫是个恶棍怎么办?
也许他只是在等你完全接受他便宜又美观的云服务,并将其深入到你的 Web 应用的业务逻辑中。然后,几秒钟的沉默之后,他突然大幅提高了服务价格。

如果真是这样,我猜你不会再喜欢 Jeff 的云了。你的钱包也不会高兴。
幸运的是,事情还没完!还有一个人拥有很多服务器,我们叫他比尔吧。他还拥有一些云数据库、计算、存储和其他类似的服务。比尔的服务也是按使用量收费的,看来你的应用可以在比尔的地下室里正常运行,你也会再次感到满意。

新的希望出现了。你能把你的应用搬到比尔的地下室吗?对不起,云端?
可以。不过,这并不容易,因为 Bill 的数据库服务与 Jeff 的数据库服务的工作方式不同。其他托管服务也一样。要将您的应用迁移到 Bill 的服务器,您需要进行一些调整。
你还记得你觉得测试太繁琐、不需要自动化测试的那一刻吗?还有,你为了能快几个小时完成一些非关键功能,在应用程序架构上偷工减料的那些时刻吗?
现在,您做出的所有错误决定都使得迁移的成本比将您的应用程序保存在 Jeff 的地下室中还要高。
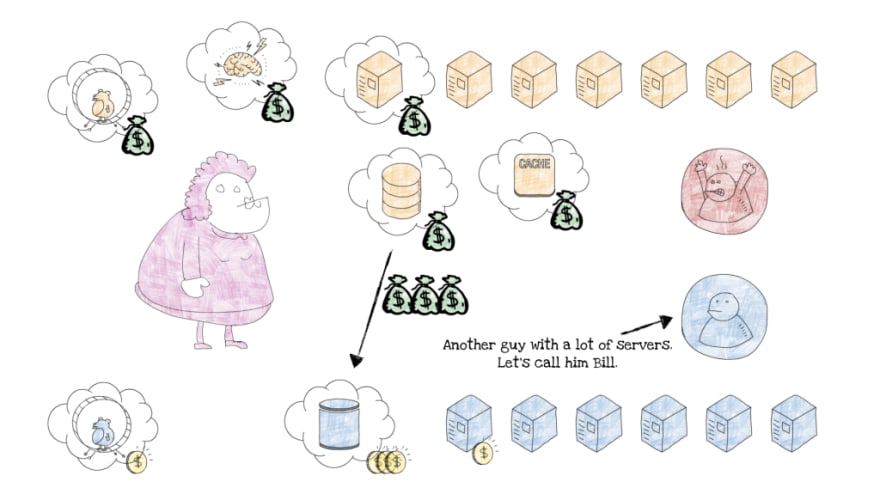
好吧,那一刻你就会意识到云供应商锁定的真正含义。
如何对抗供应商锁定?
那么,该如何对抗供应商锁定呢?大多数情况下,对抗供应商锁定的方法就如同对抗床下怪物一样。
第一步是直面你的恐惧,并给它们一个正确的名字。在云端,供应商锁定的正确名称是转换成本。正如 AWS 企业战略师 Mark Schwartz 在其精彩文章《转换成本与锁定》中所说:
我的思路是这样的:“锁定”这个词有点误导。我们真正讨论的是转换成本。
是吗?我引用马克文章中的另一句话来回答:
在整个 IT 发展史上,转换成本一直存在。一旦你选择了一个平台或供应商,如果之后决定更换,就需要承担转换成本。如果你选择 Java,然后迁移到 Node.js,你也需要承担成本。
我的经历也类似。在我们的产品Vacation Tracker中,我们做了很多改动。我们将应用的大部分数据从 MongoDB 迁移到了 DynamoDB,将部分 Express.js 代码迁移到了 AWS 上的无服务器架构,还彻底更换了一些服务。我们是否存在供应商锁定的问题?有时确实如此!不过,这是我们的选择,而且可能并非你想象中的供应商锁定。
尽管我们的应用在 AWS 上几乎 100% 无服务器,但我们并不存在云供应商锁定的问题。然而,我们的应用与 Slack 深度集成,有时,Slack 平台上哪怕最细微的改动都会影响我们的产品。
那么,我们该如何应对云供应商锁定呢?首先,我们可以通过问自己一个正确的问题来应对——如何将转换成本保持在合理的低水平?
