从零到本地LLM:Docker模型运行器开发者指南
为什么本地法学硕士项目如此重要
大型语言模型彻底改变了我们构建应用程序的方式,但它们大多运行在云端。这意味着您经常会遇到响应缓慢、API 调用成本高昂以及隐私泄露或需要网络连接等问题。在本地计算机上运行模型可以避免所有这些问题,让您轻松获得速度更快、更私密、且支持离线使用的 AI 服务。
Docker Model Runner 的改变在于,它将容器原生开发的强大功能引入到本地 AI 工作流程中,让您可以专注于构建,而不是与工具链作斗争。
开发者的痛点:
- 隐私问题——当数据必须发送到云端 API 时,很难进行安全测试。
- 成本高昂——通过付费 API 运行提示会迅速累积成本,尤其是在早期开发和测试阶段。
- 设置复杂- 让本地模型运行起来通常意味着要处理复杂的安装和硬件依赖关系。
- 硬件限制——许多笔记本电脑的设计初衷并非为了运行大型模型,尤其是没有独立显卡的笔记本电脑。
- 不同型号的测试很困难——在不同型号或版本之间切换通常意味着重新配置整个设置。
Docker 模型运行器通过以下方式解决这些问题:
- 使用简单的 CLI 实现模型访问标准化,该 CLI 可从 Docker Hub 拉取模型
- 底层使用 llama.cpp 快速运行
- 提供开箱即用的 OpenAI 兼容 API
- 直接与 Docker Desktop 集成
- 在可用时使用 GPU 加速,支持 Windows 上的 Apple Silicon(Metal)和 NVIDIA GPU,以加快推理速度。
🐳什么是 Docker 模型运行器?
这是一个轻量级的本地模型运行时环境,与 Docker Desktop 集成。它允许您通过熟悉的命令行界面 (CLI) 和兼容 OpenAI 的 API 在本地运行量化模型(GGUF 格式)。它由以下技术驱动llama.cpp并旨在:
- 对开发者友好:几秒钟内即可拉取并运行模型
- 离线优先:非常适合隐私和边缘使用场景
- 可组合:可与 LangChain、LlamaIndex 等配合使用。
主要特点:
- OpenAI 风格的 API 服务地址为:
http://localhost:12434/engines/llama.cpp/v1/chat/completions
- 无需GPU:即使在搭载Apple Silicon芯片和Windows 11 + NVIDIA GPU的MacBook上也能运行
- 通过 UX 和 CLI 轻松切换模型
- 与 Docker Desktop 集成
五分钟快速入门
1. 启用模型运行器(Docker Desktop)
docker desktop enable model-runner --port 12434
2. 拉出你的第一个模型
docker model pull ai/smollm2:360M-Q4_K_M
3. 运行带提示的模型
docker model run ai/smollm2:360M-Q4_K_M "Explain the Doppler effect like I’m five."
