谷歌打个喷嚏,全世界都感冒了!
由 Mux 主办的 DEV 全球展示挑战赛:展示你的项目!
太长不看
6月12日上午10:50(太平洋时间) ,谷歌云的全球身份与访问管理 (IAM) 服务出现故障,导致数十款GCP 产品出现身份验证失败。Cloudflare 的 Workers KV 服务依赖于谷歌托管的后端存储,随后也受到影响,导致 Access、WARP 和其他零信任功能失效。运行在 GCP 上的 Anthropic 服务也出现了文件上传丢失和错误率升高的情况。七个半小时后,所有缓解措施全部完成,所有服务恢复正常。让我们来分析一下这一系列连锁反应。

1. 时间线概览
| 时间(太平洋时间) | 信号 | 我们看到了什么 |
|---|---|---|
| 10:51 | 内部警报 | GCP SRE 收到来自 IAM 端点的 5xx 错误激增 |
| 11:05 | DownDetector | Gmail、云端硬盘、Meet 的用户举报数量激增 |
| 11:19 | Cloudflare状态 | “调查大范围访问故障” |
| 11:25 | 人类地位 | 为减少错误量,已禁用图像和文件上传功能。 |
| 12:12 | Cloudflare 更新 | 根本原因已确定为第三方 KV 依赖项。 |
| 12:41 | 谷歌更新 | 已向 IAM 舰队部署缓解措施,大部分区域运行状况良好。 |
| 13:30 | Cloudflare 绿色 | Access、KV 和 WARP 已在全球范围内恢复在线 |
| 14:05 | 人为的绿色 | 完全康复,克劳德情况稳定 |
| 15:16 | 谷歌更新 | 截至太平洋夏令时13:45,大部分GCP产品已完全回收。 |
| 16:13 | 谷歌更新 | 仅对 Dataflow、Vertex AI 和 PSH 有残留影响 |
| 17:10 | 谷歌更新 | 除 us-central1 外,数据流已完全解决 |
| 17:33 | 谷歌更新 | 个性化服务对健康的影响已解决 |
| 18:18 | 谷歌最终版 | Vertex AI 在线预测已完全恢复,一切正常 |
| 18:27 | 谷歌事后分析 | 内部调查正在进行中,后续将进行分析。 |
2. Google Cloud 内部出了什么问题
GCP 的身份和访问管理 (IAM)是所有 API 调用必须经过的入口。当颁发和验证 OAuth 及服务帐户令牌的系统出现故障时,其影响范围会波及存储、计算、控制平面,几乎涵盖所有层面。
 图 1:第一小时内的 GCP 状态页面
图 1:第一小时内的 GCP 状态页面
2.1 疑似触发因素
- Google 的初步事件摘要提到了一个 IAM 后端部署问题,表明对 IAM 服务的例行更新引入了一个错误,该错误在标准金丝雀测试能够发现之前就已经传播开来。
- 据报道,谷歌内部工程师回滚了二进制文件并清除了错误配置,然后强制刷新了所有区域的令牌缓存。由于 us-central1 区域托管着 IAM 元数据的仲裁分片,因此刷新速度较慢。
2.2 客户影响清单

- 云存储:对已签名 URL 获取数据时出现 403 和 500 错误
- Cloud SQL 和 Bigtable:连接打开时出现身份验证失败
- 工作区:Gmail、日历、Meet 偶尔使用 503
- Vertex AI、Dialogflow、Apigee:延迟升高,然后流量下降
🚀试试 AI Shell
您的智能编码助手,可无缝集成到您的工作流程中。
登录 Forge →
3. Cloudflare 的依赖链式反应
Cloudflare 的 Workers KV 存储数十亿条键值对记录,并将其复制到 270 多个边缘节点。热路径位于 Cloudflare 自身的数据中心,但持久化后端是一个托管在 Google Cloud 上的多区域数据库。当 IAM 拒绝新的令牌时,对后端存储的写入操作以及最终的读取操作都超时了。
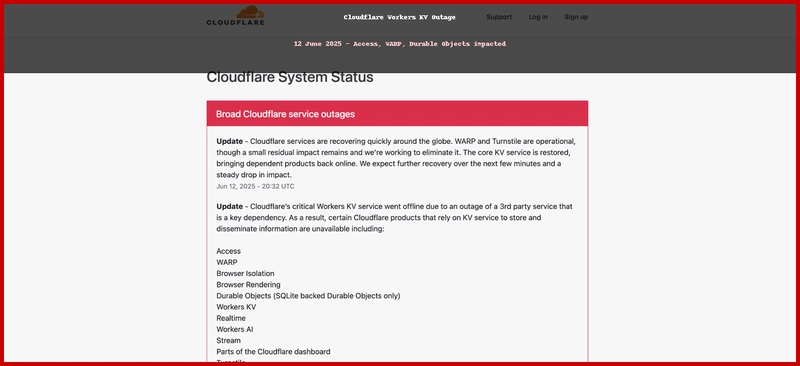 图 2:Cloudflare 状态摘录,突出显示 Access、KV 和 WARP 已降级
图 2:Cloudflare 状态摘录,突出显示 Access、KV 和 WARP 已降级
3.1 多米诺骨牌效应
- Cloudflare Access 使用键值存储会话状态 -> 登录循环
- WARP 将零信任设备姿态存储在键值对中 -> 客户端无法握手
- 持久对象(SQLite)依赖键值存储来存储元数据 -> 部分持久对象失败
- 由于 KV 中缺少模型清单,AI Gateway 和 Workers AI 出现了冷启动错误。
Cloudflare 的事件指挥官宣布此次事件的严重级别为橙色,并与 Google 工程师建立了跨厂商的桥梁。身份和访问管理 (IAM) 缓解措施生效后,KV 重新连接,边缘节点迅速自我修复。
4. 人类学陷入交火之中

