Kimi K2 对阵 Qwen-3 Coder:12 小时的测试!
在花费 12 小时对 Kimi K2 和 Qwen-3 Coder 进行相同的 Rust 开发任务和前端重构任务测试后,我发现了一些基准测试分数无法揭示的信息:在这个测试环境下,一个模型能够持续生成可运行的代码,而另一个模型甚至难以执行基本的指令。这些发现挑战了人们对 Qwen-3 Coder 基准测试性能的吹捧,并表明为什么在实际代码库上进行测试比综合评分更为重要。
🚀试试 AI Shell
您的智能编码助手,可无缝集成到您的工作流程中。
登录 Forge →
测试方法:真实开发场景
我围绕实际开发场景设计了这项对比,这些场景反映了日常的 Rust 开发工作。没有合成基准测试或玩具问题,只有 13 个具有挑战性的 Rust 任务,这些任务涉及一个成熟的 38,000 行 Rust 代码库,其中包含复杂的异步模式、错误处理和架构约束;此外,还有 2 个前端重构任务,涉及一个 12,000 行 React 代码库。
测试环境规范
项目背景:
- Rust 1.86 和 tokio 异步运行时
- 跨多个模块的 38,000 行代码
- 控制反转(IoC)之后的复杂依赖注入模式
- 广泛使用特性、泛型和 async/await 模式
- 包含集成测试的综合测试套件
- 使用现代 Hooks 和组件模式的 12,000 行 React 前端代码
- 完善的编码指南(以自定义规则/游标规则/Claude 规则的形式提供,适用于不同的编码代理)
测试类别:
- 指定文件更改(4 个任务):对指定文件进行特定修改
- 缺陷查找与修复(5项任务):包含重现步骤和失败测试的真实缺陷
- 功能实现(4 项任务):根据明确的需求开发新功能
- 前端重构(2 个任务):使用Forge Agent和 Playwright MCP改进 UI
评价标准:
- 代码正确性和编译成功
- 指令遵守情况和范围符合性
- 完成时间
- 所需迭代次数
- 最终实施质量
- 代币使用效率
绩效分析:综合结果
任务完成情况总结
| 类别 | Kimi K2 成功率 | Qwen-3 程序员成功率 | 时差 |
|---|---|---|---|
| 指向的文件更改 | 4/4 (100%) | 3/4 (75%) | 速度提升 2.1 倍 |
| 漏洞检测与修复 | 4/5 (80%) | 1/5 (20%) | 速度提升 3.2 倍 |
| 功能实现 | 4/4 (100%) | 2/4 (50%) | 速度提升 2.8 倍 |
| 前端重构 | 2/2 (100%) | 1/2 (50%) | 速度提升 1.9 倍 |
| 全面的 | 14/15 (93%) | 7/15 (47%) | 速度提升 2.5 倍 |
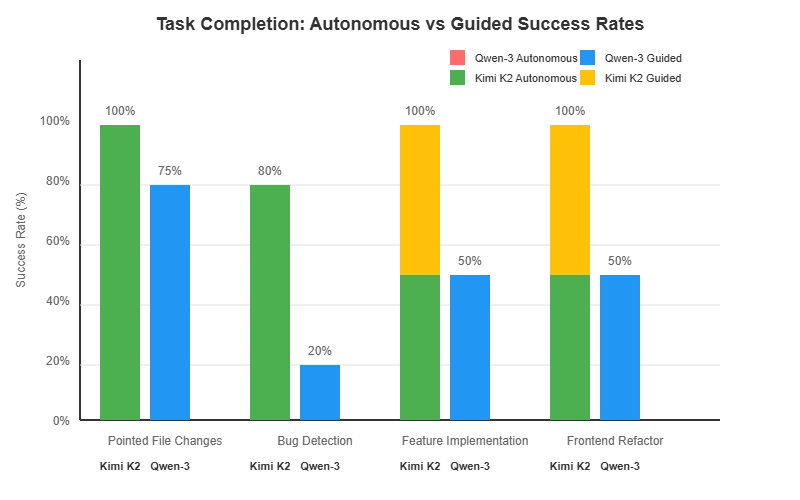 图 1:任务完成情况分析——自主完成率与指导完成率(仅显示成功完成的情况)
图 1:任务完成情况分析——自主完成率与指导完成率(仅显示成功完成的情况)
工具调用和补丁生成分析
| 指标 | Kimi K2 | Qwen-3 程序员 | 分析 |
|---|---|---|---|
| 总补丁调用次数 | 811 | 701 | 相似体积 |
| 工具调用错误 | 185 (23%) | 135 (19%) | Qwen-3 略好 |
| 补丁成功 | 626 (77%) | 566 (81%) | 可靠性相当 |
| 清洁编译率 | 89% | 72% | Kimi K2 优势 |
两种模型在处理工具模式方面都存在困难,尤其是在补丁操作方面。然而,人工智能代理会重试失败的工具调用,因此最终的补丁生成成功率并未受到初始错误的影响。关键区别体现在代码质量和编译成功率上。
错误检测和分辨率比较
Kimi K2 性能:
- 5个bug中有4个在第一次尝试中就正确修复了
- 平均解决时间:8.5分钟
- 在修复底层问题的同时,保持了原有的测试逻辑。
- 只在 tokio::RwLock 死锁场景中遇到了问题
- 维护业务逻辑完整性
Qwen-3 程序员表现:
- 1/5 的错误已正确修复
- 频繁修改测试断言而不是修复错误
- 引入硬编码值以使测试通过
- 改变业务逻辑,而不是解决根本原因
- 平均解决时间:22 分钟(成功时)
功能实现:自主开发能力
任务完成情况分析
Kimi K2 比赛结果:
- 4项任务中有2项自主完成(分别耗时12分钟和15分钟)。