4. 使用 API(兼容 OpenAI)
curl http://localhost:12434/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "smollm2", "prompt": "Hello, who are you?", "max_tokens": 100}'
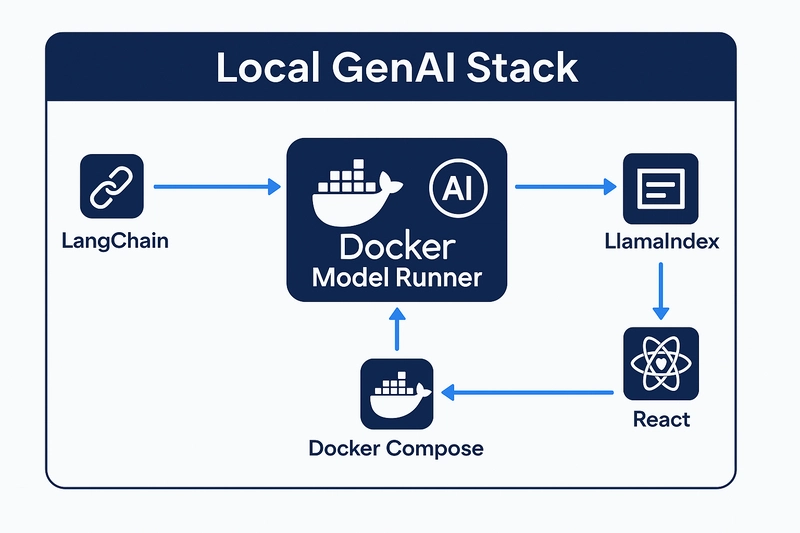
⚙️ 构建您的本地 GenAI 技术栈
以下是一个使用 Docker Model Runner 作为推理后端的简单架构:
- LangChain:用于提示模板和链式调用
- Docker Model Runner:在本地运行实际的 LLM
- LlamaIndex:用于文档索引和检索(RAG)
- React Frontend:简洁的聊天 UI,用于与模型交互
- Docker Compose:一个命令即可运行所有组件
Compose 示例示例
以下示例 docker-compose.yml展示了 Docker 模型运行器如何集成到本地 GenAI 堆栈中:
services:
chat:
build: ./chat # Replace with your frontend app path or Git repo
depends_on:
- ai_runner
environment:
- MODEL_URL=${AI_RUNNER_URL}
- MODEL_NAME=${AI_RUNNER_MODEL}
ports:
- "5000:5000"
ai_runner: # Even if a service of type `model` is specified,
# It doesn't run as a container — it runs directly on
the host system via Docker Model Runner.
provider:
type: model
options:
model: ai/smollm2 # Specifies the local LLM to be used
特征:
- 离线使用本地模型缓存
- 动态加载/卸载模型以节省资源
- 兼容 OpenAI 的 API,可实现无缝集成
- 兼容系统上的 GPU 加速支持
💡额外福利:添加前端聊天界面
使用任何前端框架(React/Next.js/Vue)构建一个聊天界面,该界面通过 REST API 与本地模型进行通信。
简单示例获取:
#!/bin/sh
curl http://localhost:12434/engines/llama.cpp/v1/chat/completions \
-H "Content-Type: application/json" \
-d ' {
"model": "ai/smollm2",
"messages": [
{
"role": "system",
"content": "You are a helpful assistant."
},
{
"role": "user",
"content": "Please write 500 words about the fall of Rome."
}
]
}'
这样一来,无论您使用的是搭载 Apple Silicon 芯片的 MacBook 还是配备 NVIDIA GPU 的 Windows PC,都能在您的计算机上直接运行完全本地化的 LLM 模型。无需云 API,无需网络连接。模型即可在本地原生运行。
🚀高级用例
- RAG 流水线:结合 PDF、本地向量搜索和模型运行器
- 多模型支持:在独立服务中运行 phi2、mistral 等模型
- 模型对比:使用 Compose 构建 A/B 测试界面
- Whisper.cpp 集成:语音转文本容器插件(即将推出)
- 边缘 AI 设置:部署在隔离系统或开发板上
愿景:未来的发展方向
Docker 模型运行器路线图(Beta 阶段):
- 有可能建立一个可搜索、可标记的 ModelHub 或 Docker Hub 注册表
- 计划支持 Compose 原生 GenAI 模板
- 探索 Whisper + LLM 混合跑鞋
- 开发用于监控模型性能的仪表盘
- IDE 集成,例如用于快速工程和测试的 VSCode 扩展,仍在讨论中,尚未推出。
注意:Docker 模型运行器目前处于 Beta 测试阶段。部分功能和集成尚处于早期阶段或规划阶段,可能会随时间推移而有所变化。
作为一名开发者,我认为这是一个巨大的机会,可以降低人工智能实验的门槛,并帮助每个人都能接触到容器原生人工智能。
文章来源:https://dev.to/docker/from-zero-to-local-llm-a-developers-guide-to-docker-model-runner-4oi2