Anthropic将 Claude 托管在 GCP 上。直接导致失败的模式是文件上传(访问云存储)和图像识别功能,而原始文本提示有时由于缓存令牌而成功。
[12:07 PT] status.anthropic.com: "We have disabled uploads to reduce error volume while the upstream GCP incident is in progress. Text queries remain available though elevated error rates persist."
Anthropic 限制了流量以保持服务的部分可用性,然后在 Google 的 IAM 集群稳定后恢复了上传。
5. 给工程师的启示

- 控制平面故障比数据平面故障危害更大。如果身份验证中断,跨区域数据复制也无法挽救您的损失。
- 检查隐藏的依赖项。Cloudflare 在边缘端支持多云,但在堆栈深处仍然选择了单一供应商,这导致了级联效应。
- 状态页面必须快速且真实。谷歌花了将近一个小时才将事件标记更改为“已解决”。在此期间,客户们一直在排查各种莫名其妙的问题。
- 设计一个紧急绕过方案。如果你的身份验证代理(Cloudflare Access)出现故障,你能否临时绕过它?
- 混乱演练仍然很重要。虽然罕见,但多方参与的事件时有发生,因此必须预先演练应对方案。
🚀试试 AI Shell
您的智能编码助手,可无缝集成到您的工作流程中。
登录 Forge →
6. 仍在等待完整的RCA(根目录和目录)

谷歌将在内部审查结束后发布事后分析报告,预计会详细说明此次故障部署的详情、影响范围以及计划采取的防护措施。Cloudflare
通常会在一周内发布一篇分析博客文章。请关注其中关于 Workers 键值架构和新增冗余层的具体信息。
 图 3:每个 SRE 连续两小时都在做什么——刷新、挥汗、重复
图 3:每个 SRE 连续两小时都在做什么——刷新、挥汗、重复
7. 最新分析:谷歌官方时间线告诉我们什么
谷歌公布的详细事件时间线揭示了几个从外部监控中无法看到的重要细节:
7.1 根本原因识别
- 太平洋时间12:41:谷歌工程师已确定根本原因并采取缓解措施
- 太平洋时间13:16:除美国中部地区1外,所有地区的基础设施均已恢复。
- 太平洋时间 14:00:已对 us-central1 和 multi-region/us 实施缓解措施
us-central1 明显落后于其他地区,这表明该地区拥有关键的基础设施组件,需要在恢复操作期间进行特殊处理。
7.2 分阶段恢复模式
- 基础设施层(12:41-13:16):除一个区域外,底层依赖项已在全球范围内修复
- 产品层(13:45):大部分 GCP 产品已恢复,但仍有一些残留影响。
- 专业服务(17:10-18:18):像数据流和顶点人工智能这样的复杂服务需要额外时间。
7.3 长尾效应
即使根本原因已修复,某些服务仍需额外 5 个多小时才能完全恢复:
- 数据流:us-central1 区域的积压数据清理工作将于太平洋时间 17:10 结束。
- Vertex AI:模型花园 5xx 错误持续到太平洋夏令时 18:18。
- 个性化服务健康状况:更新延迟至太平洋夏令时间 17:33
这表明,连锁故障造成的恢复债务远远超出了最初的修复范围。

8. 总结
上午 10:50,谷歌云服务中的一个漏洞导致全球身份验证系统瘫痪。半小时内,该故障蔓延至 Cloudflare 和 Anthropic。下午 1:30 一切恢复正常,但在此之前,它再次提醒了互联网,我们的依赖关系有多么错综复杂。
密切关注官方的根本原因分析报告 (RCA)。同时,更新您的事件处理手册,测试故障转移方案,并记住,有时云环境最大的风险可能只是周二的一个错误配置。
请在下方评论区告诉我你的看法!
文章来源:https://dev.to/forgecode/when-google-sneezes-the-whole-world-catches-a-coldthe-full-story-inside-3ep