使用 Lucene.NET 在 Blazor WebAssembly 中实现搜索
我写博客的主要原因之一是记录我学到的东西,这样以后就可以回顾,而不必全部记在脑子里。这样做的好处是,遇到同样问题的人可以看到我是如何解决的,所以这是一个双赢的结果。但是,当我将网站转换为静态网站时,意味着我不得不牺牲一项功能——搜索。当然,市面上有很多相当不错的搜索引擎,比如谷歌和必应,我经常用它们,但我一直认为,有一天能重新整合它们也不错。
过去几年,我一直在使用Lucene.NET,尤其是它与 Umbraco 的集成。我也读过好几遍《Lucene in Action》,所以一直在想“把 Lucene 放到我的网站上会不会很酷”。但是 Lucene 是用 Java 编写的,Lucene.NET 是……嗯…….NET,而且它的 JavaScript 实现功能都不如我想要的那么完善,所以 Lucene 一直被搁置着……直到现在!
Blazor
在最近的一次会议上讨论之后,我决定是时候重新审视一下Blazor了。我以前也尝试过,但只是看看它的Hello World 演示,所以我决定尝试一些更复杂的东西。
如果您之前没接触过 Blazor,Blazor 是一款使用 C# 和 Razor 构建 Web UI 的工具。随着 .NET 3.0 的发布,Blazor Server也正式发布。Blazor Server 的工作原理是在服务器上生成 HTML,然后使用SignalR将其推送到浏览器,并为您处理所有 JavaScript 互操作。您可以通过 C# 连接 JavaScript 事件,构建一个动态的 Web 应用程序,而无需编写任何 JavaScript 代码!
虽然 Blazor Server 很酷,但我对 Blazor 的另一种风格Blazor WebAssembly更感兴趣。在撰写本文时,Blazor 的 WebAssembly(WASM)版本处于预览阶段,需要您安装 .NET Core 3.1 预览版(我正在使用Preview 3)。与 Blazor Server 的区别在于,我们不是使用 SignalR 运行服务器连接并在服务器端生成 HTML,而是使用 WASM 版本的 Mono 运行时编译我们的 .NET 应用程序,然后将其完全在浏览器中运行。这对我的静态博客来说是完美的,我最终得到的东西只有 HTML、CSS 和 JavaScript……等等,实际上它有一些 JavaScript、一些 WASM 字节码和 .NET DLL!
创建我们的搜索应用程序
让我们看看如何使用 Lucene.NET 作为引擎来开发一个搜索应用。目前,我们将把它与静态网站分开创建,但在以后的文章中,我们将尝试将其集成到其中。
步骤 1 - 创建可搜索内容
我们需要一些内容来搜索,而如何获取这些信息则取决于你集成的系统类型。你可能需要从数据库中提取一些产品数据,可能需要调用 REST API,或者像我的情况一样,我有大约 400 篇博客文章(并且还在不断增加!)需要索引。
对于我来说,实现这一点的最简单方法是生成我的博客文章的机器可解析版本,我将以 JSON 的形式执行(我的 RSS 提要已经有 XML,但在 .NET 中解析 JSON 要容易得多),因此 Hugo 需要更新以支持这一点。
首先,需要将 JSON 添加到config.toml网站的 Hugo 输出中:
[outputs]
home = ["HTML", "RSS", "JSON"]
然后我们可以创建一个布局来在您的站点文件夹中生成 JSON layout:
{
"posts": [
{{ range $i, $e := where (.Data.Pages) ".Params.hidden" "!=" true }}
{{- if and $i (gt $i 0) -}},{{- end }}{
"title": {{ .Title | jsonify }},
"url": "{{ .Permalink }}",
"date": "{{ .Date.Format "Mon, 02 Jan 2006 15:04:05 -0700" | safeHTML }}",
"tags": [{{ range $tindex, $tag := $e.Params.tags }}{{ if $tindex }}, {{ end }}"{{ $tag| htmlEscape }}"{{ end }}],
"description": {{ .Description | jsonify }},
"content": {{$e.Plain | jsonify}}
}
{{ end }}
]
}
我在网上找到了这个模板,它遍历所有可见的帖子来创建一个如下所示的 JSON 数组(我的博客大约有 2mb 的 JSON!):
{
"posts": [
{
"title": "Combining React Hooks With AppInsights",
