Elasticsearch 扩展(二):如何加速搜索
对数据进行分组
过滤器是朋友
将 ID 存储为关键字
不要让你的用户拖慢你的速度
回顾:加速大规模搜索
提前规划
在本博客的第 1 部分中,我列出了我的公司 Kenna Security 在扩展集群的同时用来加速索引的所有技术。
文章已不再可用
在第 2 部分中,我想分享一些我们用来加快搜索速度同时将文档数量增加到超过 40 亿个文档的技术。
对数据进行分组
首先,我想谈谈数据组织。很多人使用 Elasticsearch 来存储日志。大多数日志集群的设置都基于日期。日志集群如此设置的一个最大原因是,这在搜索时可以方便地筛选数据。如果要搜索两天的数据,Elasticsearch 只需查询两个索引。

这意味着需要搜索的分片更少,从而提高搜索速度。这种通过分组数据来加快搜索速度的理念也适用于非日志集群。
Kenna 刚开始使用 Elasticsearch 时,我们所有的数据都存储在一个小型索引中。随着数据量的增加,我们不得不增加该索引的分片数量。随着分片数量的增加,我们的搜索速度变慢了。为了加快速度,我们决定按客户拆分数据。现在每个客户都有自己的索引。

这对我们来说非常有意义,因为当我们查找数据时,99% 的时间都是按客户端进行的。现在,当我们针对某个客户端运行搜索时,我们只需查看一小部分分片,而不是全部。这使我们能够在向集群添加越来越多的数据的同时保持快速的搜索速度。
过滤器是朋友
除了数据组织之外,您还可以通过优化结构来加快搜索速度。Elasticsearch 有两种搜索模式:查询和过滤器。

查询需要对文档进行评分,这给 Elasticsearch 带来了更多工作量。而过滤器不需要对文档进行评分,因此工作量更小,速度也更快。在 Kenna,我们只使用过滤器,因为我们知道它们的好处。然而,直到 2016 年 3 月,我们才真正体会到这些好处。
2016 年 3 月,我们升级到了 Elasticsearch 5。升级过程中,我们遇到了Elasticsearch 的一个 bug,导致部分过滤器被评分。这给我们的集群带来了多少额外的工作量?嗯,我们的堆图开始看起来像这样……

作为参考,堆图应该是这样的......
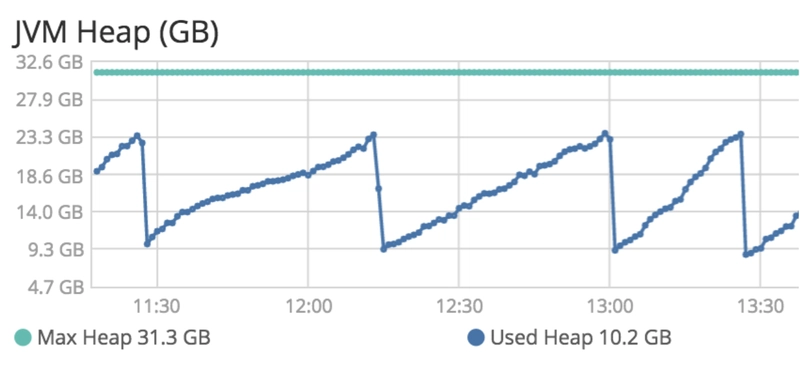
我们的系统远非健康。对几个频繁使用的过滤器进行评分,导致大量额外工作,以至于我们的生产集群整整一周都无法使用,直到漏洞被修复。说实话,那真是漫长的一周 😬 这次经历让我们明白了过滤器的重要性,我们应该尽可能地使用它们。

如果您的搜索结果中有任何部分不需要评分,请将其移至筛选器块。如果您确实需要对搜索结果的某些部分进行评分,请考虑使用查询bool。这样您就可以组合评分块(例如 )must和非评分块(例如filter)。

随着数据整理完毕,以及我们对过滤器的全新认识,到 2017 年底,我们的 Elasticsearch 集群已经达到了相当不错的状态。这时,我们终于开始着手进行一些最初积压的优化。其中一项优化就是将 ID 存储为关键字。
将 ID 存储为关键字
这是我在Elasticsearch 培训中反复听到的建议。(如果您从未参加过 Elasticsearch 培训,我强烈推荐!我已经参加了三次培训,每次我都带着可行的项目离开,我们能够用它们来改进我们的集群。)基本上,每当您存储永远不会用于范围搜索的 ID 时,您都希望将它们存储为关键字。这样做的原因是关键字针对术语搜索进行了优化。整数或数字映射类型针对范围搜索进行了优化。在了解到这一点后,我认为这不会对我们 Kenna 产生太大影响,所以我提交了工单,然后就忘了这件事。
我们花了一年多的时间才终于从积压的订单中抽出时间,并真正付诸实践。结果超出了我们的预期。当我们最终将整数转换为关键词后,我们发现搜索速度全面提升了 30%。

我们立即希望我们能早点做出改变,但迟做总比不做好!
我想分享的最后一个优化,也是我在 Elasticsearch 培训中听到的。然而,它也被搁置了,因为我们觉得它不那么重要。我们又一次错了,不得不以惨痛的教训来吸取这个教训。
不要让你的用户拖慢你的速度
有一天,我们正在监控 Elasticsearch,突然发现所有节点的 CPU 和负载都达到了最大值。

我的团队开始忙乱地寻找造成负载的原因。我们开始仔细检查慢日志,试图找出正在运行的查询,然后偶然发现了这个宝藏。

一堆 OR 语句加上一堆前导通配符,简直就是一个地狱般的查询字符串。这引出了我的最后一条建议,或许也是最重要的一条:别让你的用户拖慢你的速度!
在网站上随便放一个搜索框,然后把里面的内容发送到 Elasticsearch,这太容易了。千万别这么做!限制用户可以搜索和不能搜索的内容。我们在 Kenna 解决了这个问题,方法是为用户定义他们可以用来搜索的关键词。我们还花时间编写了更多文档,让用户了解哪些字段可以搜索。

经过这些改进,用户的搜索现在更加精准、更有针对性,而且 Elasticsearch 的处理速度也更快。最终,实现共赢!
回顾:加速大规模搜索
- 对数据进行分组
- 尽可能使用过滤器
- 将 ID 存储为关键字
- 不要让用户拖慢你的速度
提前规划
当我们开始使用 Elasticsearch 来处理所有客户的搜索需求时,我们似乎不会犯任何错误。然而,随着数据规模的不断增长,我们很快意识到必须更加智能地使用 Elasticsearch。在集群规模较小时,尝试应用这些搜索技术,这将使扩展变得容易得多。得益于所有这些索引和搜索优化,Kenna 的 Elasticsearch 集群现在是其基础设施中最稳定的部分之一,我们计划长期保持这种状态。
敲木頭
本博客最初发表于elastic.co
鏂囩珷鏉ユ簮锛�https://dev.to/molly/scaling-elasticsearch-part-2-how-to-speed-up-search-53of