使用 Ollama API 运行 LLM 并在本地生成响应
Ollama 允许我们在系统本地运行开源大型语言模型 (LLM)。如果您的系统尚未安装Ollama并且不知道如何使用,建议您阅读我的Ollama 初学者指南。它将指导您完成 Ollama 的安装和初始步骤。
在本文中,我将分享如何使用 Ollama 提供的 REST API 来运行 LLM 并生成响应。我还将展示如何使用 Python 以编程方式从 Ollama 生成响应。
步骤
- Ollama API 托管在本地主机的端口 11434 上。您可以前往本地主机检查 Ollama 是否正在运行。
- 我们将在终端中使用 curl 向 API 发送请求。
curl http://localhost:11434/api/generate -d '{ "model": "llama2-uncensored", "prompt": "What is water made of?" }'这里我使用的是 llama2-uncensored 模型,但您可以使用通过 Ollama 下载的任何可用模型。我们还可以发送更多参数,例如 stream,当设置为 false 时,将仅返回单个 JSON 对象作为响应。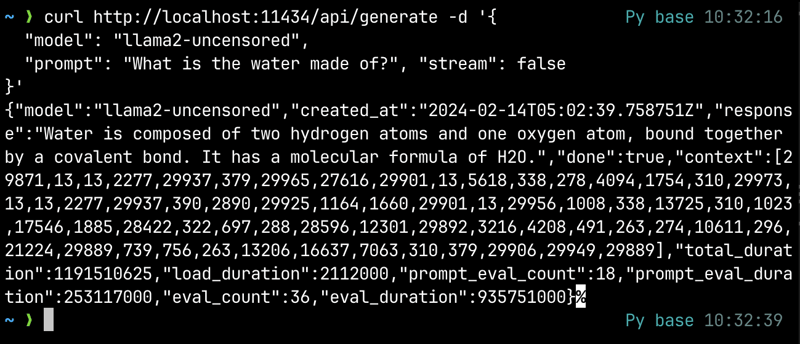
- 现在,正如我们所见,该
/api/generate端点用于针对给定的提示生成响应/完成。我们可以使用各种端点来实现不同的目的。您可以在Ollama 的API 文档中查看它们。
使用 Python 通过 Ollama API 生成响应
现在我们了解了 Ollama 提供的 REST API,我们可以使用 Python 以编程方式生成响应。
- 创建一个 python 文件。导入请求和 json 库。
import requests import json - 创建 url、headers 和 data 变量,其值如下图所示

- 现在使用响应库的 post 方法,并传入我们上面创建的 url、headers 和 data 变量。将响应存储在变量中。
response = requests.post(url, headers=headers, data=json.dumps(data)) - 现在检查响应的状态码。如果是 200,则打印响应文本,否则打印错误。我们可以从 JSON 对象中提取准确的响应文本,如下图所示。

- 运行程序:)
完整的代码快照附在下面。
结论
按照上述步骤,您将能够使用 Ollama 的 REST API 在本地运行 LLM 并生成响应。现在,您可以使用 Python 以编程方式从 LLM 生成响应。Ollama 是一款非常棒的工具,我非常感谢这个项目的创建者!
文章来源:https://dev.to/jayantaadhikary/using-the-ollama-api-to-run-llms-and-generate-responses-locally-18b7