"url": "https://www.aaron-powell.com/posts/2019-11-19-combining-react-hooks-with-appinsights/",
"date": "Tue, 19 Nov 2019 11:40:02 +1100",
"tags": ["react", "azure", "javascript"],
"description": "A look at how to create a custom React Hook to work with AppInsights",
"content": "<snip>"
}
]
}
第 2 步 - 设置 Blazor
正如我上面提到的,您需要安装.NET Core 3.1 SDK才能使用 Blazor WebAssembly,而我使用的是 Preview 3(3.1.100-preview3-014645具体来说是 SDK)。
让我们首先创建一个解决方案和 Blazor 项目:
dotnet new sln --name Search
dotnet new blazorwasm --name Search.Site.UI
dotnet sln add Search.Site.UI
dotnet new classlib --name Search.Site --language F#
dotnet sln add Search.Site
Blazor 项目Search.Site.UI将仅包含.razor文件和引导代码,其余逻辑将被推送到Search.Site我用 F# 编写的单独类库中。
注意:有一个完整的 F#-over-Blazor 项目叫做Bolero,但它使用的是 Blazor 的旧版本。我不太喜欢像 Bolero 那样的 F#-as-HTML 模式,我更喜欢 Razor 的绑定方式,所以我会做一个混合语言解决方案。
Pages现在,我们可以通过删除和文件夹中的所有内容来删除 Blazor 示例站点Shared,因为我们将自己创建所有内容,并使用一个名为的空默认页面Index.razor:
@page "/"
<h1>TODO: Searching</h1>
还有一个原始的MainLayout.razor(在Shared文件夹中):
@inherits LayoutComponentBase
@Body
您可能想知道为什么它MainLayout.razor如此基础,原因是当将它集成到我们的更大的网站时,我们希望 Blazor 应用程序注入最少量的 HTML 和样式,而是从托管网站使用它,但今天我们将从文件中获取其中的一些wwwroot/index.html。
步骤 3 - 启动 Blazor UI
在考虑烦人的后端之前,我们先来构建搜索的 UI。UI 会处理一些事情,首先,它会在搜索索引构建时显示一条消息(基本上是一个加载屏幕);索引构建完成后,它会显示一个搜索框;当执行搜索时,它会显示结果。
在 Blazor 中,我们将组件用于页面(以及放在页面上的内容,但自定义组件超出了我将介绍的范围),它们可以具有如下内联代码:
@page "/"
<p>The time is: @Time.ToString("dd/MM/yyy hh:mm:ss")</p>
@code {
public DateTimeOffset Time => DateTimeOffset.Now;
}
或者它们可以从这样的组件类继承:
@page "/"
@inherits TimeComponent
<p>The time is: @Time.ToString("dd/MM/yyy hh:mm:ss")</p>
public class TimeComponent : ComponentBase {
public DateTimeOffset Time => DateTimeOffset.Now;
}
我们将使用后一种方法,因为我更喜欢分离处理逻辑,以便于测试,而且“后台代码”也让我怀念起 ASP.NET WebForms。😉
我们的组件剃须刀看起来是这样的:
@page "/"
@if (!IndexLoaded) {
<p>Just building the search index, one moment</p>
} else {
<form @onsubmit="Search">
<input type="search" @bind="SearchTerm" /><button type="submit">Search</button>
</form>
}
@if (SearchResults.Count() > 0) {
<ul>
@foreach(var result in SearchResults) {
<li>