- 2/4 的任务只需要少量指导(1-2 个提示)
- 在现有功能增强方面表现出色
- 对于没有示例的全新功能,需要更多指导。
- 始终保持代码风格和架构模式的一致性
Qwen-3 编码器结果:
- 0/4 项任务自主完成
- 每个任务至少需要 3-4 次重新提示。
- 经常删除工作代码以便“重新开始”
- 经过40分钟的催促,4项任务中只有2项完成。
- 由于迭代次数过多,2 个任务被放弃。
指令遵循分析
最大的差异体现在指令遵循情况上。尽管系统提示中提供了编码指南,但不同模型的表现却截然不同:
| 指令类型 | Kimi K2 合规性 | Qwen-3 编码员合规性 |
|---|---|---|
| 错误处理模式 | 7/8 项任务 (87%) | 3/8 项任务 (37%) |
| API兼容性 | 8/8 项任务 (100%) | 4/8 项任务 (50%) |
| 代码风格指南 | 7/8 项任务 (87%) | 2/8 项任务 (25%) |
| 文件修改范围 | 8/8 项任务 (100%) | 5/8 项任务 (62%) |
Kimi K2 行为:
- 始终遵循项目编码标准
- 尊重文件修改边界
- 保留了现有的函数签名
- 当需求不明确时,提出澄清问题。
- 提交前已编译并测试代码
Qwen-3 编码器模式:
// Guidelines specified: "Use Result<T, E> for error handling"
// Qwen-3 Output:
panic!("This should never happen"); // or .unwrap() in multiple places
// Guidelines specified: "Maintain existing API compatibility"
// Qwen-3 Output: Changed function signatures breaking 15 call sites
这种模式在各个任务中反复出现,表明指令处理存在问题,而不是孤立事件。
前端开发:无需图像的视觉推理
使用 Forge 代理和 Playwright MCP 和 Context7 MCP 对前端重构任务中的这两个模型进行测试,揭示了它们在视觉推理能力方面的见解,尽管缺乏直接的图像支持。
Kimi K2进近方式:
- 对现有组件结构进行了智能分析
- 对用户界面布局做出了合理的假设
- 提供了以可维护性为重点的建议
- 保留的无障碍模式
- 在极少指导下完成了重构。
- 保持响应速度和设计系统的一致性
- 有效重用现有组件
- 在不破坏功能的前提下,逐步改进了各项功能。
Qwen-3 程序员方法:
- 删除了现有组件而不是重构
- 忽略了既定的设计系统模式
- 需要多次迭代才能理解组件关系
- 不加考虑地破坏了响应式布局
- 已删除的分析和跟踪代码
- 使用硬编码值而不是变量绑定
🚀试试 AI Shell
您的智能编码助手,可无缝集成到您的工作流程中。
登录 Forge →
成本和背景分析
开发效率指标
| 指标 | Kimi K2 | Qwen-3 程序员 | 不同之处 |
|---|---|---|---|
| 完成每项任务的平均时间 | 13.3分钟 | 18分钟 | 速度提升 26% |
| 项目总成本 | 42.50美元 | 69.50美元 | 便宜 39%。 |
| 已完成的任务 | 14/15 (93%) | 7/15 (47%) | 完成率翻倍 |
| 已放弃的任务 | 1/15 (7%) | 2/15 (13%) | 更好的坚持 |
由于我们使用了 OpenRouter(它将负载分配到多个提供商),不同供应商的费率各不相同,因此精确计算成本颇具挑战性。Kimi K2 的总成本为 42.50 美元,平均每项任务耗时 13.3 分钟(包括必要的提示时间)。

Kimi K2 在 OpenRouter 提供商中的使用成本——上下文长度始终为 131K,输入价格从 0.55 美元到 0.60 美元不等,输出价格从 2.20 美元到 2.50 美元不等。
然而,Qwen-3 Coder 的成本几乎是 Kimi K2 的两倍。每项任务的平均耗时约为 18 分钟(包括必要的提示),15 项任务的总成本为 69.50 美元,其中 2 项任务被放弃。

Qwen-3 Coder 在 OpenRouter 提供商之间的使用成本——定价结构相同,但总使用量更高,导致成本增加。
