请负责任地使用 Redis
Redis 的核心在于速度。但 Redis 速度快并不意味着它在你向其发出请求时不会占用时间和资源。如果这些请求的发送方式不当,就会累积起来,影响应用程序的性能。以下是 Kenna 是如何从痛苦的经历中吸取这一教训的。
隐藏在众目睽睽之下
Kenna数据库中最大的表格之一是漏洞。我们目前拥有近 40 亿个漏洞。漏洞是指攻击者可以利用的弱点,从而未经授权访问计算机系统。简而言之,漏洞是公司遭受黑客攻击的途径。
我们首先将所有这些漏洞存储在 MySQL 中,这是我们的数据来源。之后,我们将漏洞数据索引到Elasticsearch中。
当我们将所有这些漏洞索引到 Elasticsearch 中时,我们必须向 Redis 发出请求才能知道将它们存放在哪里。在 Elasticsearch 中,漏洞是按客户端组织的。为了确定漏洞的归属,我们必须向 Redis 发出 GET 请求来获取该漏洞的索引名称。
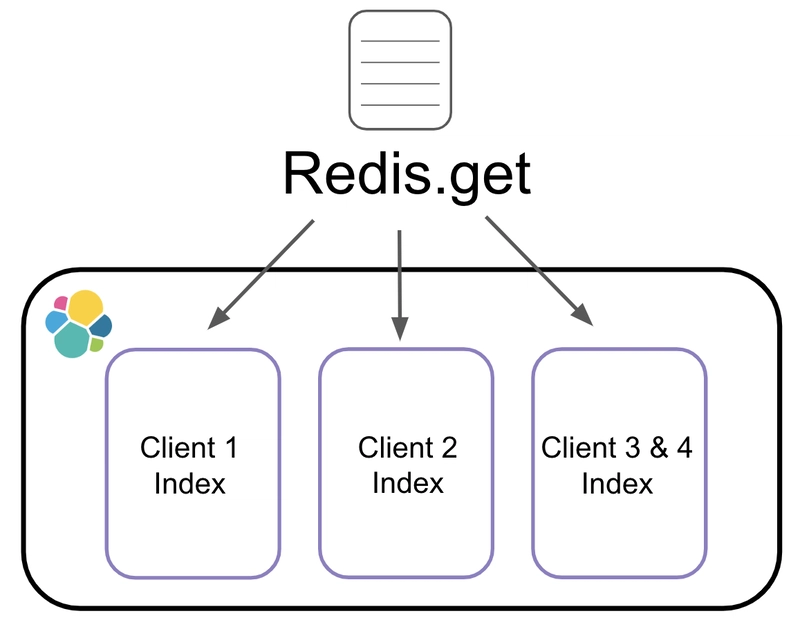
在准备漏洞索引时,我们会收集所有漏洞哈希值。然后,在将它们发送到 Elasticsearch 之前,我们要做的最后一件事是发出 Redis GET 请求,根据每个漏洞的客户端检索其索引名称。
indexing_hashes = vulnerability_hashes.map do |hash|
{
:_index => Redis.get("elasticsearch_index_#{hash[:client_id]}")
:_type => hash[:doc_type],
:_id => hash[:id],
:data => hash[:data]
}
end
这些漏洞哈希值按客户端分组,因此 GET 请求
Redis.get("elasticsearch_index_#{hash[:client_id]}")
经常会一遍又一遍地返回相同的信息。所有这些简单的 GET 请求都快得惊人,大约需要一毫秒就能完成。
(pry)> index_name = Redis.get("elasticsearch_index_#{client_id}")
DEBUG -- : [Redis] command=GET args="elasticsearch_index_1234"
DEBUG -- : [Redis] call_time=1.07 ms
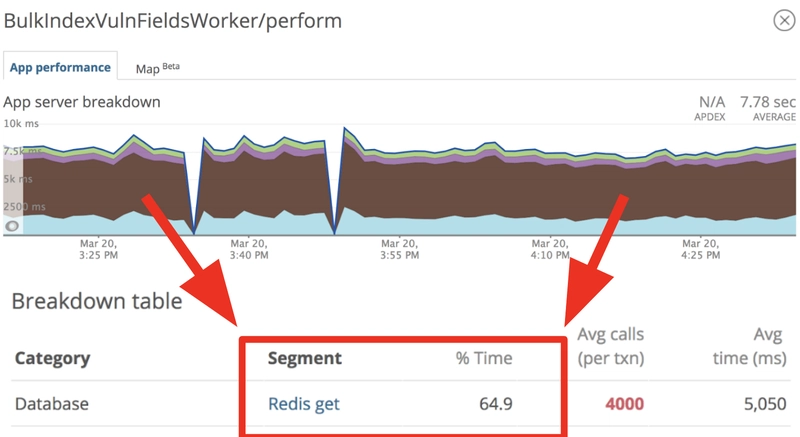