为了降低迁移成本,我们需要从更完善的规划开始。我们的迁移成本应该有多低?这取决于我们需要迁移到其他平台的可能性有多大。到目前为止,AWS 已将其云服务价格下调了 15 次以上,而且从未提高过任何产品的价格。我认为他们大幅提价的可能性并不高。即使他们真的提价,我们的基础设施成本上涨 100 倍,我们每月也只需支付不到 100 美元。我们真的有必要在意这些吗?
如果风险足够高,需要提前规划,那么迁移成本是多少?成本取决于你的架构,但就我们的情况而言,花几周时间进行迁移不会对我们的业务造成重大影响,所以我认为我们的迁移成本相当低。
完成初步规划后,就该考虑一些良好的架构实践和部署流程了,这些实践和流程可以帮助您改进应用程序,并减少未来必要的迁移工作量和成本。部署流程超出了本文的讨论范围,我们可能会在以后的文章中讨论(您可以随时在 Vacation Tracker 网站上订阅我们的新闻通讯),但即使是部署流程,通常也取决于良好的应用程序架构以及应用程序的可测试性。
使用六边形架构设计可测试的无服务器应用程序
我提到了测试,但如果你的应用程序是无服务器的并且可以自动扩展,为什么还需要测试呢?你的基础设施可能完全托管,但你的业务逻辑和代码却并非如此。你的无服务器应用程序中可能会出现 bug,而且肯定会出现。区别在于,这些 bug 不会破坏你的基础设施,但它们可以自动扩展。
大多数情况下,无服务器应用程序并非完全孤立的单体应用,无需集成。相反,它们包含许多彼此交互且与外部依赖项交互的服务。例如,我们的应用程序与 Slack 深度集成,集成的核心部分如下图所示。Slack 将 Webhook 事件发送到 API 网关。然后,我们将它们路由到处理不同场景的不同 Lambda 函数,例如,用于处理斜线命令的 Slack 斜线命令处理程序,或用于响应 Slack 中按钮操作的消息操作处理程序。Lambda 函数处理事件,将事件推送到 Amazon Simple Notification Service (SNS) 主题,并回复 Slack。然后,我们的业务逻辑从 SNS 主题获取消息并对其进行处理。
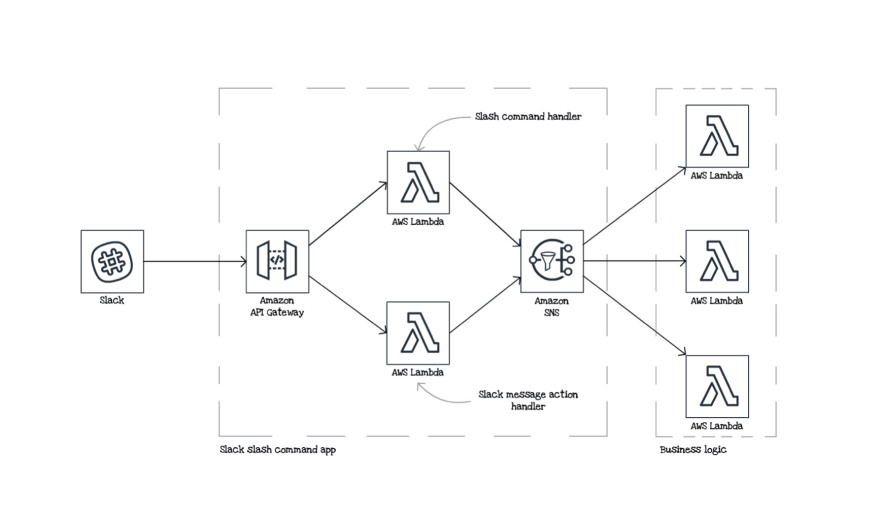
只要其中一个环节出现问题,我们的业务逻辑就无法正常运行。此外,当你的应用中有很多小型服务时,任何集成都可能随时发生变化,无论是在下次部署时,还是在外部依赖项发生变化时。测试并不能阻止这些变化,但至少可以确保你的更改不是意外的。
但是,如何知道应该在无服务器应用中测试什么呢?这是一个很大的话题,您可以在我之前关于测试无服务器应用程序的文章中阅读更多相关内容。
测试金字塔是一个很好的开端。它现在还适用吗?是的,它仍然适用。它和以前一样吗?不一定,因为自动化测试比以前更便宜了。现在您可以在几秒钟内创建一个新的 DynamoDB 表,然后在运行测试后将其删除。或者,您可以保留它,因为您只需为实际使用付费(除非您在测试期间存储了大量数据)。应用程序的其他部分也一样。您可以在几分钟内创建生产应用程序的精确副本,并且运行完整的端到端测试套件的成本可能不到几美分。