<p><a href="@result.Url" title="@result.Title" target="_blank">@result.Title (score: @result.Score.ToString("P2"))</a></p>
<p>@result.Description</p>
<p class="tags">Tags: @string.Join(" | ", result.Tags)</p>
</li>
}
</ul>
} else if (SearchResults.Count() == 0 && !string.IsNullOrEmpty(SearchTerm)) {
<p>Nothing matched that query</p>
}
让我们来分析一下一些有趣的事情,首先是<form>。
<form @onsubmit="Search">
<input type="search" @bind="SearchTerm" /><button type="submit">Search</button>
</form>
此表单将提交搜索,但我们不希望它发送到服务器,我们希望将其连接到 WASM 应用程序中的某个对象。为此,我们绑定了相应的 DOM 事件,即onsubmit,并赋予其组件上公共方法的名称。我们还需要访问输入的搜索词,为此,我们将使用双向数据绑定到字符串属性,通过@bind属性提供公共属性的名称。完成这些后,Blazor 将负责连接相应的 DOM 事件,以便在用户输入并提交到正确的“后端”时调用。
当搜索运行时,它将更新SearchResults集合,然后我们可以使用foreach循环:
@foreach(var result in SearchResults) {
<li>
<p><a href="@result.Url" title="@result.Title" target="_blank">@result.Title (score: @result.Score.ToString("P2"))</a></p>
<p>@result.Description</p>
<p class="tags">Tags: @string.Join(" | ", result.Tags)</p>
</li>
在这里,我们将属性的值注入到 DOM 元素的属性中,引用带有@前缀的 .NET 对象,就像使用 Razor 对 ASP.NET MVC 所做的那样。
现在我们的 UI 已经准备好了,我们可以继续创建我们的“后台代码”。
步骤 4 - 创建我们的组件
我们的组件将用 F# 编写并存在于Search.Site类库中,因此我们需要添加一些 NuGet 包:
dotnet add package Microsoft.AspNetCore.Blazor --version 3.1.0-preview3.19555.2
注意:我们在这里使用预览包,就像我们使用预览 .NET Core 版本一样,但请确保您使用最新的可用包,并且它们与 UI 项目中的包相匹配。
我还将包含优秀的TaskBuilder.fs包,以便我们可以使用 F# 计算表达式来处理 C# TaskAPI。
dotnet add package TaskBuilder.fs --version 2.1.0
我们需要一个复杂的类型来表示我们的搜索结果,所以我们将添加一个文件SearchResult.fs(我使用Ionide,因此它会自动将其添加到fsproj文件中),并在其中创建一个记录类型:
module SearchResult
type Post =
{ Title: string
Url: string
Tags: string []
Description: string
Score: float32 }
现在让我们创建一个名为的文件SearchComponent.fs,然后我们就可以开始搭建我们的组件了:
namespace Search.Site
open Microsoft.AspNetCore.Components
open SearchResult
type SearchComponent() =
inherit ComponentBase()
member val IndexLoaded = false with get, set
member val SearchTerm = "" with get, set
member val SearchResults = Array.empty<Post> with get, set
member this.Search() = ignore()
回到Index.razorBlazor 项目,我们可以添加@inherits Search.Site.SearchComponent以便我们的组件使用正确的基类。
现在是时候启动服务器了,让我们在监视模式下进行操作,以便我们能够继续开发:
dotnet watch run
服务器启动后,您可以导航http://localhost:5000并查看初始化消息!