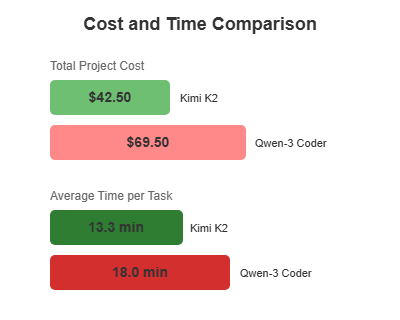 图 3:成本和时间比较——直接项目投资分析
图 3:成本和时间比较——直接项目投资分析
效率指标
| 指标 | Kimi K2 | Qwen-3 程序员 | 优势 |
|---|---|---|---|
| 完成任务的成本 | 3.04美元 | 9.93美元 | 便宜 3.3 倍 |
| 时间效率 | 速度提升 26% | 基线 | Kimi K2 |
| 成功率 | 93% | 47% | 效果提升2倍 |
| 已完成的任务 | 14/15 (93%) | 7/15 (47%) | 完成率翻倍 |
| 已放弃的任务 | 1/15 (7%) | 2/15 (13%) | 更好的坚持 |
上下文长度和性能
Kimi K2:
- 上下文长度:131k 个令牌(各提供商一致)
- 推理速度:很快,尤其是在使用 Groq 时。
- 内存使用:高效的上下文利用
Qwen-3 程序员:
- 上下文长度:26.2万至100万个令牌(因提供商而异)
- 推理速度:不错,但比 Kimi K2 慢。
- 内存使用情况:更高的上下文开销
僵局挑战:技术深度解析
最具启发性的测试涉及 tokio::RwLock 死锁场景,该场景突显了问题解决方法的差异:
Kimi K2 的 18 分钟分析:
- 系统地分析了锁定获取模式
- 已识别的潜在死锁场景
- 尝试了多种解决方法
- 最终承认了问题的复杂性并请求指导
- 在整个过程中保持代码完整性
Qwen-3 程序员的方法:
- 立即建议移除所有锁(破坏螺纹安全)。
- 提出的不安全代码作为解决方案
- 改变测试预期,而不是修复死锁
- 从未展现出对底层并发问题的理解。
基准与现实:绩效差距
Qwen-3 Coder 令人印象深刻的基准测试分数并不能转化为实际开发效率。这种脱节暴露了我们在评估 AI 编码助手方面存在的重大局限性。
为什么基准测试会出错
基准测试的局限性:
- 具有清晰、独立解的综合性问题
- 无需遵守指令或约束条件
- 成功仅以最终成果衡量,而非开发过程。
- 缺乏对可维护性和代码质量的评估
- 未对协作开发模式进行评估
实际需求:
- 在现有代码库和架构约束条件下进行开发
- 遵循团队编码标准和风格指南
- 保持向后兼容性
- 迭代开发,需求不断变化
- 代码审查和可维护性考量
🚀试试 AI Shell
您的智能编码助手,可无缝集成到您的工作流程中。
登录 Forge →
局限性和背景
在深入探讨结果之前,有必要先了解一下本次比较的范围:
测试局限性:
- 单代码库测试(38000 行 Rust 项目 + 12000 行 React 前端)
- 结果可能不适用于其他代码库、语言或开发风格
- 由于样本量过小,未进行统计显著性检验。
- 可能存在对特定编码模式和偏好的偏见
- 通过 OpenRouter 测试了不同运营商提供的模型
此比较未涵盖的内容:
- 除了 Rust 和 React 之外,在其他编程语言上的性能表现
- 不同提示工程方法下的行为
- 具有不同架构模式的企业代码库
这些结果反映的是一种特定的测试环境,在做出模型选择决定之前,应结合其他评估结果进行考虑。
结论
这项测试表明,Qwen-3 Coder 的基准测试得分并不能很好地应用于这种特定的开发工作流程。虽然它在处理孤立的编码挑战时表现出色,但在应对本项目中使用的协作式、约束感知型开发模式时却显得力不从心。
在这种测试环境下,Kimi K2 能够持续交付可运行的代码,且几乎无需监督,展现出更好的指令遵循度和代码质量。其方法与既定的开发流程和编码标准更加契合。

Qwen-3 Coder 的上下文长度优势(最高可达 100 万个 token,而 Kimi K2 为 13.1 万个 token)并未弥补其在指令跟踪方面的不足。两种模型的推理速度都不错,但 Kimi K2 搭配 Groq 的响应速度明显更快。
虽然这些开源模型正在快速改进,但在本次测试中,它们仍然落后于 Claude Sonnet 4 和 Opus 4 等闭源模型。然而,根据这项评估,Kimi K2 在这些特定的 Rust 开发需求方面表现更佳。
相关文章
- Claude Sonnet 4 与 Gemini 2.5 Pro 对比预览:AI 编码助手对比
- AI代理最佳实践:利用Forge最大限度地提高生产力
- Deepseek R1-0528 编码经验:增强人工智能辅助开发