然而,更快、更便宜的测试并不是唯一的区别。集成测试更便宜,但也更为关键,因为常见的无服务器应用程序会被拆分成许多小块。
什么使无服务器应用程序可测试
每个应用程序都是可测试的,但有些应用程序的编写方式使得自动化测试异常困难且成本高昂。这正是您在应用程序中应该避免的情况,因为缺乏自动化测试会使您的切换过程更加复杂。
这时,您的应用架构就能发挥作用,扭转乾坤。您无需重新发明轮子;许多优秀的应用架构已经存在数年甚至数十年了。哪一种架构才适合您的无服务器应用呢?
任何能够轻松测试应用并降低迁移成本的架构都是完美的。因为你迟早都需要迁移应用的各个部分。迁移的不是其他云供应商,而是新的服务,或者一些新的或变更的集成。
与任何其他应用程序一样,无服务器应用也存在一些需要考虑的风险。正如我的朋友兼合著者 Aleksandar Simovic 在我们的著作《基于 Node.js 的无服务器应用程序》中所解释的那样,在构建应用架构时,您应该考虑以下四个风险:
- 配置风险;例如,DynamoDB 表是否正确以及您是否有访问权限?
- 技术工作流程风险;例如,您是否正确解析和使用传入的请求?
- 业务逻辑风险;或者您的应用程序逻辑是否按应有的方式运行?
- 集成风险;例如,您是否将数据正确地存储到 DynamodB 表中?
您可以使用端到端测试来测试大多数此类风险。但是,想象一下,如果以这种方式测试一辆新车,您需要组装整辆车才能测试雨刷器是否正常工作。
端口、适配器和架构
如果你经常旅行,你肯定知道电源插头有多麻烦。如果你从欧洲去北美,你根本没法直接把笔记本电脑插到电源插座上。它们不兼容。
然而,每次出国都要买一根新的电源线,既贵又没意义。好在你可以买个小适配器,让你的电源线兼容世界各地的电源插座。

您的应用程序应该以相同的方式工作。您的业务逻辑是否关心将数据存储到 MongoDB 还是 DynamoDB?不一定。但是,您的数据库适配器应该关心这一点。
这就引出了我最喜欢的无服务器应用架构:六边形架构,也称为端口和适配器。正如其创始人 Alistair Cockburn 所解释的那样,六边形架构允许应用程序由用户、程序、自动化测试或批处理脚本平等驱动,并且可以在独立于最终运行时设备和数据库的情况下进行开发和测试。
根据定义,这种架构似乎非常适合无服务器,因为在开发过程中几乎不可能在本地模拟整个最终运行时。
假设您有一个服务,它会接收一些通知,解析通知,将数据保存到数据库,然后向 SNS 主题发送另一个通知。对我们来说,这是一种典型的模式。例如,当我们将休假申请保存到数据库时,我们还会向 SNS 主题发送一条消息,然后触发另一个服务通过 Slack 向经理发送请求。
该服务没有将所有东西捆绑在一起,而是采用简单的业务逻辑,仅负责协调其他服务。该服务的核心公开了三个端口:
- 传入事件的端口
- 用于将数据保存到数据库的端口
- 发送通知的端口
然后我们有不同的适配器,例如,一个用于将通知发送到 Amazon SNS 主题以进行生产,另一个适合同一端口以在测试期间发送本地通知。
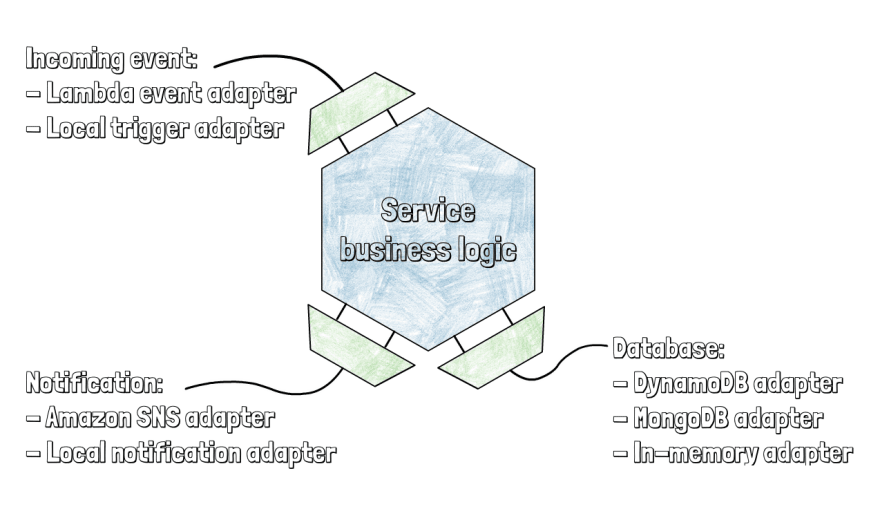
正如我在另一篇有关六边形架构的文章中所解释的那样,我们的最小代码示例分为以下两个文件:
- 该
lambda.js文件连接依赖关系并且没有测试。 - 该
main.js文件包含业务逻辑。
还记得我们的 Slack 流程吗?让我们在实践中看看其中一个功能,例如 Slack 斜线命令处理程序。