步骤5 - 集成Lucene.NET
我们的 WASM 应用程序可能已经启动并运行,但它还没有任何功能,我们希望它连接到 Lucene.NET 以便我们进行搜索。不过,在此之前,我想先介绍一下 Lucene.NET 的一些基础知识。
Lucene.NET 101
Lucene.NET是 Java Lucene项目的一个移植版本,Lucene 是一个功能强大、性能卓越的全文搜索引擎。使用它,您可以创建搜索索引,将“文档”标记到其中,并使用各种查询样式进行搜索。.NET 移植版本与 API 兼容,这意味着 Lucene-Java 的文档也适用于 Lucene.NET。在开始之前,我们需要了解一些核心内容。
Lucene 的核心是Directory,它是存储搜索索引的位置,您可以使用 进行写入,IndexWriter并使用 进行查询IndexSearcher。Lucene 中存储的所有内容称为文档 (Document),它由许多不同的字段组成,每个字段都可以被标记化以便访问,并赋予不同的权重以辅助搜索。在搜索时,您可以查询整个文档,也可以针对特定字段进行查询。您甚至可以调整每个标记在查询中的权重以及标记匹配的“模糊”程度。以下是一个示例查询:
title:react tag:azure^5 -title:DDD Sydney
此查询将匹配react标题或 azure标签中包含 的文档,但不包括DDD Sydney标题中包含 的文档。然后,结果将被加权,以便任何带有 的标签azure都会在结果列表中排名更高。由此可见,它的强大功能。
如果您想了解有关 Lucene 的更多信息,我建议您查看 Lucene 文档和我过去的一些帖子,因为它比我在这里介绍的要强大得多。
创建我们的索引
我们需要在项目中添加一些包,以便开始使用 Lucene.NET。我们将使用 4.8 版本,因为它支持 .NET Standard 2.0,从而支持 .NET Core。在撰写本文时,它仍处于 Beta 阶段,我们正在使用该4.8.0-beta00006版本。我们首先将 Lucene.NET 的核心和分析器包添加到Search.Site:
dotnet add package Lucene.Net --version 4.8.0-beta00006
dotnet add package Lucene.Net.Analysis.Common --version 4.8.0-beta00006
要创建索引,我们需要创建一个供 Lucene.NET 使用的目录,现在通常你会使用它,FSDirectory但这需要一个文件系统,而我们是在 WebAssembly 沙盒中运行的,所以这会是个问题,对吧?事实证明并非如此,因为System.IOBlazor 使用的 API(通过 Mono 运行时)会映射到内存中的某个位置(我还没弄清楚具体是怎么回事,因为 Mono 源代码很难追踪)。
注意:你可能会注意到,我们即将遇到一个问题:所有内容都在内存中。这限制了我们的工作方式,毕竟我们仍然在浏览器中,但这确实意味着每次页面加载都会创建索引。在以后的文章中,我们将探讨如何对此进行优化。
我们想要为组件使用的入口点是,OnInitializedAsync因为它为我们提供了一个方便的点来创建目录并开始将 JSON 文件加载到索引中,但是我们如何获取 JSON 呢?当然是通过fetch,但由于这是 .NET,我们将使用HttpClient并将其作为组件的属性注入:
namespace Search.Site
open Microsoft.AspNetCore.Components
open SearchResult
open FSharp.Control.Tasks.V2
open Lucene.Net.Store
open Lucene.Net.Index
open System
open System.Net.Http
module Task =
let Ignore(resultTask: Task<_>): Task = upcast resultTask