但是,无论您的外部请求有多快,如果您发出大量请求,都会花费很长时间。由于我们发出了大量简单的 GET 请求,它们占据了我们索引作业大约65%的运行时间。您可以在下表中看到这个统计数据,它在图表中用棕色表示。
消除大量此类请求的解决方案是使用本地 Ruby 缓存!我们最终使用 Ruby 哈希来缓存每个客户端的 Elasticsearch 索引名称。
client_indexes = Hash.new do |h, client_id|
h[client_id] = Redis.get("elasticsearch_index_#{client_id}")
end
然后,当循环遍历所有漏洞哈希并将其发送到 Elasticsearch 时,我们只需引用此客户端索引哈希,而不是针对每个漏洞访问 Redis。
indexing_hashes = vuln_hashes.map do |hash|
{
:_index => client_indexes[hash[:client_id]]
:_type => hash[:doc_type],
:_id => hash[:id],
:data => hash[:data]
}
end
这意味着我们只需要对每个客户端攻击一次 Redis,而不是对每个漏洞攻击一次。
回报
假设我们有 3 批漏洞需要编入索引。
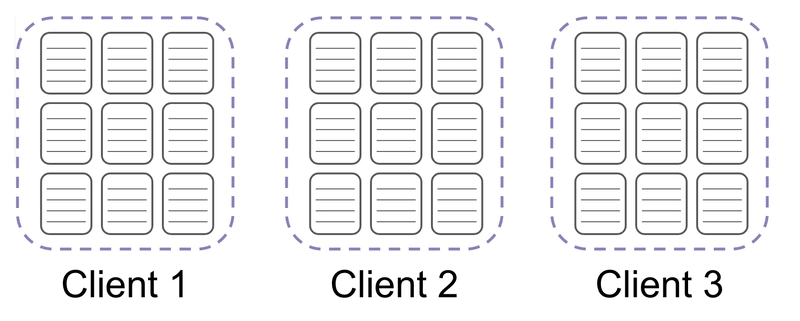
对于这三个批次,无论每个批次中有多少个漏洞,我们只需要向 Redis 发出总共 3 个请求。这些批次通常每个包含 1000 个漏洞,因此这项更改将我们对 Redis 的访问次数减少了 1000 倍,从而使作业速度提高了 65%。
虽然 Redis 很快,但使用本地缓存总是更快!简单来说,从本地缓存获取信息就像从芝加哥市中心开车去奥黑尔机场取一样。

要从 Redis 获取相同的信息,就像从芝加哥乘飞机一路飞到波士顿一样。
Redis 速度非常快,以至于当你与它交互时,很容易忘记你实际上是在向外部发出请求。这些外部请求会累积起来,影响应用程序的性能。不要将 Redis 视为理所当然。确保你向它发出的每个请求都是绝对必要的。
如果您对使用 Ruby 防止数据库命中的其他方法感兴趣,请查看我在RubyConf 上发表的“Cache Is King”演讲,该演讲启发了本文的灵感。
鏂囩珷鏉ユ簮锛�https://dev.to/molly/please-redis-responsively--3gn