此函数中的文件lambda.js将 SNS 通知存储库作为依赖项,并使用main.js它调用函数以及接收到的事件。我们对来自 的函数进行了单元测试和集成测试main.js,但从未针对 Amazon SNS 进行过测试。为什么?因为我们从许多不同的服务向多个 SNS 主题发送消息。如果我们针对 Amazon SNS 测试每个服务,这将花费大量时间,而且我们的大多数测试都是多余的,因为我们会反复检查我们的 SNS 存储库及其依赖项 AWS SDK 是否正常工作。
相反,我们针对与相同通知端口兼容的本地通知适配器测试了我们的main.js功能。然而,在 SNS 通知存储库的集成测试中,我们测试了与 Amazon SNS 的集成,以确保其按预期运行。

但是,我们如何在代码中编写端口和适配器呢?很简单!
我们的main.js函数接收一个通知存储库实例作为参数。该实例可以是任何与通知端口兼容的通知存储库,而不仅仅是 Amazon SNS 适配器。
另外,通知端口是什么?它只是.send通知存储库的一种方法。我们的main.js文件将尝试通过调用以下函数来发送消息:notification.send(message)。任何能够满足此请求的东西都是兼容的适配器。
我们的 SNS 通知是一个公开send发送消息方法的类。这就是适配器。
该lambda.js文件类似于以下代码片段:
// Dependencies
const {
parseApiEvent,
SnsRepository
} = require('../common')
const httpResponse = require('@vacationtracker/api-gateway-http-response')
// Business logic
const main = require('./main')
async function handler(event) {
// Parse API event
const { body, headers } = parseApiEvent(event)
// Create an instance of SNS notification repository
const notification = new SnsRepository(
process.env.topic
)
// Invoke the main function with all dependencies
await main(body, headers, notification)
// Return status an empty 204 response
return httpResponse()
}
我们的文件中最重要的部分lambda.js是以下行:
await main(body, headers, notification)
通过这种方法,我们可以轻松地为业务逻辑编写自动化测试。在单元测试中,我们main用一些静态值调用函数body,headers并模拟通知适配器。然后,我们检查模拟调用是否使用了正确的数据。

在集成测试中,我们main使用一些静态的body和headers以及本地通知存储库的实例来调用该函数。本地通知存储库可以是原生 JavaScript 事件的简单包装器。

如果您想了解有关测试无服务器应用程序的更多信息并查看代码示例,请查看我们在 Senzo Homeschool 平台上的新课程(第一门课程于 2020 年 6 月 22 日星期一开始):

那么供应商锁定又如何呢?
是的,那又怎么样?啊,对了,我们刚才谈到了供应商锁定!所以你可以问,六边形架构如何帮助对抗供应商锁定。
选择错误的数据库似乎会导致严重的供应商锁定,对吧?我们轻松地将大部分应用程序从 MongoDB 迁移到了 DynamoDB。
我们的应用与数据库的集成方式与它与 Amazon SNS 集成的方式相同:使用数据库存储库。我们的应用曾经使用过 MongoDB 存储库,该存储库包含单元测试和集成测试。
一旦我们决定迁移到 DynamoDB,我们就会为 DynamoDB 创建另一个适配器并将其命名为dynamodb-repository.js。此存储库具有与 MongoDB 相同的接口,例如,如果要删除假期,则需要调用以下函数:db.deleteVacation(params)。MongoDB 存储库将在 MongoDB 中删除假期,而 DynamoDB 存储库将在 DynamoDB 中删除它。
在迁移过程中,我们同时将服务连接到两个存储库,并开始逐一切换集成。迁移完成后,我们从服务中移除了 MongoDB 集成。

超越测试
总有一些事情是无法测试的。例如,你与谷歌集成,他们在没有适当通知的情况下更改了 API。我们发现 Slack 多次更改其应用行为,甚至没有记录在案。
有些集成更改很难察觉,例如,当 Slack 决定在移动布局中只显示 5 个附件时,我们的日历就乱套了,但我们的应用程序仍然正常运行。然而,大多数此类更改都会开始在您的应用程序中引发许多错误。
您无法对抗第三方依赖项的意外变化,它们会发生,但您可以并且应该监控应用程序的前端和后端,并在变化破坏应用程序的某些部分时快速做出反应。
如果您的无服务器应用程序运行在 AWS 上,那么有各种优秀的服务可以帮助您监控它。您可以使用内置工具(例如 Amazon CloudWatch 和 AWS X-Ray),也可以使用一些第三方应用程序(例如IOpipe、Epsagon、Thundra、Lumigo等等)。
继续阅读 https://dev.to/aws-heroes/writing-testable-serverless-apps-and-preventing-vendor-lock-in-using-hexagonal-architecture-3mi5