type SearchComponent() =
inherit ComponentBase()
let mutable dir: FSDirectory = null
let mutable reader: IndexReader
let mutable http: HttpClient = null
member val IndexLoaded = false with get, set
member val SearchTerm = "" with get, set
member val SearchResults = Array.empty<Post> with get, set
member this.Search() = ignore()
[<Inject>]
member _.Http
with get () = http
and set value = http <- value
override this.OnInitializedAsync() =
task {
let! indexData = Http.GetJsonAsync<SearchData>("https://www.aaron-powell.com/index.json")
dir <- FSDirectory.Open(Environment.CurrentDirectory)
reader <- DirectoryReader.Open dir
} |> Task.Ignore
现在,好戏开始了,让我们来创建一个索引!我将 JSON 解包成 F# 中定义的一个类型,该类型映射到 JSON 对象的属性,并且它是一个数组,因此我们可以对其进行迭代。
注意:该System.Json包与 F# 记录类型兼容不佳,因此我使用了FSharp.SystemTextJson来改进互操作性。我还创建了一个自定义转换器,DateTimeOffset用于处理帖子存档中的一些无效日期。
override this.OnInitializedAsync() =
task {
let! indexData = Http.GetJsonAsync<SearchData>("https://www.aaron-powell.com/index.json")
dir <- FSDirectory.Open(Environment.CurrentDirectory)
reader <- DirectoryReader.Open dir
let docs = indexData.Posts
|> Array.map (fun post ->
let doc = Document()
let titleField = doc.AddTextField("title", post.title, Field.Store.YES)
titleField.Boost <- 5.f
doc.AddTextField("content", post.content, Field.Store.NO) |> ignore
doc.AddStringField("url", post.url, Field.Store.YES) |> ignore
let descField = doc.AddTextField("desc", post.description, Field.Store.YES)
descField.Boost <- 2.f
doc.AddStringField("date", DateTools.DateToString(post.date.UtcDateTime, DateTools.Resolution.MINUTE), Field.Store.YES) |> ignore
post.tags
|> Array.map (fun tag -> StringField("tag", tag, Field.Store.YES))
|> Array.iter doc.Add
doc :> IEnumerable<IIndexableField>))
let analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48)
let indexConfig = IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer)
use writer = new IndexWriter(dir, indexConfig)
writer.AddDocuments docs
} |> Task.Ignore
这可能看起来有点笨重,但本质上它是创建一个,添加一些字段并在创建分析器和编写器来写入索引之前Document返回它。IEnumerable<IIndexableField>
让我们仔细看看以下几行:
let titleField = doc.AddTextField("title", post.title, Field.Store.YES)
titleField.Boost <- 5.f
这里我们创建了一个字段来存储文章的标题。它被创建为TextField,这是 Lucene 中的一种字段类型,包含多个需要分词的词条。这与 不同,StringField后者要求将值视为单个分词(这也是我们将其用于标签的原因)。这意味着我们可以搜索标题“使用 Lucene.NET 在 Blazor WebAssembly 中实现搜索”中的每个单词,而不是将其视为整个字符串。
您还会注意到,与内容的Field.Store.YES相比,此字段是存储的,用 表示。这里的区别在于值的可检索性。存储的值可以通过查询检索,而非存储的值则不能。存储的值还会占用更多空间,访问速度也更慢,因此您需要谨慎选择以原始格式存储的内容。Field.Store.NO
最后,我们在此字段上设置了 Boost 值5,这意味着在此字段中找到的任何术语都比其他字段中相同术语的相关度高 5 倍。Boost 值意味着,如果您搜索“react”或“azure”,标题中包含其中任意一个的文档,其搜索结果排名将高于内容中仅包含这两个术语的文档。
让我们看看如何存储标签:
post.tags
|> Array.map (fun tag -> StringField("tag", tag, Field.Store.YES))
|> Array.iter doc.Add
这次我们使用了,StringField因为它只是一个单独的词,但我们没有提升排名,虽然看起来我们应该这样做,因为标签非常重要。由于我们使用的是StringField未经分析的,所以我们无法提升排名,而是在搜索时进行提升。
一旦所有帖子都转换为文档,就该将它们写入索引,这就是这 4 行代码的作用:
let analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48)
let indexConfig = IndexWriterConfig(LuceneVersion.LUCENE_48, analyzer)
use writer = new IndexWriter(dir, indexConfig)
writer.AddDocuments docs
将文档写入索引时,Lucene 会分析字段,以便知道如何构建索引。我们StandardAnalyzer在这里使用结合了一些常见场景的分析器,包括忽略“停用词”(this、the、and 等)、删除.and以及大小写规范化。我之前在一篇关于 Lucene 分析器的'文章中对此进行了更深入的介绍,但这个分析器适用于处理英语内容的常见场景。使用分析器,我们创建一个索引,并将文档写入索引,从而创建可供搜索的内容。IndexWriter
步骤 6 - 搜索
由于索引是在组件加载时创建的,我们最后需要做的就是处理搜索,也就是填写Search函数。我们还需要另一个 NuGet 包来构建查询:
dotnet add package Lucene.Net.QueryParser --version 4.8.0-beta00006
现在构建查询:
member this.Search() =
match this.SearchTerm with
| "" -> ignore()
| term ->
use analyzer = new StandardAnalyzer(LuceneVersion.LUCENE_48)
let qp =
MultiFieldQueryParser
(LuceneVersion.LUCENE_48, [| "title"; "content"; "tag"; "desc" |], analyzer,
dict
[ "title", 1.f
"tag", 5.f
"content", 1.f
"desc", 1.f ])
qp.DefaultOperator <- Operator.OR
let query = qp.Parse <| term.ToLowerInvariant()
let searcher = IndexSearcher reader
let sorter = Sort(SortField.FIELD_SCORE, SortField("date", SortFieldType.STRING))
let topDocs = searcher.Search(query, 20, sorter)
match topDocs.ScoreDocs.Length with
| 0 -> Array.empty
| _ ->
let maxScore =
topDocs.ScoreDocs
|> Array.map (fun hit -> (hit :?> FieldDoc).Fields.[0] :?> float32)
|> Array.max
let res = topDocs.ScoreDocs
|> Array.map (fun hit ->
let doc = searcher.Doc hit.Doc
let score = (hit :?> FieldDoc).Fields.[0] :?> float32
{ Score = score / maxScore
Title = doc.Get "title"
Url = doc.Get "url"
Description = doc.Get "desc"
Tags =
doc.Fields
|> Seq.filter (fun f -> f.Name = "tag")
|> Seq.map (fun f -> f.GetStringValue())
|> Seq.toArray })
this.SearchResults <- res
好吧,这……有点长……我们来分解一下。我们先用一个match表达式来确保有东西可以搜索,如果没有就忽略,否则我们需要构造一个查询。
let qp =
MultiFieldQueryParser
(LuceneVersion.LUCENE_48, [| "title"; "content"; "tag"; "desc" |], analyzer,
dict
[ "title", 1.f
"tag", 5.f
"content", 1.f
"desc", 1.f ])
qp.DefaultOperator <- Operator.OR
由于用户无法理解我们搜索索引的内部结构,我们希望方便他们搜索。为此,我们使用了查询解析器,特别是 ,它MultiFieldQueryParser有助于构建跨多个字段的查询。指定要使用的 Lucene 版本后,我们提供一个用于搜索的字段数组(标题、内容、标签和描述),然后为每个字段提供权重。记得之前我说过,我们可以对标签进行加权,因为它没有被标记化。我们就是这样加权的,通过提供一个字典( ),其中键是字段,值是权重。烦人的是,无论我们是否想要提升IDictionary<string, float>它,我们都需要提供每个字段,但这就是 API 的工作方式。
最后,我们将解析查询的默认运算符设置为 OR 运算符而不是 AND,从而允许我们在搜索中投放更广泛的网络。
解析器准备好后,我们就可以搜索索引:
let query = qp.Parse <| term.ToLowerInvariant()
let searcher = IndexSearcher reader
let sorter = Sort(SortField.FIELD_SCORE, SortField("date", SortFieldType.STRING))
let topDocs = searcher.Search(query, 20, sorter)
这里我们将使用一个自定义排序器,首先根据“得分”(匹配程度)排序,然后按日期排序(最新帖子的相关性更高)。不过,使用自定义排序器确实存在挑战。搜索完成后,您会收到每个文档的得分,该得分由相当复杂的算法生成(考虑了词条计数、提升等),数字越大,在结果中排名就越高。但是,当应用自定义排序器时,得分不再是唯一重要的值,这意味着如果您想显示文档的“匹配百分比”,就没那么简单了。那么,让我们看看如何构建结果及其得分。
let maxScore =
topDocs.ScoreDocs
|> Array.map (fun hit -> (hit :?> FieldDoc).Fields.[0] :?> float32)
|> Array.max
let res = topDocs.ScoreDocs
|> Array.map (fun hit ->
let doc = searcher.Doc hit.Doc
let score = (hit :?> FieldDoc).Fields.[0] :?> float32
{ Score = score / maxScore
Title = doc.Get "title"
Url = doc.Get "url"
Description = doc.Get "desc"
Tags =
doc.Fields
|> Seq.filter (fun f -> f.Name = "tag")
|> Seq.map (fun f -> f.GetStringValue())
|> Seq.toArray })
首先,我们遍历所有匹配的文档(好吧,我们限制的前 20 个),然后将它们转换为,FieldDoc然后提取第一个字段值,即我们的score(转换为float32)(我们知道这将是分数,因为它在排序器中的位置)并找到最大的一个。
接下来,我们可以遍历匹配的文档,这将返回一个包含文档 it 的对象,hit.Doc我们将要求搜索者使用该对象来检索文档。我们必须询问搜索者,因为文档 ID 包含在执行查询的上下文中。
通过文档,我们可以提取存储的字段,构建我们的搜索结果对象并将其返回到 UI。
搜索行动
我们现在完成了!
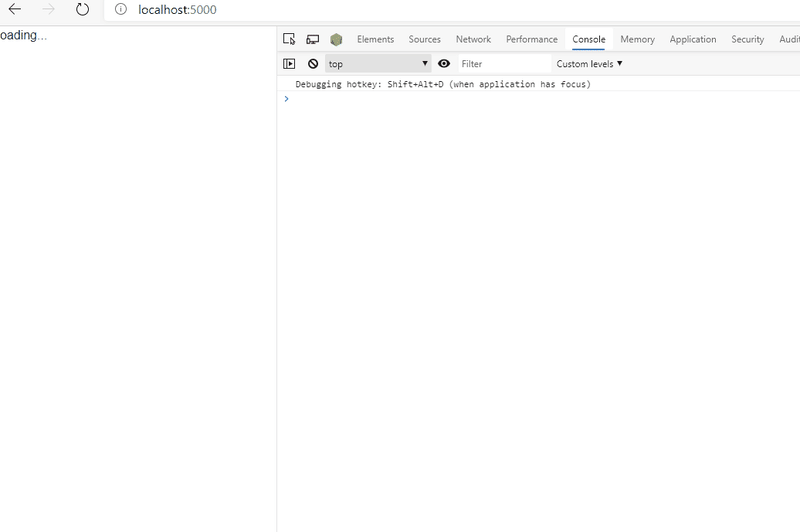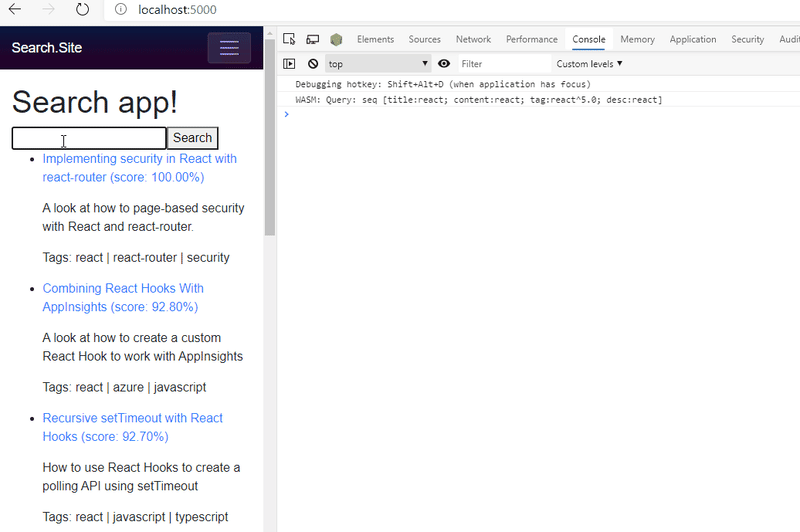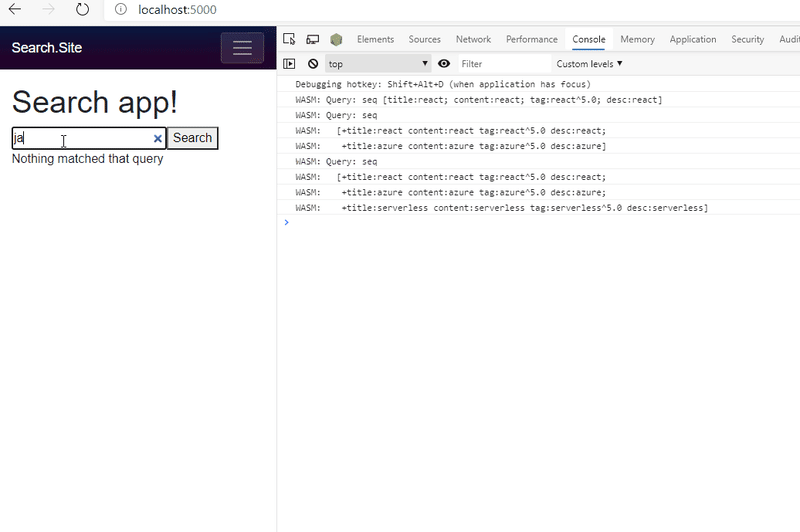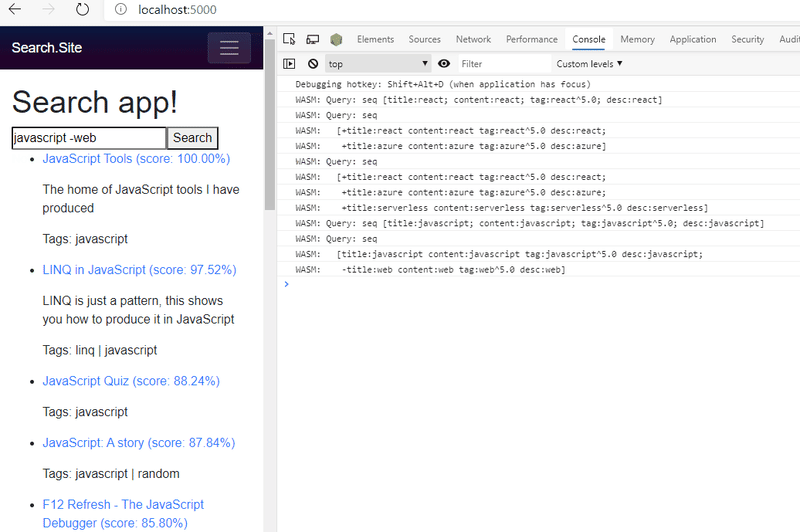
对于上面的演示,我保留了一条调试消息,其中我将解析的查询转储到控制台,以便您可以看到发送到 Lucene.NET 以产生结果的内容。
结论
我必须承认,当我开始尝试构建它时,我并没有指望它能成功。使用一个相当复杂的库并将其编译成 WebAssembly,结果却“正常工作”,这感觉就像一个相当疯狂的想法。
但是正如这篇文章(希望)所证明的那样,向 Blazor WebAssembly 项目添加搜索并不难,我花了更多时间试图记住如何使用 Lucene.NET,而不是构建应用程序!
你知道什么最酷吗?我的网站现在有搜索功能了!
我构建它的方式与我上面描述的略有不同,但我会将一些高级概念留到下一篇文章中。
文章来源:https://dev.to/dotnet/implementing-search-in-blazor-web assembly-with-lucene-net-4mpi